R или Python для машинного обучения. Создание машинно-обучаемого классификатора с помощью Scikit-learn в Python
Разработка приложений для категоризации лент RSS при помощи Python, NLTK и машинного обучения
Знакомимся с Python
Эта статья предназначена для разработчиков ПО — особенно имеющих опыт работы с языками Ruby или Java, — которые впервые сталкиваются с машинным обучением.
Задача: Использование машинного обучения для категоризации лент RSS
Недавно мне поручили создать систему категоризации лент RSS для одного из клиентов. Задача состояла в том, чтобы читать десятки и даже сотни сообщений в лентах RSS и автоматическом относить их к одной из десятков предварительно определенных тематик. От ежедневных результатов работы этой системы категоризации и получения новостей должны были зависеть наполнение контентом, навигация и возможности поиска на веб-сайте клиента.
Представительница заказчика предложила использовать машинное обучение, возможно на базе Apache Mahout и Hadoop, так как недавно читала об этих технологиях. Однако разработчики как из ее, так и из нашей команды имели больше опыта работы с Ruby, а не с Java™. В этой статье я рассказываю обо всех технических изысканиях, процессе обучения и, наконец, об итоговой реализации решения.
Что такое машинное обучение?
Мой первый вопрос в данном проекте звучал так: "Что такое машинное обучение на самом деле?". Я слышал этот термин и знал, что суперкомпьютер IBM® Watson недавно победил реальных людей в игру Jeopardy. Как покупатель интернет-магазинов и участник социальных сетей я также понимал, что Amazon.com и Facebook прекрасно справляются с задачей подбора рекомендаций (продуктов или людей) на основании данных о своих покупателях. Если говорить кратко, машинное обучение лежит на пересечении ИТ, математики и естественного языка. В основном этот процесс связан с тремя перечисленными ниже аспектами, но решение для нашего клиента было основано на первых двух:
- Классификация. Отнесение элементов к предварительно объявленным категориям исходя из тренировочных данных для аналогичных элементов.
- Рекомендация. Выбор рекомендованных элементов исходя из наблюдений за выбором аналогичных элементов
- Кластеризация. Выявление подгрупп в массиве данных
Неудачная попытка — Mahout и Ruby
Разобравшись в том, что представляет собой машинное обучение, мы перешли к следующему шагу — поиску способов реализации. По предположению клиента, хорошей отправной точкой мог бы стать Mahout. Я загрузил код с сервера Apache и начал изучать процесс машинного обучения в Mahout и в Hadoop. К сожалению, я обнаружил, что Mahout сложен в изучении даже для опытного разработчика на Java и не имеет работающих примеров кода. Не меньше огорчило ограниченное количество инфраструктур и gem-пакетов для машинного обучения на Ruby.
Находка — Python и NLTK
Я продолжил искать решение; в результатах поиска постоянно обнаруживались упоминания Python. Как приверженец Ruby, я знал, что Python является динамическим языком программирования и использует такую же объектно-ориентированную текстовую модель интерпретации, хотя никогда не изучал этот язык. Несмотря на эти сходства, я много лет уклонялся от изучения Python, считая его лишним знанием. Таким образом, Python был моим "слепым пятном", и я подозреваю, что такая же картина наблюдается у многих коллег-программистов на Ruby.
Поиск книг по машинному обучению и детальное изучение их содержания показали, что значительная часть подобных систем реализуется на Python в сочетании с библиотекой для работ с естественными языками Natural Language Toolkit (NLTK). Дальнейшие поиски позволили выяснить, что Python используется гораздо чаще, чем я думал, например, в движке Google App, на YouTube, а также на веб-сайтах, использующих Django. Оказывается, он изначально установлен на рабочих станциях Mac OS X, с которыми я ежедневно работаю! Более того, Python обладает интересными стандартными библиотеками (например, NumPy и SciPy) для математических расчетов, научных изысканий и инженерных решений. Кто же мог знать?
Обнаружив элегантные примеры кода, я решил использовать решение на Python. Например, приведенный ниже однострочный код делает все необходимое для получения RSS-новости по протоколу HTTP и печати ее содержимого:
print feedparser.parse("http://feeds.nytimes.com/nyt/rss/Technology")Продвигаемся к цели вместе с Python
При изучении нового языка программирования самой простой частью является обучение самому языку. Более сложный процесс — изучение экосистемы. Нужно разобраться, как его устанавливать, как добавлять библиотеки, писать код, структурировать файлы, запускать, отлаживать и подготавливать тесты. В этой части мы приводим краткое введение в данные разделы; не забудьте просмотреть ссылки из раздела — там может быть много полезной информации.
pip
Python Package Index (pip) — стандартный менеджер пакетов в Python. Это именно та программа, которую вы будете использовать для добавления библиотек в вашу систему. Он аналогичен gem для библиотек Ruby. Чтобы добавить библиотеку NLTK в вашу систему, вам нужно выполнить следующую команду:
$ pip install nltkЧтобы отобразить перечень библиотек Python, установленных в вашей системе, используйте команду:
$ pip freezeЗапуск программ
Запуск программ на Python происходит так же просто. Если у вас есть программа locomotive_main.py , принимающая три аргумента, вы можете скомпилировать и запустить выполнение кода при помощи следующей команды на python:
$ python locomotive_main.py arg1 arg2 arg3Синтаксис if __name__ == "__main__" , приведенный в , используется в языке Python для того, чтобы определить, запущен ли файл отдельно из командной строки или же вызван другим фрагментом кода. Чтобы сделать программу выполняемой, добавьте в нее проверку на "__main__" .
Листинг 1. Проверка статуса Main
import sys import time import locomotive if __name__ == "__main__": start_time = time.time() if len(sys.argv) > 1: app = locomotive.app.Application() ... дополнительная логика...virtualenv
Многие программисты на Ruby знакомы с проблемой общих системных библиотек, также называемых gem. Применение общесистемных наборов библиотек, как правило, нежелательно, поскольку один из ваших проектов может полагаться на версию 1.0.0 имеющейся библиотеки, а другой — на версию 1.2.7. Разработчики на Java сталкиваются с подобной проблемой в случае общесистемной переменной CLASSPATH. Подобно инструменту rvm в Ruby, в Python используется инструмент virtualenv (см. ссылку в разделе ), создающий отдельные среды исполнения программ, включая специальные инструкции Python и наборы библиотек. Команды в показывают, как создать виртуальную среду исполнения с именем p1_env для вашего проекта p1 , в состав которого будут входить библиотеки feedparser , numpy , scipy и nltk .
Листинг 2. Создание виртуальной среды исполнения с помощью virualenv
$ sudo pip install virtualenv $ cd ~ $ mkdir p1 $ cd p1 $ virtualenv p1_env --distribute $ source p1_env/bin/activate (p1_env)[~/p1]$ pip install feedparser (p1_env)[~/p1]$ pip install numpy (p1_env)[~/p1]$ pip install scipy (p1_env)[~/p1]$ pip install nltk (p1_env)[~/p1]$ pip freezeСкрипт для активации вашей виртуальной среды необходимо запускать каждый раз, когда вы работаете с вашим проектом в окне оболочки. Обратите внимание на то, что после исполнения скрипта активации меняется командное приглашение оболочки. Для удобства перехода к каталогу вашего проекта и активации виртуальной среды после создания окна оболочки в вашей системе полезно добавить в файл ~/.bash_profile запись наподобие следующей:
$ alias p1="cd ~/p1 ; source p1_env/bin/activate"Базовая структура кода
Освоив простые программы уровня "Hello World", разработчику на Python необходимо научиться правильно структурировать код с учетом каталогов и имен файлов. Как и в Java или Ruby, в Python есть для этого свои правила. Если говорить коротко, Python использует для группировки связанного кода концепцию пакетов и использует однозначно определенные пространства имен. В целях демонстрации в данной статье код размещается в корневом каталоге проекта, например, ~/p1. В нем имеется подкаталог locomotive, содержащий одноименный Python- пакет. Эта структура каталогов показана в.
Листинг 3. Пример структуры каталогов
locomotive_main.py locomotive_tests.py locomotive/ __init__.py app.py capture.py category_associations.py classify.py news.py recommend.py rss.py locomotive_tests/ __init__.py app_test.py category_associations_test.py feed_item_test.pyc rss_item_test.pyОбратите внимание на файлы со странным названием __init__.py . В этих файлах содержатся инструкции Python для подгрузки необходимых библиотек к вашей среде, а также к вашим специальным приложениям, которые находятся в том же каталоге. В приведено содержимое файла locomotive/__init__.py.
Листинг 4. locomotive/__init__.py
# импорт системных компонентов; загрузка установленных компонентов import codecs import locale import sys # импорт компонентов приложения; загрузка пользовательских файлов *.py import app import capture import category_associations import classify import rss import news import recommendПри структуре пакета locomotive , показанной в , основные программы из корневого каталога вашего проекта могут импортировать и использовать его. Например, файл locomotive_main.py содержит следующие команды импорта:
import sys # >-- системная библиотека import time # >-- системная библиотека import locomotive # >-- пользовательская библиотека прикладного кода # из каталога "locomotive"Тестирование
Стандартная Python-библиотека unittest предоставляет удобные ресурсы для тестирования. Разработчики на Java, знакомые с JUnit, а также специалисты по Ruby, работающие с инфраструктурой Test::Unit, легко поймут код Python unittest из .
Листинг 5. Python unittest
class AppTest(unittest.TestCase): def setUp(self): self.app = locomotive.app.Application() def tearDown(self): pass def test_development_feeds_list(self): feeds_list = self.app.development_feeds_list() self.assertTrue(len(feeds_list) == 15) self.assertTrue("feed://news.yahoo.com/rss/stock-markets" in feeds_list)Содержимое также демонстрирует отличительную черту Python: для успешной компиляции код должен иметь единообразно установленные отступы. Метод tearDown(self) может показаться странным - зачем в коде теста запрограммирован успешный результат прохождения? На самом деле в этом нет ничего страшного. Таким образом в Python можно запрограммировать пустой метод.
Инструменты
Что мне действительно было необходимо — так это интегрированная среда разработки (IDE) с подсветкой синтаксиса, завершением кода и возможностью исполнения с контрольными точками, чтобы освоиться в Python. Как пользователь Eclipse IDE для Java, я первым делом обратил внимание на pyeclipse . Этот модуль работает достаточно неплохо, но иногда - очень медленно. В конце концов я выбрал IDE PyCharm, которая удовлетворила все мои требования.
Итак, вооружившись базовыми знаниями о Python и его экосистеме, я, наконец, был готов к реализации машинного обучения.
Реализация категорий на Python и NLTK
Для построения решения мне нужно было обрабатывать имитационные ленты новостей RSS, анализировать их текст при помощи NaiveBayesClassifier , а затем классифицировать их по категориям посредством алгоритму kNN. Каждое из этих действий описано в данной статье.
Извлечение и обработка лент новостей
Одна из сложностей проекта состояла в том, что клиент еще не определил перечень целевых лент новостей RSS. Также не было и «данных для обучения». Поэтому ленты новостей и тренировочные данные на начальном этапе разработки приходилось имитировать.
Первый способ получения образцов данных лент новостей, который я использовал, состоял в том, чтобы сохранить содержимое списка лент RSS в текстовом файле. В Python есть очень неплохая библиотека для обработки лент RSS под названием feedparser , которая позволяет скрыть различия между различными форматами RSS и Atom. Еще одна полезная библиотека для сериализации простых текстовых объектов шутливо названа pickle («маринад»). Обе библиотеки используются в коде из , который сохраняет каждую ленту RSS в "замаринованном" виде для дальнейшего использования. Как вы можете видеть, программный код на Python является лаконичным и мощным.
Листинг 6. Класс CaptureFeeds
import feedparser import pickle class CaptureFeeds: def __init__(self): for (i, url) in enumerate(self.rss_feeds_list()): self.capture_as_pickled_feed(url.strip(), i) def rss_feeds_list(self): f = open("feeds_list.txt", "r") list = f.readlines() f.close return list def capture_as_pickled_feed(self, url, feed_index): feed = feedparser.parse(url) f = open("data/feed_" + str(feed_index) + ".pkl", "w") pickle.dump(feed, f) f.close() if __name__ == "__main__": cf = CaptureFeeds()Следующий шаг оказался неожиданно трудоемким. После получения образца данных лент мне необходимо было категоризовать его для последующего использования в качестве тренировочных данных. Тренировочные данные — это именно тот набор информации, который вы предоставляете своему алгоритму категоризации в качестве ресурса для обучения.
Например, среди образцов лент, которые я использовал, был канал спортивных новостей ESPN. Одно из сообщений повествовало о том, что Тим Тэбоу (Tebow) из футбольной команды Denver Broncos был куплен New York Jets, а в то же время Broncos подписали контракт с Пейтоном Мэннингом (Manning), который стал их новым полузащитником (quarterback). Другое сообщение касалось компании Boeing и ее нового реактивного авиалайнера (англ. jet). Возникает вопрос: к какой категории следует отнести первую историю? Прекрасно подходят слова tebow , broncos , manning , jets , quarterback , trade и nfl . Но для указания категории обучающих данных нужно выбрать всего одно слово. То же самое можно сказать и про вторую историю — что выбрать, boeing или jet ? Вся сложность работы состояла именно в этих деталях. Тщательное ручное категорирование большого количества обучающих данных просто необходимо, если вы хотите, чтобы ваш алгоритм выдавал точные результаты. И время, которое придется потратить на это, нельзя недооценивать.
Скоро стало очевидно, что мне нужны еще данные для работы, причем они уже должны быть разбиты по категориям — и достаточно точно. Где искать такие данные? И тут на сцену выходит Python NLTK. Помимо того, что это великолепная библиотека для обработки текстов на естественных языках, к ней прилагаются готовые загружаемые наборы исходных данных, т.н. «корпуса», а также программные интерфейсы для удобного доступа к этим данным. Чтобы установить корпус Reuters, вам нужно выполнить приведенные ниже команды, и в ваш каталог ~/nltk_data/corpora/reuters/ будет загружено более 10 000 новостных сообщений. Как и элементы ленты RSS, каждая новостная статья Reuters содержит заголовок и основную часть, поэтому категорированные данные NLTK идеально подходят для имитации лент новостей RSS.
$ python # входим в интерактивную оболочку Python >>> import nltk # импортируем библиотеку nltk >>> nltk.download() # запускаем загрузчик NLTK и вводим "d" Identifier> reuters # указываем корпус "reuters"Особый интерес представляет файл ~/nltk_data/corpora/reuters/cats.txt. В нем содержится перечень имен файлов с заметками, а также категории, назначенные каждому из файлов. Следующие записи обозначают, что файл 14828 в подкаталоге test отнесен к теме grain .
test/14826 trade test/14828 grainЕстественный язык — это сложно
Сырьем для нашего алгоритма категорирования RSS-материалов, разумеется, являются простые тексты на английском языке. Термин «сырье» здесь весьма уместен.
Английский, как и любой другой естественный язык (язык повседневного общения) отличается чрезвычайной неоднородностью и непоследовательностью с точки зрения компьютерной обработки. Первым делом возникает вопрос с регистром. Можно ли считать слово Bronco равным bronco ? Ответ будет: «возможно». Также важны пунктуация и пробелы. Можно ли сравнивать bronco. с bronco или bronco ,? Вроде бы да. Далее, существуют формы множественного числа и схожие слова. Можно ли считать run , running и ran эквивалентными формами? Зависит от ситуации. Эти три слова являются однокоренными. А что если слова из естественного языка также сопровождаются тегами HTML? В этом случае вам придется работать с такими элементами, как bronco . Наконец, существует проблема часто используемых, но фактически ничего не значащих слов, таких как артикли, союзы и предлоги. Эти так называемые вспомогательные слова усложняют обработку. Таким образом, естественный язык весьма беспорядочен и требует очистки перед началом работы.
К счастью, Python и NLTK позволяют вам легко избавиться от этого мусора. Метод normalized_words из класса RssItem в , позволяет исключить все эти препятствия. В частности, обратите внимание, как NLTK очищает сырой текст статьи от встроенных тегов HTML при помощи всего одной строчки кода! Кроме того, с помощью регулярного выражения выполняется удаление пунктуации, после чего текст делится на слова и переводится в нижний регистр.
Листинг 7. Класс RssItem
class RssItem: ... regex = re.compile("[%s]" % re.escape(string.punctuation)) ... def normalized_words(self, article_text): words = oneline = article_text.replace("\n", " ") cleaned = nltk.clean_html(oneline.strip()) toks1 = cleaned.split() for t1 in toks1: translated = self.regex.sub("", t1) toks2 = translated.split() for t2 in toks2: t2s = t2.strip().lower() if self.stop_words.has_key(t2s): pass else: words.append(t2s) return wordsПеречень вспомогательных слов берется из NLTK одной командой; поддерживаются и другие естественные языки.
nltk.corpus.stopwords.words("english")NLTK также предоставляет несколько классов морфологического анализа для дальнейшей нормализации слов. Подробнее о морфологическом анализе, лемматизации, анализе структуры предложений и грамматике можно узнать в документации NLTK.
Классификация по простому байесовскому алгоритму
Алгоритм Naive Bayes (простой байесовский алгоритм) широко известен и встроен в NLTK в виде класса nltk.NaiveBayesClassifier . Байесовский алгоритм позволяет классифицировать элементы по факту наличия или отсутствия определенных элементов в их составе. В случае с лентами RSS в качестве элементов используются определенные (очищенные) слова естественного языка. Алгоритм является "простым" в том смысле, что не подразумевает взаимосвязей между элементами (в нашем случае словами).
Однако в английском языке имеется более 250 000 слов. Безусловно, я не хотел бы создавать объект с 250 000 логических значений для каждой ленты RSS, чтобы реализовать алгоритм. Итак, какие слова использовать? Если говорить кратко, это должны быть наиболее часто встречающиеся слова из тестовых данных, которые не являются вспомогательными. В NLTK имеется очень удобный класс nltk.probability.FreqDist , который позволяет выявить эти популярные слова. А приведенный в , метод collect_all_words возвращает массив, содержащий все слова из всех тренировочных заметок.
Далее этот массив обрабатывается методом identify_top_words , который возвращает наиболее часто встречающиеся слова. Удобная функция класса nltk.FreqDist фактически создает хэш, но его ключи оказываются отсортированными согласно соответствующим значениям (количеству вхождений). Таким образом, можно легко выделить 1000 самых часто встречающихся слов, указав диапазон индексов [:1000] в соответствии с синтаксисом Python.
Листинг 8. Использование класса nltk.FreqDist
def collect_all_words(self, items): all_words = for item in items: for w in item.all_words: words.append(w) return all_words def identify_top_words(self, all_words): freq_dist = nltk.FreqDist(w.lower() for w in all_words) return freq_dist.keys()[:1000]Для имитации лент RSS на базе данных NLTK из статей Reuters мне нужно было выделить категории для каждой из них. Я сделал это, читая файл ~/nltk_data/corpora/reuters/cats.txt, о котором я уже говорил ранее. Чтение файла на Python происходит просто:
def read_reuters_metadata(self, cats_file): f = open(cats_file, "r") lines = f.readlines() f.close() return linesСледующий шаг — получение характеристик каждого сообщения из ленты RSS. Это действие выполняет метод features из класса RssItem, продемонстрированный ниже. При работе данного метода массив всех слов (all_words) статьи сначала сокращается до меньшего по размерам набора уникальных слов (set) за счет устранения дубликатов слов. Далее выполняется проход по списку наиболее распространенных слов top_words и проверка их наличия или отсутствия в статье. В результате мы получаем хэш из 1000 логических значений, ключами которого являются сами слова с префиксом w_ . Соответствующий код на Python весьма краток.
def features(self, top_words): word_set = set(self.all_words) features = {} for w in top_words: features["w_%s" % w] = (w in word_set) return featuresДалее я собираю тренировочный набор сообщений RSS и их индивидуальных характеристик и передаю их на обработку алгоритму. Код из демонстрирует выполнение этой задачи. Обратите внимание, что обучение классификатора занимает ровно одну строчку кода.
Листинг 9. Обучение nltk.NaiveBayesClassifier
def classify_reuters(self): ... training_set = for item in rss_items: features = item.features(top_words) tup = (features, item.category) # tup is a 2-element tuple featuresets.append(tup) classifier = nltk.NaiveBayesClassifier.train(training_set)Итак, классификатор NaiveBayesClassifier , находящийся в памяти работающей программы Python, обучен. Теперь я могу просто пройти по списку лент RSS, которые нужно классифицировать, и определить с помощью классификатора категорию для каждого из элементов. Очень просто.
for item in rss_items_to_classify: features = item.features(top_words) category = classifier.classify(feat)Менее простая классификация
Как уже говорилось ранее, наш алгоритм не подразумевает наличия взаимосвязей между индивидуальными параметрами. Таким образом, фразы типа "machine learning" и "learning machine" либо "New York Jet" и "jet to New York" являются эквивалентами (предлог «to» исключается как вспомогательное слово). В естественном же языке между этими словами имеются очевидные связи. Как сделать алгоритм менее «простым» и научить его распознавать эти взаимосвязи между словами?
Один из методов — включить в набор параметров распространенные словосочетания из двух (биграммы ) и трех слов (триграммы ). И мы уже не удивляемся тому, что в NLTK имеется поддержка этих возможностей в виде функций nltk.bigrams(...) и nltk.trigrams(...) . Точно также как библиотека выбирала из всего набора данных N самых часто встречающихся слов, она может идентифицировать самые популярные двух- и трехсловные словосочетания и использовать их в качестве параметров.
Ваши результаты могут быть другими
Очистка данных и применение алгоритма — это своего рода искусство. Стоит ли нормализовать набор слов еще сильнее, например, выделяя корни? Или нужно включить в набор более чем 1000 самых частых слов? Или меньше? Или, может быть, нужно использовать более объемный набор данных для обучения? Или определить больше слов как вспомогательные? Все эти вопросы вы можете задать самим себе. Экспериментируйте с ними, пробуйте, проходите через ошибки, и вы сможете создать лучший алгоритм для ваших данных. Я решил для себя, что 85% — это хороший уровень успешной категоризации.
Клиент хотел отображать элементы ленты RSS в выбранной категории или в связанных категориях. Теперь, когда данные были категоризованы при помощи простого байесовского алгоритма, первая часть требований заказчика была выполнена. Более сложной оказалась задача определения «связанных категорий». В этом случае нужно использовать системы рекомендаций на основе алгоритмов машинного обучения. Система рекомендаций основывается на схожести одних элементов с другими. Хорошими примерами таких функций являются рекомендации продуктов на Amazon.com и рекомендации друзей в Facebook.
Наиболее популярным алгоритмом для построения рекомендаций является алгоритм k-Nearest Neighbors (kNN, k ближайших соседей). Идея состоит в том, чтобы создать перечень меток (категорий) и сопоставить каждой метке набор данных. Далее алгоритм сравнивает наборы данных, выявляя совпадающие элементы. Набор данных представлен набором численных значений, обычно приведенных к нормализованному виду — от 0 до 1. Затем можно выделять похожие метки на основании наборов данных. В отличие от простого алгоритма Байеса, который дает один результат, kNN может выдать целый перечень рекомендаций со степенями совпадения (определяется значением k).
Алгоритмы рекомендации показались мне более простыми для понимания и реализации, чем алгоритмы классификации, хотя сам код оказался более длинным и слишком сложным с математической точки зрения, чтобы приводить его здесь. Примеры кода для kNN можно найти в великолепной новой книге издательства Manning «Machine Learning in Action (см. ссылку в разделе ). В нашем случае с обработкой лент RSS значения меток совпадали с категориями, а наборы данных представляли собой массивы значений для 1000 самых популярных слов. Еще раз повторюсь, что создание такого массива — это частично наука, частично математика и частично искусство. Для каждого слова в массиве значение может представлять собой булеву величину (0 или 1), частоту встречаемости слова в процентах, экспоненциальное выражение от частоты или другую величину.
Заключение
Знакомство с Python, NLTK и машинным обучением оказалось интересным и приятным. Python — это мощный и лаконичный язык программирования, который теперь стал одной из основных частей моего инструментария разработчика. Он прекрасно подходит для реализации машинного обучения, обработки естественного языка и математических и научных приложений. Кроме того, хотя я не упомянул этого в данной статье, он показался мне полезным для создания диаграмм и графиков. И если у вас Python также находился «в слепой зоне», я советую вам познакомиться с ним.
Всем привет!
В этой статье я расскажу о новом комфортном способе программировать на Python.
Это больше похоже не на программирование, а на создание статей (отчетов/демонстраций/исследований/примеров): среди блоков кода на Python можно вставлять обычный поясняющий текст. Результатом выполнения кода является не только числа и текст (как в случае с консолью при стандартной работе с Python), но еще и графики, диаграммы, картинки…
Примеры документов, которые вы сможете создавать:
Выглядит классно? Хотите создавать такие же документы? Тогда данная статья для вас!
Сначала необходимо установить пакет Anaconda. Что это такое? Это полностью настроенный Python вместе с предустановленным комплектом самых популярных модулей. Anaconda также включает среду JupyterLab, в которой мы и будем создавать документы с Python кодом.
Если Python у вас уже установлен, то сначала удалите его. Сделать это можно через панель «Программы и компоненты» в «Панели управления».
Скачивание

Скачивайте Anaconda для Python 3.6 (Windows 7 и выше) или для Python 2.7 (Windows XP).
Установочный файл весит 500+ MB, так что закачиваться он может достаточно долго.
Установка
Запустите скачанный файл. Откроется окно установщика. На первых двух страницах сразу кликайте «Next». Далее можно выбрать, установить Anaconda только для текущего пользователя компьютера, или для всех.

Важно! В следующем окне нужно указать путь, по которому будет установлена Anaconda. Выбирайте путь, который не содержит папок с пробелами в названии (например, Program Files) и не содержит не английских символов юникода (например, русских букв)!
Игнорирование этих правил может привести к проблемам при работе с разными модулями!
Лично я создал папку Anaconda прямо в корне диска C и указал следующий путь:

На последнем окне будут две галочки. Оставьте все, как есть.
Наконец, начнется установка. Она может занять ~10 минут. Можете спокойно выпить чаю 🙂

Anaconda Navigator
После успешной установки Anaconda запустите программу Anaconda Navigator из меню Пуск. При запуске вы должны увидеть вот этот логотип:
![]()
Затем откроется и сам навигатор. Это отправная точка для работы с Anaconda.

В центральной части окна расположены различные программы, которые входят в пакет Anaconda. Часть их них уже установлена.
В основном мы будем пользоваться «jupyterlab»: именно в ней и создаются красивые документы.
В левой части приведены разделы навигатора. По умолчанию открыт раздел «Home». В разделе «Environments» можно включать/отключать/загружать дополнительные модули Python с помощью удобного интерфейса.
JupyterLab
В разделе навигатора «Home» запустите (кнопка «Launch») программу «jupyterlab» (самая первая в списке).
У вас должен открыться браузер по умолчанию со средой JupyterLab в отдельной вкладке.

Слева отображается содержимое папки C:\Users\<ИМЯ_ВАШЕЙ_УЧЕТНОЙ_ЗАПИСИ> .
Справа открыт файл блокнота «untitled.ipynb». Если справа ничего нет, то вы можете создать новый пустой блокнот, нажав на «+» в левом верхнем углу и выбрав «Notebook Python 3»:

Блокнот
Самое время разобраться с тем, что из себя представляют блокноты.
Обычно мы пишем Python код в файлах с расширением.py , а затем интерпретатор Python их выполняет и выводит данные в консоль. Для удобной работы с такими файлами часто используют среды программирования (IDE). К их числу относится и PyCharm, о котором я рассказывал в статье .
Но есть и другой подход. Он заключается в создании блокнотов (notebook) с расширением ipynb . Блокноты состоят из большого количества блоков. Есть блоки с простым текстом, а есть блоки с кодом на Python.
Попробуйте ввести в первый блок в блокноте какой-нибудь Python код. Например, я создаю переменную, равную сумме чисел 3 и 2:
На следующей строке мы просто пишем название этой переменной. Зачем? Сейчас увидите.
Теперь нужно выполнить этот блок. Для этого нажмите на значок треугольника в панели инструментов над блокнотом или комбинацию клавиш Ctrl + Enter:
Под блоком с Python кодом появился еще один блок, который содержит вывод результатов выполнения предыдущего блока. Сейчас вывод содержит число 5. Это число выводит как раз вторая строчка написанного нами блока.
В обычных средах программирования для достижения такого эффекта нам пришлось бы писать print(a) , а тут вызов этой функции можно опустить и просто написать название переменной, которую мы хотим вывести.
Но выводить значения (числа и текст) переменных (пусть и через функцию) можно и в других средах программирования.
Попробуем сделать что-нибудь посложнее. Например, вывести какую-нибудь картинку.
Создайте новый блок с помощью кнопки в панели инструментов над блокнотом.
В это блоке мы закачиваем логотип Anaconda из сайта Wikimedia и выводим его:
From PIL import Image import requests image_url = "https://upload.wikimedia.org/wikipedia/en/c/cd/Anaconda_Logo.png" im = Image.open(requests.get(image_url, stream=True).raw) im
Результат будет выглядеть так:

Вот на такое обычные среды разработки не способны. А в JupyterLab - запросто!
Теперь давайте попробуем добавить блок с обычным текстом между двумя уже созданными блоками с Python кодом. Для этого щелчком выделите первый блок и добавьте новый блок через кнопку в панели инструментов. Новый блок будет вставлен сразу за первым блоком.
Если вы все сделали правильно, то результат будет выглядеть так:

По умолчанию блоки в JupyterLab предназначены для кода на Python. Для того, чтобы превратить их в текстовые блоки, нужно сменить их тип через панель инструментов. В самом конце панели откройте список и выберите пункт «Markdown»:

Выделенный блок превратится в блок текста. Набранный текст можно оформить курсивом или сделать его жирным . Больше информации по Markdown (средства оформления текста) вы найдете .
Вот так можно оформлять текстовые блоки блокнота:

Экспорт
В JupyterLab можно экспортировать блокнот в самые разные форматы. Для этого в самом верху среды выберите вкладку «Notebook». В открывшемся меню выберите пункт «Export to…» и выберите формат (например, PDF), в который вы хотите преобразовать ваш блокнот.

Вот ссылка на gist с блокнотом из этой статьи.

Управление модулями Python
Включать/отключать/закачивать модули можно из Anaconda Navigator. Для этого в левом меню выберите пункт «Environments»:

По умолчанию отображается список установленных модулей (~217 штук). Среди них есть и такие популярные, как numpy (работа с массивами) или scypi (научные и инженерные расчеты).
Для установки новых пакетов в выпадающем меню над таблицей (там, где написано «Installed») выберите пункт «Not installed»:

Список обновится - автоматически загрузится список неустановленных модулей.
Проставьте галочки рядом с теми модулями, которые хотите загрузить, а затем нажмите на кнопку «Apply» в правом нижнем углу для их загрузки и установки. По завершении процесса вы сможете использовать данные модули в блокнотах.
Выводы
Вы сможете сконцентрироваться на написании алгоритма и немедленной визуализации результатов исполнения кода, вместо того, чтобы возиться со сложными средами для программирования больших программ и консолью, которая может выводить только числа и текст.
Александр Крот, студент ФИВТ МФТИ, мой хороший товарищ и, в недавнем, коллега, запустил цикл статей о практических инструментах интеллектуального анализа больших данных и машинного обучения (Data mining и machine learning).
Уже опубликовано 3 статьи, надеюсь, что дальше будет больше:
1) Введение в машинное обучение с помощью Python и Scikit-Learn
2) Искусство Feature Engineering в машинном обучении
3) Когда данных действительно много: Vowpal Wabbit
В опубликованных статьях делается акцент на практических аспектах работы с инструментами для автоматического анализа данных и с алгоритмами, которые позволяют подготовить данные к эффективному машинному анализу. В частности, приведены примеры кода на языке Python (кстати, именно на Пайтоне мы недавно ) со специализированной библиотекой Scikit-Learn, которые можно быстренько запустить на домашнем компьютере или персональном облаке, чтобы почувствовать вкус больших данных самостоятельно.
Недавно я размышлял о том, как . Знакомство с приведенными инструментами позволит теперь провести практические эксперименты в этом направлении (программу на Пайтоне, кстати, можно запустить и на встроенном в контроллер Линуксе, но вот примеры с перемалыванием гигабайтов данных мобильный процессор навряд ли потянет). И еще кстати, Скала тоже пользуется уважением в среде инженеров, работающих с большими данными , интегрировать такой код будет еще проще.
Традиционно, виртуозное владение любыми инструментами не избавляет от необходимости поиска хорошей задачи, которая с их помощью эффективно решается (если, конечно, вам эту задачу не ставит кто-то другой). Но пространство дополнительных возможностей открывает. В моем представлении, это может выглядеть примерно так: робот (или группа роботов) собирает информацию с сенсоров, отправляет на сервер, где она накапливается и обрабатывается на предмет поиска закономерностей; далее алгоритм будет сверять найденные шаблоны с оперативными значениями сенсоров робота и будет отправлять ему предсказания о наиболее вероятном поведении окружающей среды. Или же на сервере заранее подготавливается база знаний о местности или об определенном типе местности (например, в виде характерных фотографий ландшафта и типичных объектов), а робот сможет использовать эти знания для планирования поведения в оперативной обстановке.
Первую статью утащу для затравки, остальное по ссылкам на Хабре:
Import numpy as np import urllib # url with dataset url = "http://archive.ics.uci.edu/ml/machine-learning-databases/pima-indians-diabetes/pima-indians-diabetes.data" # download the file raw_data = urllib.urlopen(url) # load the CSV file as a numpy matrix dataset = np.loadtxt(raw_data, delimiter="," ) # separate the data from the target attributes X = dataset[:,0 :7 ] y = dataset[:,8 ]
Нормализация данных
Всем хорошо знакомо, что большинство градиентных методов (на которых по-сути и основаны почти все алгоритмы машинного обучения) сильно чуствительны к шкалированию данных. Поэтому перед запуском алгоритмов чаще всего делается либо нормализация , либо так называемая стандартизация . Нормализация предполагает замену номинальных признаков так, чтобы каждый из них лежал в диапазоне от 0 до 1. Стандартизация же подразумевает такую предобработку данных, после которой каждый признак имеет среднее 0 и дисперсию 1. В Scikit-Learn уже есть готовые для этого функции:From sklearn import preprocessing # normalize the data attributes normalized_X = preprocessing.normalize(X) # standardize the data attributes standardized_X = preprocessing.scale(X)
Отбор признаков
Не секрет, что зачастую самым важным при решении задачи является умение правильно отобрать и даже создать признаки. В англоязычной литературе это называется Feature Selection и Feature Engineering . В то время как Future Engineering довольно творческий процесс и полагается больше на интуицию и экспертные знания, для Feature Selection есть уже большое количество готовых алгоритмов. «Древесные» алгоритмы допускают расчета информативности признаков:From sklearn import metrics from sklearn.ensemble import ExtraTreesClassifier model = ExtraTreesClassifier() model.fit(X, y) # display the relative importance of each attribute print(model.feature_importances_)
Все остальные методы так или иначе основаны на эффективном переборе подмножеств признаков с целью найти наилучшее подмножество, на которых построенная модель дает наилучшее качество. Одним из таких алгоритмов перебора является Recursive Feature Elimination алгоритм, который также доступен в библиотеке Scikit-Learn:
From sklearn.feature_selection import RFE from sklearn.linear_model import LogisticRegression model = LogisticRegression() # create the RFE model and select 3 attributes rfe = RFE(model, 3 ) rfe = rfe.fit(X, y) # summarize the selection of the attributes print(rfe.support_) print(rfe.ranking_)
Построение алгоритма
Как уже было отмечено, в Scikit-Learn реализованы все основные алгоритмы машинного обучения. Рассмотрим некоторые из них.Логистическая регрессия
Чаще всего используется для решения задач классификации (бинарной), но допускается и многоклассовая классификация (так называемый one-vs-all метод). Достоинством этого алгоритма являеся то, что на выходе для каждого обьекта мы имеем вероятсность принадлежности классуFrom sklearn import metrics from sklearn.linear_model import LogisticRegression model = LogisticRegression() model.fit(X, y) print(model) # make predictions expected = y predicted = model.predict(X)
Наивный Байес
Также является одним из самых известных алгоритмов машинного обучения, основной задачей которого является восстановление плотностей распределения данных обучающей выборки. Зачастую этот метод дает хорошее качество в задачах именно многоклассовой классификации.From sklearn import metrics from sklearn.naive_bayes import GaussianNB model = GaussianNB() model.fit(X, y) print(model) # make predictions expected = y predicted = model.predict(X) # summarize the fit of the model print(metrics.classification_report(expected, predicted)) print(metrics.confusion_matrix(expected, predicted))
K-ближайших соседей
Метод kNN (k-Nearest Neighbors) часто используется как составная часть более сложного алгоритма классификации. Например, его оценку можно использовать как признак для обьекта. А иногда, простой kNN на хорошо подобранных признаках дает отличное качество. При грамотной настройке параметров (в основном — метрики) алгоритм дает зачастую хорошее качество в задачах регрессииFrom sklearn import metrics from sklearn.neighbors import KNeighborsClassifier # fit a k-nearest neighbor model to the data model = KNeighborsClassifier() model.fit(X, y) print(model) # make predictions expected = y predicted = model.predict(X) # summarize the fit of the model print(metrics.classification_report(expected, predicted)) print(metrics.confusion_matrix(expected, predicted))
Деревья решений
Classification and Regression Trees (CART) часто используются в задачах, в которых обьекты имеют категориальные признаки и используется для задач регресии и классификации. Очень хорошо деревья подходят для многоклассовой классификацииFrom sklearn import metrics from sklearn.tree import DecisionTreeClassifier # fit a CART model to the data model = DecisionTreeClassifier() model.fit(X, y) print(model) # make predictions expected = y predicted = model.predict(X) # summarize the fit of the model print(metrics.classification_report(expected, predicted)) print(metrics.confusion_matrix(expected, predicted))
Метод опорных векторов
SVM (Support Vector Machines) является одним из самых известных алгоритмов машинного обучения, применяемых в основном для задачи классификации. Также как и логистическая регрессия, SVM допускает многоклассовую классификацию методом one-vs-all.From sklearn import metrics from sklearn.svm import SVC # fit a SVM model to the data model = SVC() model.fit(X, y) print(model) # make predictions expected = y predicted = model.predict(X) # summarize the fit of the model print(metrics.classification_report(expected, predicted)) print(metrics.confusion_matrix(expected, predicted))
Помимо алгоритмов классификации и регрессии, в Scikit-Learn имеется огромное количество более сложных алгоритмов, в том числе кластеризации, а также реализованные техники построения композиций алгоритмов, в том числе Bagging и Boosting .
Оптимизация параметров алгоритма
Одним из самых сложных этапов в построении действительно эффективных алгоритмов является выбор правильных параметров. Обычно, это делается легче с опытом, но так или иначе приходится делать перебор. К счастью, в Scikit-Learn уже есть немало реализованных для этого функцийДля примера посмотрим на подбор параметра регуляризации, в котором мы по очереди перебирают несколько значений:
Import numpy as np from sklearn.linear_model import Ridge from sklearn.grid_search import GridSearchCV # prepare a range of alpha values to test alphas = np.array() # create and fit a ridge regression model, testing each alpha model = Ridge() grid = GridSearchCV(estimator=model, param_grid=dict(alpha=alphas)) grid.fit(X, y) print(grid) # summarize the results of the grid search print(grid.best_score_) print(grid.best_estimator_.alpha)
Иногда более эффективным оказывается много раз выбрать случайно параметр из данного отрезка, померить качество алгоритма при данном параметре и выбрать тем самым луйший:
Import numpy as np from scipy.stats import uniform as sp_rand from sklearn.linear_model import Ridge from sklearn.grid_search import RandomizedSearchCV # prepare a uniform distribution to sample for the alpha parameter param_grid = {"alpha" : sp_rand()} # create and fit a ridge regression model, testing random alpha values model = Ridge() rsearch = RandomizedSearchCV(estimator=model, param_distributions=param_grid, n_iter=100 ) rsearch.fit(X, y) print(rsearch) # summarize the results of the random parameter search print(rsearch.best_score_) print(rsearch.best_estimator_.alpha)
Мы рассмотрели весь процесс работы с библиотекой Scikit-Learn за исключением вывода результатов обратно в файл, что предлагается сделать читателю в качестве упражнения, потому как одним из достоинств Python (и самой библиотеки Scikit-Learn) по-сравнению с R является отличная документация. В следующих частях мы рассмотрим подробно каждый из разделов, в частности, затронем такую важную вещь как Feauture Engineering .
Я очень надеюсь, что данный материал поможет начинающим Data Scientist"ам как можно скорее приступить к решению задач машинного обучения на практике. В заключение хочу пожелать успехов и терпения тем, кто только начинает участвовать в соревнованиях по машинному обучению!
Python является отличным языком программирования для реализации по множеству причин. Во-первых, Python имеет понятный синтаксис. Во-вторых, в Python очень просто производить манипуляции с текстом. Python используют большое число людей и организаций во всем мире, поэтому он развивается и хорошо документирован. Язык является кросс-платформенным и пользоваться им можно совершенно бесплатно.
Исполняемый псевдо-код
Интуитивно понятный синтаксис Python зачастую называют исполняемым псевдо-кодом. Установка Python по умолчанию уже включает высокоуровневые типы данных, такие как списки, кортежи, словари, наборы, последовательности и так далее, которые уже нет необходимости реализовывать пользователю. Эти типы данных высокого уровня делают простой реализацию абстрактных понятий. Python позволяет программировать в любом знакомом вам стиле: объектно-ориентированном, процедурном, функциональном и так далее.
В Python просто обрабатывать и манипулировать текстом, что делает его идеальным для обработки нечисловых данных. Есть ряд библиотек для использования Python для доступа к веб-страницам, а интуитивно понятные манипуляции с текстом позволяют легко извлекать данные из HTML -кода.
Python популярен
Язык программирования Python популярен и множество доступных примеров кода делает обучение ему простым и достаточно быстрым. Во-вторых, популярность означает, что есть множество модулей предназначенных для различных приложений.
Python является популярным языком программирования в научных, а также финансовых кругах. Ряд библиотек для научных вычислений, таких как SciPy и NumPy позволяют выполнять операции над векторами и матрицами. Это также делает код еще более читаемым и позволяет писать код, который выглядит как выражения линейной алгебры. Кроме того, научные библиотеки SciPy и NumPy скомпилированы, используя языки низкого уровня (С и Fortran ), что делает делает вычисления при использовании этих инструментов значительно быстрее.
Научные инструменты Python отлично работают в связке с графическим инструментом под названием Matplotlib . Matplotlib может строить двухмерные и трехмерные графики и может работать с большинством типов построений, обычно используемых в научном сообществе.
Python также имеет интерактивную оболочку, которая позволяет просматривать и проверять элементы разрабатываемой программы.
Новый модуль Python , под называнием Pylab , стремится объединить возможности NumPy , SciPy , и Matplotlib в одной среде и установке. На сегодняшний день пакет Pylab пока еще находится в стадии разработки, но за ним большое будущее.
Преимущества и недостатки Python
Люди используют различные языки программирования. Но для многих, язык программирования является просто инструментом для решения какой-то задачи. Python является языком высшего уровня, что позволяет тратить больше времени на осмысление данных и меньше временных на обдумывание того, в каком же виде они должны быть представлены для компьютера.
Единственным реальным недостатком Python является то, что он не так быстро выполняет программный код как, например Java или C . Причиной тому является то, что Python — язык интерпретируемый. Однако существует возможность вызова скомпилированных C -программ из Python . Это позволяет использовать лучшее из различных языков программирования и пошагово разрабатывать программу. Если вы поэкспериментировали над идеей, используя Python и решили, что это именно то, что вы хотите, чтобы было реализовано в готовой системе, то легко можно будет реализовать этот переход от прототипа к рабочей программе. Если программа построена по модульному принципу, то можно сначала удостоверится что то, что вам нужно работает в коде, написанном на Python , а затем, чтобы улучшить скорость выполнения кода, переписать критичные участки на языке C . Библиотека C++ Boost позволяет это с легкостью сделать. Другие инструменты, такие как Cython и PyPy позволяют увеличить производительность работы программы по сравнению с обычным Python .
Если сама реализуемая программой идея является «плохой», то лучше понять это, затратив на написание кода минимум драгоценного времени. Если же идея работает, то всегда можно улучшить производительность, переписав частично критичные участки программного кода.
В последние годы большое число разработчиков, в том числе, имеющих ученые степени, работало над улучшением производительности языка и отдельных его пакетов. Поэтому, не факт, что вы напишите код на C , который будет работать быстрее, чем то, что уже имеется в Python .
Какую версию Python использовать?
В настоящее время одновременно широко применяются различные версии этого, а именно 2.x и 3.x. Третья версия пока еще находится в стадии активной разработки, большинство различных библиотек гарантированно работают на второй версии, поэтому я пользуюсь второй версией, а именно 2.7.8, чего и вам советую. Каких-то прямо уж кардинальных изменений в 3-й версии этого языка программирования нет, поэтому ваш код с минимальными изменениями в будущем, в случае необходимости, можно будет перенести и для использования с третьей версией.
Для установки заходим на официальный сайт: www.python.org/downloads/
выбираем свою операционную систему и скачиваем установщик. Подробно я останавливаться на вопросе установки не буду, поисковики вам с легкостью в этом помогут.
Я на MacOs устанавливал себе версию Python, отличную от той, что была установлена в системе и пакеты через менеджер пакетов Anaconda (кстати, там же есть варианты установки под Windows и Linux ).
Под Windows , говорят, Python ставится с бубном, но сам не пробовал, врать не буду.
NumPy
![]()
NumPy является основным пакетом для научных вычислений в Python . NumPy является расширением языка программирования Python , добавляющим поддержку больших многомерных массивов и матриц, вместе с большой библиотекой высокоуровневых математических функций для работы с этими массивами. Предшественник NumPy , пакет Numeric , был первоначально создан Джимом Хаганином при участии ряда других разработчиков. В 2005 году Трэвис Олифант создал NumPy путем включения функций конкурирующего пакета Numarray в Numeric , произведя при этом обширные изменения.
Для установки в Терминале Linux выполняем:
sudo apt-get update sudo apt-get install python-numpy
sudo apt - get update sudo apt - get install python - numpy |
Простенький код с использованием NumPy который формирует одномерный вектор из 12 чисел от 1 до 12 и преобразует его в трехмерную матрицу:
from numpy import * a = arange(12) a = a.reshape(3,2,2) print a
from numpy import * a = arange (12 ) a = a . reshape (3 , 2 , 2 ) print a |
Результат у меня на компьютере выглядит следующим образом:

Вообще говоря, в Терминале код на Python я выполняю не очень часто, разве чтобы посчитать что-нибудь по-быстрому, как на калькуляторе. Мне нравится работать в IDE PyCharm . Вот так выглядит ее интерфейс при запуске вышеуказанного кода

SciPy
![]() SciPy
— это open-source библиотека с открытым исходным кодом для научных вычислений. Для работы SciPy
требуется, чтобы предварительно был установлен NumPy
, обеспечивающий удобные и быстрые операции с многомерными массивами. Библиотека SciPy
работает с массивами NumPy
, и предоставляет множество удобных и эффективных вычислительных процедур, например, для численного интегрирования и оптимизации. NumPy
и SciPy
просты в использовании, но достаточно мощные для проведения различных научных и технических вычислений.
SciPy
— это open-source библиотека с открытым исходным кодом для научных вычислений. Для работы SciPy
требуется, чтобы предварительно был установлен NumPy
, обеспечивающий удобные и быстрые операции с многомерными массивами. Библиотека SciPy
работает с массивами NumPy
, и предоставляет множество удобных и эффективных вычислительных процедур, например, для численного интегрирования и оптимизации. NumPy
и SciPy
просты в использовании, но достаточно мощные для проведения различных научных и технических вычислений.
Для установки библиотеки SciPy в Linux , выполняем в терминале:
sudo apt-get update sudo apt-get install python-scipy
sudo apt - get update sudo apt - get install python - scipy |
Приведу пример кода для поиска экстремума функции. Результат отображается уже используя пакет matplotlib , рассматриваемый чуть ниже.
import numpy as np from scipy import special, optimize import matplotlib.pyplot as plt f = lambda x: -special.jv(3, x) sol = optimize.minimize(f, 1.0) x = np.linspace(0, 10, 5000) plt.plot(x, special.jv(3, x), "-", sol.x, -sol.fun, "o") plt.show()
import numpy as np from scipy import special , optimize f = lambda x : - special . jv (3 , x ) sol = optimize . minimize (f , 1.0 ) x = np . linspace (0 , 10 , 5000 ) plt . plot (x , special . jv (3 , x ) , "-" , sol . x , - sol . fun , "o" ) plt . show () |
Результатом является график с отмеченным экстремумом:

Ради интереса попробуйте реализовать тоже самое на языке C и сравните количество строк кода, требуемых для получения результата. Сколько у вас получилось строк? Сто? Пятьсот? Две тысячи?
Pandas
![]() pandas
— это пакет Python
, предназначенный для обеспечения быстрыми, гибкими, и выразительными структурами данных, упрощающими работу с «относительными» или «помечеными» данными простым и интуитивно понятным способом. pandas
стремится стать основным высокоуровневым строительным блоком для проведения в Python
практического анализа данных, полученных из реального мира. Кроме того, этот пакет претендует стать самым мощным и гибким open-source
инструментом для анализа/обработки данных, доступным в любом языке программирования.
pandas
— это пакет Python
, предназначенный для обеспечения быстрыми, гибкими, и выразительными структурами данных, упрощающими работу с «относительными» или «помечеными» данными простым и интуитивно понятным способом. pandas
стремится стать основным высокоуровневым строительным блоком для проведения в Python
практического анализа данных, полученных из реального мира. Кроме того, этот пакет претендует стать самым мощным и гибким open-source
инструментом для анализа/обработки данных, доступным в любом языке программирования.
Pandas хорошо подходит для работы с различными типами данных:
- Табличные данные со столбцами различных типов, как в таблицах SQL или Excel .
- Упорядоченными и неупорядоченными данными (не обязательно с постоянной частотой) временных рядов.
- Произвольными матричными данными (однородными или разнородными) с помеченными строками и столбцами.
- Любыми другими формами наборов данных наблюдений, либо статистических данных. Данные на самом деле не требуют обязательного наличия метки для того, чтобы быть помещенными в структуру данных pandas .
Для установки пакета pandas выполняем в Терминале Linux :
sudo apt-get update sudo apt-get install python-pandas
sudo apt - get update sudo apt - get install python - pandas |
Простенький код, преобразующий одномерный массив в структуру данных pandas :
import pandas as pd import numpy as np values = np.array() ser = pd.Series(values) print ser
import pandas as pd import numpy as np values = np . array ([ 2.0 , 1.0 , 5.0 , 0.97 , 3.0 , 10.0 , 0.0599 , 8.0 ] ) ser = pd . Series (values ) print ser |
Результатом будет:

matplotlib
![]()
matplotlib является библиотекой графических построений для языка программирования Python и его расширения вычислительной математики NumPy . Библиотека обеспечивает объектно-ориентированный API для встраивания графиков в приложения, используя инструменты GUI общего назначения, такие как WxPython , Qt , или GTK+ . Существует также процедурный pylab -интерфейс напоминающий MATLAB . SciPy использует matplotlib .
Для установки библиотеки matpoltlib в Linux выполните следующие команды:
sudo apt-get update sudo apt-get install python-matplotlib
sudo apt - get update sudo apt - get install python - matplotlib |
Пример кода, использующий библиотеку matplotlib для создания гистограмм:
import numpy as np import matplotlib.mlab as mlab import matplotlib.pyplot as plt # example data mu = 100 # mean of distribution sigma = 15 # standard deviation of distribution x = mu + sigma * np.random.randn(10000) num_bins = 50 # the histogram of the data n, bins, patches = plt.hist(x, num_bins, normed=1, facecolor="green", alpha=0.5) # add a "best fit" line y = mlab.normpdf(bins, mu, sigma) plt.plot(bins, y, "r--") plt.xlabel("Smarts") plt.ylabel("Probability") plt.title(r"Histogram of IQ: $\mu=100$, $\sigma=15$") # Tweak spacing to prevent clipping of ylabel plt.subplots_adjust(left=0.15) plt.show()
import numpy as np import matplotlib . mlab as mlab import matplotlib . pyplot as plt # example data mu = 100 # mean of distribution sigma = 15 # standard deviation of distribution x = mu + sigma * np . random . randn (10000 ) num_bins = 50 # the histogram of the data n , bins , patches = plt . hist (x , num_bins , normed = 1 , facecolor = "green" , alpha = 0.5 ) # add a "best fit" line y = mlab . normpdf (bins , mu , sigma ) plt . plot (bins , y , "r--" ) plt . xlabel ("Smarts" ) plt . ylabel ("Probability" ) plt . title (r "Histogram of IQ: $\mu=100$, $\sigma=15$" ) # Tweak spacing to prevent clipping of ylabel plt . subplots_adjust (left = 0.15 ) plt . show () |
Результатом которого является:
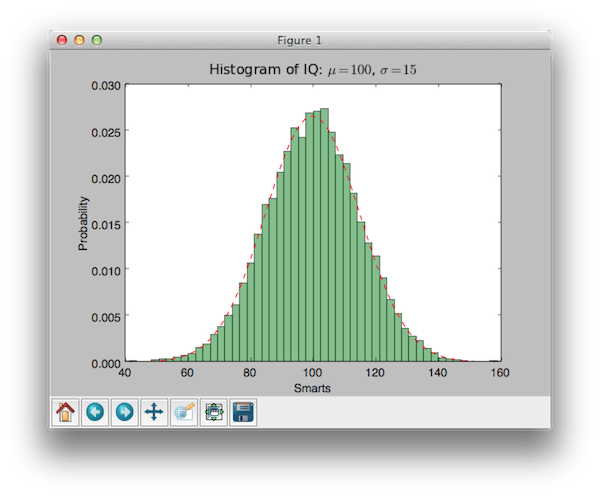
По-моему, очень даже симпатично!
является командной оболочкой для интерактивных вычислений на нескольких языках программирования, первоначально разработанной для языка программирования Python. позволяет расширить возможности представления, добавляет синтаксис оболочке, автодополнение и обширную историю команд. в настоящее время предоставляет следующие возможности:
- Мощные интерактивные оболочки (терминального типа и основанную на Qt ).
- Браузерный редактор с поддержкой кода, текста, математических выражений, встроенных графиков и других возможностей представления.
- Поддерживает интерактивную визуализацию данных и использование инструментов GUI.
- Гибкие, встраиваемые интерпретаторы для работы в собственных проектах.
- Простые в использовании, высокопроизводительные инструменты для параллельных вычислений.
Сайт IPython:
Для установки IPython в Linux, выполняем следующие команды в терминале:
sudo apt-get update sudo pip install ipython
Приведу пример кода, строящего линейную регрессию для некоторого набора данных, имеющихся в пакете scikit-learn :
import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model # Load the diabetes dataset diabetes = datasets.load_diabetes() # Use only one feature diabetes_X = diabetes.data[:, np.newaxis] diabetes_X_temp = diabetes_X[:, :, 2] # Split the data into training/testing sets diabetes_X_train = diabetes_X_temp[:-20] diabetes_X_test = diabetes_X_temp[-20:] # Split the targets into training/testing sets diabetes_y_train = diabetes.target[:-20] diabetes_y_test = diabetes.target[-20:] # Create linear regression object regr = linear_model.LinearRegression() # Train the model using the training sets regr.fit(diabetes_X_train, diabetes_y_train) # The coefficients print("Coefficients: \n", regr.coef_) # The mean square error print("Residual sum of squares: %.2f" % np.mean((regr.predict(diabetes_X_test) - diabetes_y_test) ** 2)) # Explained variance score: 1 is perfect prediction print("Variance score: %.2f" % regr.score(diabetes_X_test, diabetes_y_test)) # Plot outputs plt.scatter(diabetes_X_test, diabetes_y_test, color="black") plt.plot(diabetes_X_test, regr.predict(diabetes_X_test), color="blue", linewidth=3) plt.xticks(()) plt.yticks(()) plt.show()
import matplotlib . pyplot as plt import numpy as np from sklearn import datasets , linear_model # Load the diabetes dataset diabetes = datasets . load_diabetes () # Use only one feature diabetes_X = diabetes . data [ : , np . newaxis ] |
Машинное обучение – это исследования в области информатики, искусственного интеллекта и статистики. В центре внимания машинного обучения – подготовка алгоритмов для изучения закономерностей и прогнозирования данных. Машинное обучение особенно ценно, потому что оно позволяет использовать компьютеры для автоматизации процессов принятия решений.
Сейчас существует очень много приложений для машинного обучения. Netflix и Amazon используют машинное обучение для отображения новых рекомендаций. Банки используют его для обнаружения мошеннической деятельности в транзакциях с кредитными картами, а медицинские компании начинают использовать машинное обучение для мониторинга, оценки и диагностики пациентов.
Данный мануал поможет реализовать простой алгоритм машинного обучения в Python с помощью инструмента Scikit-learn . Для этого мы будем использовать базу данных о раке молочной железы и классификатор Naive Bayes (NB) , который предсказывает, является ли опухоль злокачественной или доброкачественной.
Требования
Для работы вам понадобится локальная среда разработки Python 3 и предварительно установленное приложение Jupyter Notebook. Это приложение очень полезно при запуске экспериментов по машинному обучению: оно позволяет запускать короткие блоки кода и быстро просматривать результаты, легко тестировать и отлаживать код.
Настроить такую среду вам помогут следующие мануалы:
1: Импорт Scikit-learn
Для начала нужно установить модуль Scikit-learn. Это одна из лучших и наиболее документированных библиотек Python для машинного обучения.
Чтобы начать работу над проектом, разверните среду разработки Python 3. Убедитесь, что вы находитесь в каталоге, в котором хранится эта среда, и выполните следующую команду:
My_env/bin/activate
После этого проверьте, не был ли модуль Sckikit-learn установлен ранее.
python -c "import sklearn"
Если модуль sklearn установлен, команда выполнится без ошибок. Если модуль не установлен, вы увидите ошибку:
Traceback (most recent call last): File "
Чтобы загрузить библиотеку, используйте pip:
pip install scikit-learn
После завершения установки запустите Jupyter Notebook:
jupyter notebook
В Jupyter создайте документ ML Tutorial. В первую ячейку документа импортируйте модуль sklearn.
Теперь можно начать работу с набором данных для модели машинного обучения.
2: Импорт наборов данных
В этом руководстве используется база данных диагностики рака молочной железы в Висконсине . Набор данных включает в себя различную информацию о раке молочной железы, а также классификационные метки (злокачественные или доброкачественные опухоли). Набор данных состоит из 569 экземпляров и 30 атрибутов (радиус опухоли, текстура, гладкость, площадь и т. д.).
На основе этих данных можно построить модель машинного обучения, которая сможет предсказать, является ли опухоль злокачественной или доброкачественной.
Scikit-learn поставляется с несколькими наборами данных, включая этот. Импортируйте и загрузите набор данных. Для этого добавьте в документ:
...
from sklearn.datasets import load_breast_cancer
# Load dataset
data = load_breast_cancer()
Переменная data содержит словарь, важными ключами которого являются названия классификационных меток (target_names), метки (target), названия атрибутов (feature_names) и атрибуты (data).
Импортируйте модуль GaussianNB. Инициализируйте модель с помощью функции GaussianNB(), а затем потренируйте модель, применив ее к данным с помощью gnb.fit():
...
# Initialize our classifier
gnb = GaussianNB()
# Train our classifier
После этого можно применить подготовленную модель, чтобы сделать прогнозы на тестовом наборе данных, который используется с помощью функции predict(). Функция predict() возвращает массив предполагаемых результатов для каждого экземпляра данных в тестовом наборе. Затем можно вывести все прогнозы.
Используйте функцию predict() в наборе test и отобразите результат:
...
# Make predictions
preds = gnb.predict(test)
print(preds)
Запустите код.
В выводе Jupyter Notebook вы увидите, что функция predict() возвращает массив из 0 и 1, которые представляют предсказанные программой результаты.
5: Оценка точности модели
С помощью массива меток класса можно оценить точность прогнозируемых значений модели, сравнив два массива (test_labels и preds). Чтобы определить точность классификатора машинного обучения, можно использовать функцию accuracy_score().
...
# Evaluate accuracy
Судя по результатам, данный классификатор NB имеет точность 94,15%. Это означает, что 94,15% ситуаций он оценивает правильно и может предсказать результат.
Вы создали свой первый классификатор машинного обучения. Теперь нужно реорганизовать код, переместив все выражения import в начало документа. В результате код должен выглядеть так:
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score
# Load dataset
data = load_breast_cancer()
# Organize our data
label_names = data["target_names"]
labels = data["target"]
feature_names = data["feature_names"]
features = data["data"]
# Look at our data
print(label_names)
print("Class label = ", labels)
print(feature_names)
print(features)
# Split our data
train, test, train_labels, test_labels = train_test_split(features,
labels,
test_size=0.33,
random_state=42)
# Initialize our classifier
gnb = GaussianNB()
# Train our classifier
model = gnb.fit(train, train_labels)
# Make predictions
preds = gnb.predict(test)
print(preds)
# Evaluate accuracy
print(accuracy_score(test_labels, preds))
Теперь вы можете продолжить работу с этим кодом и усложнить свой классификатор. Вы можете экспериментировать с различными подмножествами функций или попробовать другие алгоритмы. Больше идей машинного обучения можно найти на