How to write artificial intelligence in python. How to create your own neural network from scratch in Python
James Loy, Georgia Tech. A beginner's guide to creating your own neural network in Python.
Motivation: Based on personal experience in studying deep learning, I decided to create a neural network from scratch without a complex training library such as, for example, . I believe that for a beginning Data Scientist it is important to understand the internal structure of a neural network.
This article contains what I learned and hopefully it will be useful for you too! Other useful articles on the topic:
What is a neural network?
Most articles on neural networks draw parallels with the brain when describing them. It's easier for me to describe neural networks as a mathematical function that maps a given input to a desired output, without going into too much detail.
Neural networks consist of the following components:
- input layer, x
- arbitrary quantity hidden layers
- output layer, ŷ
- kit scales And displacements between each layer W And b
- choice activation functions for each hidden layer σ ; in this work we will use the Sigmoid activation function
The diagram below shows the architecture of a two-layer neural network (note that the input layer is usually excluded when counting the number of layers in a neural network).
Creating a Neural Network class in Python is simple:
Neural network training
Exit ŷ simple two-layer neural network:
In the above equation, the weights W and the bias b are the only variables that affect the output ŷ.
Naturally, the correct values for the weights and biases determine the accuracy of the predictions. The process of fine-tuning the weights and biases from the input data is known as neural network training.
Each iteration of the learning process consists of the following steps
- computing the predicted output ŷ, called forward propagation
- updating weights and biases, called backpropagation
The sequential graph below illustrates the process:

Direct distribution
As we saw in the graph above, forward propagation is just a simple calculation, and for a basic 2-layer neural network, the output of the neural network is given by:
Let's add a forward propagation function to our Python code to do this. Note that for simplicity, we have assumed offsets to be 0.
However, we need a way to assess the “goodness” of our forecasts, that is, how far off our forecasts are). Loss function just allows us to do this.
Loss function
There are many loss functions available, and the nature of our problem should dictate our choice of loss function. In this work we will use sum of squared errors as a loss function.

The sum of squared errors is the average of the differences between each predicted and actual value.
The learning goal is to find a set of weights and biases that minimizes the loss function.
Backpropagation
Now that we have measured the error in our forecast (loss), we need to find a way propagating the error back and update our weights and biases.
To know the appropriate amount to adjust the weights and biases, we need to know the derivative of the loss function with respect to the weights and biases.
Let us recall from the analysis that The derivative of a function is the slope of the function.

If we have a derivative, then we can simply update the weights and biases by increasing/decreasing them (see diagram above). It is called gradient descent.
However, we cannot directly calculate the derivative of the loss function with respect to weights and biases because the loss function equation does not contain weights and biases. So we need a chain rule to help with the calculation.
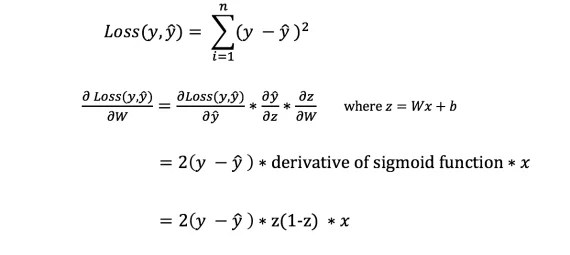
Phew! This was cumbersome, but it allowed us to get what we needed — the derivative (slope) of the loss function with respect to the weights. Now we can adjust the weights accordingly.
Let's add the backpropagation function to our Python code:
Checking the operation of the neural network
Now that we have our complete Python code to perform forward and back propagation, let's walk through our neural network with an example and see how it works.
 Ideal set of scales
Ideal set of scales Our neural network must learn the ideal set of weights to represent this function.
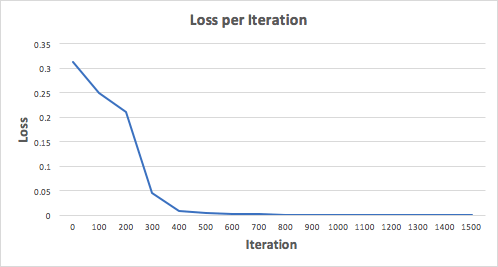
Let's train the neural network for 1500 iterations and see what happens. Looking at the iteration loss plot below, we can clearly see that the loss monotonically decreases to a minimum. This is consistent with the gradient descent algorithm we discussed earlier.
Let's look at the final prediction (output) from the neural network after 1500 iterations.

We did it! Our forward and backpropagation algorithm has shown that the neural network performs successfully, and the predictions converge on the true values.
Note that there is a slight difference between the predictions and the actual values. This is desirable because it prevents overfitting and allows the neural network to generalize better to unseen data.
Final Thoughts
I learned a lot in the process of writing my own neural network from scratch. While deep learning libraries like TensorFlow and Keras allow you to build deep networks without fully understanding the inner workings of a neural network, I find it helpful for aspiring Data Scientists to gain a deeper understanding of them.
I have invested a lot of my personal time in this work, and I hope that it will be useful to you!
We are now experiencing a real boom in neural networks. They are used for recognition, localization and image processing. Neural networks can already do many things that are not available to humans. We need to get involved in this matter ourselves! Consider a neutron network that will recognize numbers in an input image. It's very simple: just one layer and an activation function. This won't allow us to recognize absolutely all test images, but we can handle the vast majority. As data we will use the MNIST data collection, well known in the world of number recognition.
To work with it in Python there is a library python-mnist. To install:
Pip install python-mnist
Now we can load the data
From mnist import MNIST mndata = MNIST("/path_to_mnist_data_folder/") tr_images, tr_labels = mndata.load_training() test_images, test_labels = mndata.load_testing()
You need to download archives with data yourself, and specify the path to the directory with them to the program. Now the tr_images and test_images variables contain images for network training and testing, respectively. And the variables tr_labels and test_labels are labels with the correct classification (i.e. numbers from images). All images are 28x28 in size. Let's set a variable with size.
Img_shape = (28, 28)
Let's convert all the data into numpy arrays and normalize them (resize them to a size from -1 to 1). This will increase the accuracy of calculations.
Import numpy as np for i in range(0, len(test_images)): test_images[i] = np.array(test_images[i]) / 255 for i in range(0, len(tr_images)): tr_images[i] = np.array(tr_images[i]) / 255
I note that although it is customary to represent images as a two-dimensional array, we will use a one-dimensional one, it is easier for calculations. Now you need to understand “what is a neural network”! And this is just an equation with a large number of coefficients. We have an input array of 28*28=784 elements and another 784 weights to determine each digit. During the operation of a neural network, you need to multiply the input values by weights. Add the resulting data and add the offset. The resulting result is fed to the activation function. In our case it will be Relu. This function is equal to zero for all negative arguments and zero for all positive arguments.

There are many more activation functions! But this is the simplest neural network! Let's define this function using numpy
Def relu(x): return np.maximum(x, 0)
Now, to calculate the image in the picture, you need to calculate the result for 10 sets of coefficients.
Def nn_calculate(img): resp = list(range(0, 10)) for i in range(0,10): r = w[:, i] * img r = relu(np.sum(r) + b[ i]) resp[i] = r return np.argmax(resp)
For each set we will get the output result. The output with the highest result is most likely our number.

In this case, 7. That's all! But no... After all, you need to get these same coefficients somewhere. We need to train our neural network. For this purpose, the backpropagation method is used. Its essence is to calculate the network outputs, compare them with the correct ones, and then subtract from the coefficients the numbers necessary for the result to be correct. It must be remembered that in order to calculate these values, the derivative of the activation function is needed. In our case, it is equal to zero for all negative numbers and 1 for all positive ones. Let's determine the coefficients randomly.
W = (2*np.random.rand(10, 784) - 1) / 10 b = (2*np.random.rand(10) - 1) / 10 for n in range(len(tr_images)): img = tr_images[n] cls = tr_labels[n] #forward propagation resp = np.zeros(10, dtype=np.float32) for i in range(0,10): r = w[i] * img r = relu( np.sum(r) + b[i]) resp[i] = r resp_cls = np.argmax(resp) resp = np.zeros(10, dtype=np.float32) resp = 1.0 #back propagation true_resp = np. zeros(10, dtype=np.float32) true_resp = 1.0 error = resp - true_resp delta = error * ((resp >= 0) * np.ones(10)) for i in range(0,10): w[i ] -= np.dot(img, delta[i]) b[i] -= delta[i]
As training progresses, the coefficients will begin to look a little like numbers:
Let's check the accuracy of the work:
Def nn_calculate(img): resp = list(range(0, 10)) for i in range(0,10): r = w[i] * img r = np.maximum(np.sum(r) + b[ i], 0) #relu resp[i] = r return np.argmax(resp) total = len(test_images) valid = 0 invalid = for i in range(0, total): img = test_images[i] predicted = nn_calculate (img) true = test_labels[i] if predicted == true: valid = valid + 1 else: invalid.append(("image":img, "predicted":predicted, "true":true)) print("accuracy ()".format(valid/total))
I got 88%. Not that cool, but very interesting!
This time I decided to study neural networks. I was able to acquire basic skills in this matter over the summer and fall of 2015. By basic skills, I mean that I can create a simple neural network myself from scratch. You can find examples in my GitHub repositories. In this article, I will give some explanations and share resources that you may find useful in your study.
Step 1. Neurons and feedforward method
So what is a “neural network”? Let's wait with this and deal with one neuron first.
A neuron is like a function: it takes several values as input and returns one.
The circle below represents an artificial neuron. It receives 5 and returns 1. The input is the sum of the three synapses connected to the neuron (three arrows on the left).
On the left side of the picture we see 2 input values (in green) and an offset (in brown).
The input data can be numerical representations of two different properties. For example, when creating a spam filter, they could mean the presence of more than one word written in CAPITAL LETTERS and the presence of the word "Viagra".
The input values are multiplied by their so-called "weights", 7 and 3 (highlighted in blue).
Now we add the resulting values with the offset and get a number, in our case 5 (highlighted in red). This is the input of our artificial neuron.

Then the neuron performs some calculation and produces an output value. We got 1 because the rounded value of the sigmoid at point 5 is 1 (we'll talk about this function in more detail later).
If this were a spam filter, the fact that output 1 would mean that the text was marked as spam by the neuron.

Illustration of a neural network from Wikipedia.
If you combine these neurons, you get a directly propagating neural network - the process goes from input to output, through neurons connected by synapses, as in the picture on the left.
Step 2. Sigmoid
After you've watched Welch Labs' lessons, it's a good idea to check out Week 4 of Coursera's machine learning course on neural networks to help you understand how they work. The course goes very deep into mathematics and is based on Octave, while I prefer Python. Because of this, I skipped the exercises and got all the necessary knowledge from the videos.

A sigmoid simply maps your value (on the horizontal axis) to a range from 0 to 1.
My first priority was to study the sigmoid, as it has figured in many aspects of neural networks. I already knew something about it from the third week of the above-mentioned course, so I watched the video from there.
But you won't get far with videos alone. For complete understanding, I decided to code it myself. So I started writing an implementation of a logistic regression algorithm (which uses a sigmoid).
It took a whole day, and the result was hardly satisfactory. But it doesn't matter, because I figured out how everything works. The code can be seen.
You don't have to do this yourself, since it requires special knowledge - the main thing is that you understand how the sigmoid works.
Step 3. Backpropagation method
Understanding how a neural network works from input to output is not that difficult. It is much more difficult to understand how a neural network learns from data sets. The principle I used is called