Ett program för att hitta alla progs på din dator. Snabbsökning
För att hitta de filer du behöver på din dator har vi redan tittat på standardfunktionerna som finns tillgängliga i Windows -systemet från början. Du kan läsa mer om standard Windows -sökning i artiklarna: och.
Fördelarna med standardsökningen är att du inte behöver installera något annat på din dator!
Men det finns också en allvarlig nackdel - inte alla vanliga sökningar fungerar eller fungerar inte som vi skulle vilja!
Därför kommer vi i denna artikel att titta på en separat utmärkt gratis allt, som låter dig mycket snabbt, kan du till och med säga direkt (i farten), hitta de filer du behöver på din dator!
Med Allt kan du söka efter filer på din dator inte bara med hela filnamnet, utan till och med genom en del av ordet! Detta är en bra funktion för situationer där vi inte kommer ihåg namnet på hela filen.
Vi anger helt enkelt ett ord eller en del av ett ord i sökfältet och får omedelbart resultatet! Samtidigt, överraskande, allt saktar inte ner datorn alls, som det händer med andra program.
Allt är ett snabbt, lätt och bekvämt program för att hitta filer och mappar på din dator.
Låt oss börja med en steg-för-steg genomgång av installation och användning av detta program.
Hur man laddar ner allt på ryska
Låt oss säga att jag inte kommer ihåg var den här boken är lagrad på min dator.
För att hitta det med programmet Allt, Jag behöver inte skriva in hela den här långa boktiteln. Jag kan bara skriva ett ord bok och få ett resultat så här:

I det här fallet visade en sökning mig att jag har 33 element där ordet förekommer bok... Dessutom visar sökresultaten alla element efter filtyp med markeringen av ordet jag letade efter.
Och redan i listan som visas kan jag hitta filen jag behöver och gå till den genom att helt enkelt dubbelklicka på den snabbt. Om det är en fil öppnas den omedelbart. Om det är en mapp med filer öppnas mappen.
Eller så kan jag begränsa sökningen så att listan blir mindre. Till exempel skriver jag ordet mest... Jag får genast den mapp jag behöver:

Som du kan se är det väldigt enkelt att hitta filer och mappar på din dator med Allt. Jag är glad att det är gratis, på ryska och ger mycket snabba sökresultat!
Avancerade allt -inställningar
Program Allt den är initialt redan optimalt konfigurerad för de flesta användare. Det finns dock ytterligare funktioner som du kan använda vid behov.
Så till exempel att använda menyn Sök du kan ange utifrån vilka kriterier utdata ska visas: efter filer i vissa format, efter mappar eller alla. Sådana begränsningar kan vara användbara om namnet finns i olika filer och listan över sådana filer är stor. Och tack vare begränsningen till vissa kategorier kan du avsiktligt begränsa din sökning:

Det skulle också vara bra att bara bläddra igenom de funktioner som finns i menyn Service-> inställningar... Jag upprepar att som standard är allt redan konfigurerat för de flesta användares önskemål, men du kanske vill aktivera eller inaktivera några ytterligare inställningar.
Hitta allt bärbart
I början av artikeln pratade vi redan om en sådan portabel version av detta program. Använd den bärbara versionen såväl som den stationära. Det är bara värt att nämna att den bärbara versionen är packad i ett arkiv.
Därför, efter att ha laddat ner arkivet för den bärbara versionen, behöver du en arkiverare så att du kan öppna arkivet. Om det nedladdade arkivet inte kan öppnas, är arkivaren inte installerad på datorn. I det här fallet, ladda ner och installera, vars installation och användning vi redan har diskuterat i en separat artikel.
Om du planerar att använda den bärbara versionen på en dator som inte vet vilket bitdjup, använd ett arkiv för 32 -bitars system. Eller bättre ladda ner båda versionerna - vissa kommer definitivt att starta, annars kommer det helt enkelt att visa ett meddelande:

Så: Om du ens måste leta efter filer eller mappar på din dator då och då är jag säker på att du kommer att uppskatta detta gratisprogram!
Ladda ner, använd, dela dina intryck i kommentarerna!
Program för att snabbt hitta information på datorn.
↓ Nytt i kategorin "Hitta filer":
Gratis
Snoop 4.5.2 är en personlig sökmotor som har möjlighet att hitta nödvändiga dokument eller filer på din hårddisk på en sekund. Snooper -applikationen tillåter användare att hitta och använda alla dokument nästan omedelbart, med en enkel sökning genom nyckelord.
Gratis  Archivarius 3000 4.44 är ett program som söker efter dokument och e -postmeddelanden på datorn, på flyttbara diskar och i det lokala nätverket. Programmet Archivarius 3000 utför sökningar med hjälp av sökord eller frågespråk.
Archivarius 3000 4.44 är ett program som söker efter dokument och e -postmeddelanden på datorn, på flyttbara diskar och i det lokala nätverket. Programmet Archivarius 3000 utför sökningar med hjälp av sökord eller frågespråk.
Gratis  SearchMyFiles 2.06 är ett program som hjälper till att ersätta standard Windows -sökning genom att utöka dess funktionalitet och göra det mer bekvämt. SearchMyFiles -applikationen kan enkelt söka efter filer i systemet enligt de angivna parametrarna.
SearchMyFiles 2.06 är ett program som hjälper till att ersätta standard Windows -sökning genom att utöka dess funktionalitet och göra det mer bekvämt. SearchMyFiles -applikationen kan enkelt söka efter filer i systemet enligt de angivna parametrarna.
Gratis  REM 6.0 hjälper användaren att utföra en snabb sökning med parametrar som namn, innehåll och åtkomst till användaren själv till data för filer och mappar, inte bara på datorn, utan också på det lokala nätverket eller på tillgängliga FTP -servrar . REM -applikationen hjälper användare som lagrar ett stort antal olika mappar och filer, inte bara på lokala enheter, utan också på nätverket.
REM 6.0 hjälper användaren att utföra en snabb sökning med parametrar som namn, innehåll och åtkomst till användaren själv till data för filer och mappar, inte bara på datorn, utan också på det lokala nätverket eller på tillgängliga FTP -servrar . REM -applikationen hjälper användare som lagrar ett stort antal olika mappar och filer, inte bara på lokala enheter, utan också på nätverket.
Gratis  NetLook 2.3 är ett litet verktyg som skannar det lokala nätverket. NetLook har också möjlighet att navigera delade resurser och utbyta nätverksmeddelanden mellan olika användare.
NetLook 2.3 är ett litet verktyg som skannar det lokala nätverket. NetLook har också möjlighet att navigera delade resurser och utbyta nätverksmeddelanden mellan olika användare.
Gratis  Disk Investigator 1.61 är ett program för att hitta dold information från din hårddisk. Disk Investigator hjälper dig inte bara att söka utan också återställa data som raderats av misstag.
Disk Investigator 1.61 är ett program för att hitta dold information från din hårddisk. Disk Investigator hjälper dig inte bara att söka utan också återställa data som raderats av misstag.
Gratis  Copernic Desktop Search 3.5.1 är en datainsamlingsapplikation. Programmet Copernic Desktop Search har också möjlighet att arbeta med data från e -postmeddelanden och bearbeta bilagor till dem, som finns i hårddiskens minne.
Copernic Desktop Search 3.5.1 är en datainsamlingsapplikation. Programmet Copernic Desktop Search har också möjlighet att arbeta med data från e -postmeddelanden och bearbeta bilagor till dem, som finns i hårddiskens minne.
Gratis  CloneSpy 2.62 är ett program för att upptäcka dubbletter av filer på din hårddisk. CloneSpy -appen hjälper dig enkelt och snabbt att hitta dubbletter av nedladdade program, oavsett namn eller nedladdningsdatum.
CloneSpy 2.62 är ett program för att upptäcka dubbletter av filer på din hårddisk. CloneSpy -appen hjälper dig enkelt och snabbt att hitta dubbletter av nedladdade program, oavsett namn eller nedladdningsdatum.
Gratis  AVSearch 3.13 är ett program för att söka efter filer på skivor, baserat på textfragment med valfri kodning. AVSearch stöder kodningar som Windows, KOI-8R, UNICODE, OEM 866 (DOS) och ISO 8859-5.
AVSearch 3.13 är ett program för att söka efter filer på skivor, baserat på textfragment med valfri kodning. AVSearch stöder kodningar som Windows, KOI-8R, UNICODE, OEM 866 (DOS) och ISO 8859-5.
Gratis  Auslogics Duplicate File Finder 2.2.1.0 är ett effektivt och lättanvänt program för att hitta och ta bort minneskrävande dubblettfiler. Auslogics Duplicate File Finder hjälper dig att snabbt städa upp ungefär halva arbetsytan på dina skivor.
Auslogics Duplicate File Finder 2.2.1.0 är ett effektivt och lättanvänt program för att hitta och ta bort minneskrävande dubblettfiler. Auslogics Duplicate File Finder hjälper dig att snabbt städa upp ungefär halva arbetsytan på dina skivor.
Att säga att i vår tid av informationsteknik och den oändliga tillväxten av mängden data som är tillgänglig för både en individ och samhället, finns det många problem med behandling av information och dess sökande är redan blasfemi. Som bara inte lyfter detta ämne. Och för att inte ladda dig med subjektiva och delvis objektiva bedömningar från olika informationskällor angående problemet kommer jag att gå direkt till dess lösning. Idag pratar vi om sökning. Det vill säga om program och seriösa informationssystem som söker efter de dokument och data vi behöver.
Uppgradering av direkt sökning
För inte så länge sedan, när träden var stora och det inte fanns mycket information ens om företagets lokala nätverk, utfördes varje sökning genom en banal sökning genom en handfull tillgängliga filer och en sekventiell kontroll av deras namn och innehåll . En sådan sökning kallas direkt, och program (verktyg) som använder direktsökningsteknik finns traditionellt i alla operativsystem och verktygspaket. Men även kraften hos moderna datorer räcker inte för en snabb och adekvat sökning i stora mängder data vid direkt sökning. Att gå igenom ett par hundra dokument på disken och söka i ett stort bibliotek och flera dussin brevlådor är två olika saker. Därför bleknar direktprogram i dag tydligt i bakgrunden - när det gäller universella medel.
Naturligtvis har denna typ av sökning inte varit efterfrågad i företagssektorn på länge. Volymerna är inte desamma. Och därför, i flera år nu, och nyligen har det varit entydigt, teknik som snabbt och exakt kan söka efter dokument i olika format och från olika källor är mer än relevant. För inte så länge sedan tillkännagav Microsofts "pappa" Bill Gates, tydligen avundsjuk på den fenomenala framgången för internetsökmotorn Google, vid en av presskonferenser programvarans önskan (och inte bara) att marknadsföra, utveckla och fördjupa skapande av sökmotorer och teknik på alla möjliga sätt. Men det är för tidigt att skapa något fenomenalt fungerande program från Microsoft eller en konkurrenskraftig server på Internet (MSN saknar fortfarande Google). Låt oss därför vända oss till den redan befintliga utvecklingen. Index, fråga, relevans
Modern teknik bygger på två grundläggande processer. Först indexerar den tillgänglig information och behandlar begäran med den efterföljande utmatningen av resultaten. När det gäller det första skapar alla program (vare sig det är en stationär sökmotor, företagsinformationssystem eller internetsökmotor) ett eget sökområde. Det vill säga, det behandlar dokument och bildar ett index över dessa dokument (en organiserad struktur som innehåller information om de bearbetade uppgifterna). I framtiden är det det skapade indexet som används för arbete - snabbt få en lista över nödvändiga dokument enligt förfrågan. Resten, även om det inte är så enkelt när det gäller teknik, är ganska förståeligt för den vanliga användaren. Programmet behandlar begäran (för en nyckelfras) och visar en lista över dokument som innehåller denna nyckelfras. Eftersom informationen finns i ett strukturerat index är behandlingen av en begäran mycket (tiotals och hundratals gånger!) Snabbare än vid direkt sökning (valet av dokument utförs inte genom att räkna upp filer, utan genom att analysera text information i index).
Programmet visar de hittade dokumenten i den resulterande listan efter relevans - dokumentets överensstämmelse med frågetexten. I olika tekniker finns det naturligtvis olika metoder för att söka och bestämma relevansen av ett dokument (antalet "förekomster" av ett ord och dess frekvens av omnämnande i dokumentet, förhållandet mellan dessa parametrar och det totala antalet ord i dokumentet, avståndet mellan orden i sökfrasen i de sökade filerna och så vidare). Baserat på dessa parametrar bestäms dokumentets "vikt" och, beroende på den, visas den eller den filen i resultatlistan vid en viss position. För internetsökningar är situationen ännu mer komplicerad. I detta fall måste många andra faktorer beaktas (Googles sidrankning är ett exempel). Men det här är ett ämne för en separat artikel, så vi kommer inte att beröra Internet.
Denna artikel diskuterar möjligheterna hos flera populära sökprogram som kan skryta med både anständiga hastigheter och bra funktionalitet. Men skryt i reklambroschyrer är en sak, men att stå emot en experts blick är en helt annan. Och experter hittades varken mer eller mindre än ett fullt kontor för dem som gillar att gräva i programvara för dess användbarhet. Testdatorn (Athlon 2,2 MHz, med 1 GB RAM, 160 GB Seagate IDE -hårddisk vid 7200 rpm och Windows XP) installerades med en uppsättning program: dtSearch Desktop, Snoop Prof Deluxe, Google Desktop Search, SearchInform, Copernic Desktop Sök, ISYS Desktop. För testerna sammanställdes en textbas av dokument i doc-, txt- och html -format med en total storlek på varken mer eller mindre, men 20 gigabyte. En grupp kamrater under ledning av din ödmjuka tjänare testade, jämförde och delade sina subjektiva intryck på varje programvara. Läs en sammanfattning av resultaten nedan. dtSearch Desktop
Ett program som enligt utvecklarna hävdar att det är den snabbaste, bekvämaste och bästa sökmotorn. Som i allmänhet och alla andra från denna recension. DtSearchs gränssnitt är ganska enkelt, men vissa fönster eller flikar är något överbelastade med element, vilket ger intrycket av att vara svårt att använda. Men i själva verket finns det inga särskilda svårigheter. Det enda riktigt obehagliga ögonblicket är bristen på stöd för den ryska språkprogramvaran (trots att programmet kan söka efter dokument på flera språk är gränssnittet uteslutande engelska).
Men dtSearch är ett av få program som kan indexera webbsidor till ett användardefinierat "djup" (om än med hänsyn till "tilläggsköp" i tilläggssatsen dtSearch Spider). Detta är förutom att stödja filer på disken i olika textformat och e -postmeddelanden från Outlook -brevlådan. Samtidigt vet programmet inte hur man arbetar med databaser, som är en så god bit för sökmotorer på grund av de stora mängderna information i dem och utbredd användning i företag, och därför i företagsnätverk. Indexeringshastigheten för dtSearch -dokument visade sig vara på rätt nivå. Framöver kommer jag att säga att detta program klarade av att indexera en viss mängd information på en nivå med en annan konkurrent - iSYS - och delade med sig andraplatsen i listan över de snabbaste systemen. DtSearch indexerade testet 20 gigabyte information på 6 timmar 13 minuter, vilket skapade ett index på 7,9 GB för behoven för efterföljande sökningar.
När det gäller sökfunktionerna, här är de på rätt nivå. Först finns det morfologisk sökning i dtSearch (sök efter ett ord i alla dess morfologiska former). Med detta tillfälle befriar du dig från exempelvis tankar som "i vilket fall användes ett visst ord i det dokument jag behöver?" Användningen av morfologisk sökning är nästan alltid motiverad, därför bör den finnas i alla professionella sökmotorer.
Ljudsökning är en icke-standardfunktion även för professionella sökmotorer. Dess väsen ligger i det faktum att programmet kommer att söka efter ord som låter samma som det ord du angav. Och bäst av allt, den här funktionen fungerar också för det ryska språket! Om du till exempel skriver ordet "öra" i en sökfråga, ser du inte bara orden "öra" utan också "öra".
Felkorrigeringssökning är en mycket viktig funktion. Den används för att söka efter ord som innehåller syntaxfel - det kan till exempel vara både stavfel och fel i dokument som erhållits med teckenigenkänningssystem. Ett enkelt exempel - du letar efter ordet tangentbord. Vissa dokument innehåller ordet "tangentbord", det är uppenbart att detta faktiskt är ordet "tangentbord", bara en person skrev texten. Sök nu med felkorrigering, detta kommer att upptäcka och inkludera dokumentet med ordet "knappsats" i resultatet. Även i dtSearch finns en inställning som låter dig bestämma graden av möjliga felaktiga tecken.
Sök med synonymer. Denna funktion använder en lista med synonymer för olika ord. Så, till exempel, genom att ange ordet "snabbt", kommer programmet också att hitta orden "snabbt" och andra som är synonymer för ordet "snabbt", om sådana naturligtvis finns i listan över synonymer. En färdig lista med synonymer levereras inte med dtSearch-programmet, men det är möjligt att använda listorna på Internet (följaktligen krävs en anslutning, vilket inte alltid är bekvämt), eller så kan du skapa din egen lista med synonymer.
Förutom de listade funktionerna kan dtSearch söka med fraser som består av ord som är anslutna med logiska operationer. Varje ord i frågan kan tilldelas sin egen "vikt", det vill säga betydelse. Ett användbart alternativ är att använda en ordlista som består av obetydliga ord för att inte ta hänsyn till dem vid sökning, men denna ordbok är också tom och du måste fylla i den själv.
Därefter kommer vi att överväga programmets möjligheter när du arbetar i ett nätverk. Faktum är att dtSearch inte erbjuder några specifika nätverksfunktioner. Ändå är det fullt möjligt att använda det på webben. Alternativt kan du skapa något slags index och lägga det i en offentlig (delad) mapp. Själva programmet kan installeras för varje användare på en dator, eller det kan också läggas ut i en delad mapp, och genvägar för varje användare kan skapas på ett speciellt sätt med hjälp av kommandoradsparametrarna, vars syfte beskrivs i hjälpfilen som medföljer programmet. Det är också möjligt att automatiskt installera programmet på nätverket med en MSI -fil. Detta kommer att ta hänsyn till inställningarna för varje ansluten användare.
I allmänhet är detta ett bra program från kategorin professionella sökmotorer. Det kan hävda att det är ett bra betyg, men att få förtroende och respekt från användare kan vara svårt för dtSearch på grund av vissa faktorer (allt är inte smidigt med gränssnittet, ryska användare är berövade, det finns inga ljusa funktioner för att arbeta med nätverket) . När det gäller sökningen efter dokument direkt hade programmet inga överlappningar med den ryska texten. Eftersom det inte fanns några med den deklarerade morfologin eller med en suddig sökning. Systemet fann tillfredsställande de nödvändiga dokumenten både genom en enkel fråga i ett ord och genom att använda ett par stycken eller ett dokument som en nyckelfras.
Officiell webbplats:
Distributionsstorlek: 23 Mb
Baserat på namnet kan du gissa att det finns stöd för det ryska språket i detta program. Det här är redan trevligt. När det gäller gränssnittet är det i allmänhet något ovanligt, men det ser väldigt attraktivt ut. Bekvämlighet är en annan sak. Ett mycket kontroversiellt kriterium, men förmodligen är en lösning med flera fönster inte det bästa alternativet (en begäran anges i ett fönster, resultatet visas i ett annat och liknande).
Snopen använder samma index för att utföra snabba sökningar, men indexering är mycket långsammare än andra program. Detta är mycket märkligt, särskilt med tanke på att dess sökfrågebearbetningskapacitet är mycket svag, vilket innebär att indexstrukturen inte är komplicerad. Mest troligt beror detta på ooptimerade algoritmer. Detta program visade sig vara en tydlig outsider när det gäller indexering och sökhastigheter: tiden som används för att skapa ett index är sex gånger längre än för samma dtSearch och iSYS. Att indexera 20 gigabyte text för blodhunden tog 38 timmar och 46 minuters arbete. Och det skapade "sökområdet" upptog samma storlek på hårddisken som originaldata med ett litet minus - 19 gigabyte.
Snoop kan presenteras som ett alternativ till standard Windows -sökning, den kan knappast mer. Det faktum att Bloodhounds primära uppgift är den enklaste filsökningen indikerar inte bara ett litet antal funktioner för att analysera texten i sökfrågor och en avancerad sökning efter filattribut, utan till och med ett resultatfönster som visar direktlänkar till de hittade filerna , liksom till mapparna som innehåller dessa filer. Resultatfönstret är inte särskilt informativ i den meningen att du bara kan läsa hela den hittade filen genom att starta den, det vill säga att den inte har en inbyggd filvisare. Men ett utdrag från filen där sökordet hittades visas, i allmänhet är ett sådant visningsschema mycket likt Internet -sökmotorer.
På tal om specifika möjligheter att bearbeta sökfrågor är det värt att notera att det inte finns något som heter "sök efter text", det maximala som du kan söka efter är en fras, om det bara är för att det inte finns något textinmatningsfält med flera rader. Ändå kan du analysera den inmatade frasen och Snooper erbjuder oss en standard sökuppsättning här: logiska operationer, masksökning och citatsökning ... inte mycket. Programmet innehåller några grundämnen för morfologisk sökning, men förmodligen är det så grovt att det snarare stör korrekt arbete (under testerna märktes många överlappningar med felaktig användning av morfologi).
Men programmet låter dig ange när du söker efter filattribut (dokumentdatum, filnamn, mappnamn), och i dessa frågor kan du också använda samma sökuppsättning. Du kan också söka efter bokstäver genom att ange parametrar (Från, Ämne .... etc.).
Så vi räknade ut med själva sökningen, vad mer är intressant med programmet, för vilket det fick så många utmärkelser, enligt information från den officiella webbplatsen? Det är svårt att säga vad som är så speciellt med det, troligtvis disponerar Snooper -gränssnittet sig själv (bara utåt, för att inte tala om användbarhet).
Indexoperationer är ganska standard, det fina är möjligheten att uppdatera indexen enligt ett schema. Dessutom kan index också användas på webben. Från och med nu behövs mer information.
Trots sökfrågornas primitivitet kan programmet användas för att hitta filer, så det kan motiveras i nätverk. Om än med en stor sträcka, eftersom i ett stort nätverk är den prioriterade uppgiften att snabbt söka efter data med hjälp av komplexa sökfrågor på grund av den enorma mängden information - men det finns helt klart problem med sökningens hastighet och programmet. Jag måste säga att Bloodhounds arbete med nätverket är genomtänkt. En separat applikation är speciellt utformad för detta - Snoop Server. Det fungerar på samma sätt som en enkel Snooper (de har en sökmotor), bara för dokument som finns på en central server eller på delade resurser i företagsnätverket. Snoop Server skapar nya index på delade resurser eller använder tidigare skapade. Alla användare i företagsnätverket kan ansluta till Snoop -servern och använda den för att komma åt alla dokument (som finns i det aktuella indexet) med en webbläsare. Håll med, det här schemat är extremt bekvämt: det visar sig att filer i ditt eget nätverk kan sökas på samma sätt som information på Internet via till exempel Google.
Genom att utvärdera alla fördelar och nackdelar med detta program, tyder slutsatsen själv att dess förmåga, troligtvis, inte kommer att räcka (trots ens en bra organisation av arbetet med nätverket), utan för en hemdator eller till och med för en hemnätverk, i princip kan det komma upp. Även om varken arbetshastigheten eller sökfunktionerna är uppmuntrande ...
Officiell webbplats på ryska:
Distributionsstorlek: 6 Mb Google Desktop Search + GDS Enterprise 
Naturligtvis kunde vi inte ignorera en så framstående utvecklare. Namnet Google säger redan mycket. Människor som har använt den mest kraftfulla Internet -sökmotorn i åratal kommer säkert att bestämma sig för att installera just den här sökmotorn på sin dator utan ett enda tvivel. Tänk efter: Google på din hemdator! Men utan att ge efter för provokationer med ett brett marknadsfört varumärke, låt oss försöka nyktert, och viktigast av allt objektivt, att överväga möjligheterna med en "stationär" sökmotor från Google.
Det första som fångar upp ögonen är frånvaron av ett eget skal för programmet. Google Desktop Search finns fortfarande i webbläsarfönstret, så hela gränssnittet för skrivbordsversionen fick programvaran från den äldre internetbror. Bra eller dåligt är en kontroversiell fråga: någon gillar minimalismen i utformningen av denna sökmotor, men någon vill se en fullfjädrad applikation fylld med alla typer av knappar och så vidare.
Vad får dig att blicka direkt efter designen? Och det faktum att samma Google Desktop Search börjar indexera allt på din dator, utan krav! Och det som är mest intressant är att det är omöjligt att välja indexeringsvägar med hjälp av Google Desktop Search. Du måste ladda ner ett separat program (TweakGDS), som gör att du kan expandera inställningarna för Google Desktop något, inklusive att ange de platser som är nödvändiga för indexering. Även om det kommer att indexera standardhårddisken tills du räknar ut det, så den här inställningen behövs snarare när du arbetar med stora mängder data, vilket är mycket viktigt när det används i företagsnätverk (Enterprise -version). Det är dock inte ett faktum att dina problem kommer att lösas efter nedladdning av TweakGDS. Det behöver trots allt Microsoft .NET Framework och Microsoft Scripting Runtime för att fungera. Ja ... installationen, liksom åtkomst till inställningarna, hade kunnat underlättas, även om utvecklarna kanske kan förstå: varför skriva något nytt, när det finns en färdig sökmotor, portat det till den lokala datorn och låt användaren "njuta", och ett välkänt namn kommer att göra "detta" till ett annat mästerverk. Kom igen, låt oss avsluta den lyriska digressionen om detta och gå vidare till sökningen.
När det gäller analys av sökfrågor och utfärdande av resultat är allt här helt identiskt med Google på Internet: samma system för att visa resultat, samma standarduppsättning logiska operationer för sökfrågor. I allmänhet är Google Desktop Search, precis som det föregående programmet, endast avsett för att hitta filer - det har naturligtvis ingen intern tittare för dessa filer. Antalet filformat som stöds av Google Desktop Search är tillräckligt, och det är också trevligt att det söker på de besökta internetsidorna och tar data från cacheminnet. Sök- och indexeringshastigheter är ganska acceptabla. Sant, för hemmabruk. Google Desktop Search klarade imponerande 20 gigabyte text på 8 timmar och 17 minuter. Att spendera flera dagar på att bearbeta information från ett stort företags företagsnätverk ler inte till någon systemadministratör. På plussidan: storleken på indexet som skapades visade sig ligga på nivån (4,5 GB) med en annan sökmotor testad i denna recension - SearchInform.
Den stora fördelen (eller förbise) med Google Desktop Search är att den stöder plugins som kan göra skillnad. En annan sak är att ansluta plugins och konfigurera dem komplicerar uppgiften att installera en sökmotor så mycket att du börjar undra om allt detta är nödvändigt när du kan installera ett normalt, fullvärdigt program där allt redan kommer att finnas. För att kunna använda varje funktion måste du installera ett nytt plugin. Även för att programmet ska kunna arbeta fullt ut med arkiv behövs en separat gadget. Freeness av alla dessa ytterligare moduler fascinerar och förför. Men om du inte tar hänsyn till skrivbordsversionen av sökmotorn, kanske kompetent installation av GDS Enterprise inte är inom din makt - trots allt är det inte för ingenting som experter från Google erbjuder sina tjänster för att skapa sina egna programvara för ditt nätverk för endast $ 10.000.
Om du fortfarande behärskar installations- och installationsproceduren (eller betalar $ 10.000 till teamet för snabba svar från Google -kontoret), kommer du att förstå att installationens komplexitet mer än kompenseras av mycket flexibla inställningar när de används i företagsnätverk. En viktig aspekt av arbetet med Google Desktop i ett företagsnätverk är användningen av grupppolicyer, vilket gör det möjligt att ställa in inställningarna för varje användare.
För att sammanfatta bör det sägas att den rimligaste applikationen för detta program är en hem- eller arbetsdator. För en vanlig dator räcker det verkligen med att helt enkelt installera programmet - det kommer att göra resten själv (det kommer inte ens att fråga dig om någonting).
Ändå kommer Google Desktop Search Enterprise att vara acceptabelt i de fall där det är ett akut behov av flexibel konfiguration av nätverkspolicy för att använda en sökmotor, medan möjligheten att bearbeta sökfrågor kommer på andra plats och den tid (eller pengar) som spenderas på installationen kommer programmet att vara i första hand. plats.
Officiell webbplats:
Distributionsstorlek med TweakGDS: 1,2 Mb Copernic Desktop Search 
Klicka på bilden för att förstora
Gränssnittet för programmet väcker extremt positiva känslor - allt görs i enlighet med allmänt accepterade standarder, inget överflödigt, i ett ord, en trevlig design. Det kommer att vara väldigt lätt för en nybörjare att förstå gränssnittet för Copernic Desktop Search. Även om det är lite pinsamt att konstruktörerna uttryckligen skapade programgränssnittet, med tanke på att programmet kommer att fungera i standard Windows XP -tema. När du använder det klassiska temat ser programmet inte så vackert ut längre. Men det här är mer en smaksak.
Vid första starten erbjuder programmet att skapa index för sökning. Det verkade något ovanligt att efter att ha valt mappar för indexering erbjuder programmet inte att trycka på någon knapp, till exempel "Starta indexering", och indexering startar inte automatiskt, först då märktes det att Copernic försökte starta indexering medan datorn var på tomgång. Du måste gräva lite i programalternativen för att ställa in allt korrekt. Det bör noteras att det finns ganska stora möjligheter att ställa in automatiskt indexskapande: inbyggd schemaläggare, indexeringsförmåga under dators viloläge, i bakgrunden, med låg prioritet. Indexering var inte särskilt snabb - 10 timmar 51 minuter - detta är långsammare än i andra sökmotorer (förutom Snooper är Copernic fortfarande en storleksordning snabbare än iSleuthHound Technologies utveckling.
Nu om indexets struktur. I allmänhet är det inget speciellt med det. Det finns ett urval av filtyper, både i en generell form och i en detaljerad. Det vill säga, inledningsvis kan du välja vad du vill indexera - dokument, bilder, videor, musik. På den andra fliken i alternativfönstret kommer det att vara möjligt att välja specifika filtyper med tillägg. Dessutom kan du konfigurera indexet så att till exempel bilder som är mindre än 16x16 i storlek inte indexeras eller ljudfiler som är kortare än 10 sekunder inte indexeras. Förutom att indexera filer från mappar kan Copernic arbeta med e -post och kontakter från adressboken för Microsoft Outlook och Microsoft Outlook Express, det är möjligt att indexera Favoriter och historik från Internet Explorer.
Sökmöjligheterna är svaga här. Under testerna avslöjades det till och med att programmet inte söker efter dokument i txt- och html -format på ryska, så att du bara kan hitta dem genom rubriker och inte på något sätt efter innehåll. Det enda som programmet tillhandahåller för att förbättra sökeffektiviteten är användningen av en standard uppsättning logiska operationer, och även då upptäcktes denna möjlighet experimentellt, eftersom den inte dokumenterades. Förresten, programmets hjälp är inte heller okej - den är endast tillgänglig via Internet, vilket du ser är mycket obekvämt och det finns inte för mycket hjälpinformation på nätverket. Uppenbarligen bestämde utvecklarna att programmets enkla gränssnitt inte innebär närvaron av normal hjälp. Vid fortsättning av konversationen om sökfunktioner bör det noteras att, trots den svaga analysen av frågor, erbjuder programmet ett intressant söksystem - användaren kan välja typ av filer (bilder, videor, musik, etc.), ange en sökning fråga och välj de attribut som finns i den valda filtypen. Till exempel för ljudfiler kan dessa vara värden från mp3 -taggar (artist, album, datum, etc.), för bilder, till exempel kan du välja deras storlek (efter upplösning), i allmänhet har varje typ sin egna inställningar. Efter att ha sökt efter en specifik filtyp kommer programmet att visa en mycket informativ lista i resultatfönstret, och om din begäran innehåller filer av andra typer kan du öppna dem genom att klicka på en specifik länk.
Separat är det värt att nämna resultatvisningsfönstret. Under listan över hittade filer visas innehållet i dessa filer (ett liknande schema används ofta i e -postklienter). Det är sant att text bara kan ses i sitt ursprungliga format och det finns inget visningsläge för vanlig text, vilket inte alltid är bekvämt, eftersom det tar längre tid att öppna ett dokument i det här fallet. Men med tanke på att Copernic kan söka efter bilder och musik är det möjligt att visa dessa multimediefiler.
De grundläggande principerna för detta program beskrivs, låt oss nu se vad Copernic Desktop Search kan erbjuda oss för att arbeta med nätverket ... I princip kan du titta på väldigt länge, men du kommer knappt att kunna se någonting. Med andra ord, det här programmet var inte avsett att vara nätverkande. Copernic Desktop Search är uteslutande en hemsökmotor.
Uppenbarligen är den enda (mest logiska) tillämpningen av detta program en hemdator. Här kommer den att klara alla enkla sökfrågor från användare som består av ett eller två ord, hitta den information du behöver och separationen av sökning efter filtyp och stöd för multimediefiler tillsammans med bakgrundsindexering i lågprioritetsläge, tillsammans med ett trevligt gränssnitt, ge bara programmet styrka att vinna förtroende bland oerfarna användare.
Officiell webbplats
Distributionsstorlek: 2,6 MbISYS Desktop 
Klicka på bilden för att förstora
Ett mycket kraftfullt program. När det gäller utrustningsnivån med alla möjliga funktioner är det någonstans nära nästa sökmotor i listan SearchInform. I detta fall är storleken på installationsfilen mer än 40Mb! Det är svårt att säga vad som kan passa i sådana storlekar, eftersom samma SearchInform, med liknande funktionalitet, tar 15Mb.
Installationsprocessen här är inte heller särskilt trevlig, eller snarare inte ens installationsprocessen. Innan du laddar ner programmet kommer du att bli ombedd att registrera dig, annars gör du det inte. Därefter gränssnittet. Den är gjord väldigt snyggt, men inget överflödigt fångar ögat, dock - det här är intryck av en person som redan är något van vid det. Det kommer inte att vara lätt för en nybörjare att ta reda på var och vad som finns, var man ska klicka och var man äntligen ska söka. Det rekommenderas starkt att läsa hjälpen innan du börjar arbeta - du sparar mycket nerver och tid. Till allt annat läggs den fullständiga bristen på stöd för det ryska språket i programmet. Inte bra. Dessutom är fönstren här inte överbelastade med kontroller, men priset som betalades för detta var multimodulariteten och användningen av ytterligare fönster. Till exempel anges sökfrågor med start av ett program och indexhantering utförs med ett annat program. Sökfrågor skrivs också in här i separata fönster. Vilket är bättre - ett överbelastat gränssnitt eller allestädes närvarande flera fönster - det är svårt att säga, snarare är det en smaksak.
När det gäller att skapa index har programmet funktioner som förenklar processen med att ställa in alternativ för ett nytt index. Dessa funktioner inkluderar flera färdiga mallar för att skapa index för mappen "Mina dokument", "E-post", "E-post och dokument", "Specifik mapp", "Mapp med val av filtyper" etc. Dessa mallar förenklar skapande av index i den första etappen. Verktyget för att arbeta med index har ett inte särskilt bra gränssnitt, vilket skrämmer bort en viss komplexitet (detta är en mycket subjektiv bedömning, för att vara ärlig), men om du tittar på det ger det många användbara alternativ och i allmänhet är det inte svårt att använda den. ISYS Desktop kan indexera data från olika datakällor och har också många flexibla inställningar för sådan indexering. Ytterligare indexeringsfunktioner inkluderar: stöd för SQL, FTP, TRIM Context, WORLDOX 2002, skript. När du skapar ett index, om du har valt "Mapp med ett urval av filtyper", har du möjlighet att välja filtyper för indexering manuellt (med tillägg). Jag måste säga att de filtyper som stöds helt enkelt är ett stort antal, men det kommer inte att vara möjligt att lägga till din egen typ (tillägg) till den befintliga listan. Du kan också notera närvaron av en indexeringsplanerare. ISYS Desktop tog 6 timmar 13 minuter att skapa ett index och bearbeta 20 gigabyte information, så småningom visade det sig bra tid och storleken på den skapade filen - 7,9 GB.
Sökfunktionerna i detta program är ganska bra. Den som används i ISYS är mycket kraftfullare än det vanliga stödet för logiska operationer. Av de avancerade sökfunktionerna erbjuder programmet användning av synonymer, ett sorteringsfilter (efter sökväg, namn och datum för skapande av filer). Uppsättningen av logiska operatörer är något bredare än standarduppsättningen. Förutom logiska operationer låter programmet dig arbeta med många andra operatörer, som i princip kan ersätta vissa typer av sökningar, till exempel kan analys av sökning ersättas med hjälp av speciella operatörer. Jag blev mycket förvånad över att det inte finns någon sökning med morfologi i programmet. Detta är en allvarlig försummelse, eftersom sökeffektiviteten förbättras kraftigt genom användning av morfologisk analys. Dessutom finns det ingen lista över meningsfulla ord, men det finns en omfattande lista över meningslösa ord. Sökfunktioner som "ungefärlig sökning" och "heuristisk analys" meddelas också.
ISYS erbjuder ett urval av flera typer av sökfrågor, nämligen typer - visuella. Detta görs med hjälp av olika typer av fönster för att ange sökfrågor, men i själva verket tillåter inget fönster användning av annan teknik än den som anges ovan.
Sökresultaten är mycket informativa och visas som en lista över dokument sorterade efter relevans. Nedan följer en förhandsvisning av det valda dokumentet. Till skillnad från Copernic Desktop Search är förhandsgranskning endast tillgänglig i vanlig text, det var inte möjligt att visa dokument i sitt ursprungliga format, vare sig det är Word, Html eller PDF, även om detta inte är för kritiskt i princip. Programmet låter dig dela upp de hittade dokumenten i grupper enligt vissa kriterier (som standard är de uppdelade efter relevans). Du kan också visa redan hittade dokument genom att välja separata mappar (detta är praktiskt när resultatet blir ett mycket stort antal dokument).
Användningen av programmet i ett företagsnätverk är också mycket motiverat, eftersom det ger goda möjligheter att organisera en nätverkssökning. Söksystemet är baserat på skapandet av ett offentligt index som innehåller indexerad data från offentliga nätverksresurser.
I själva verket är programmet från ISYS värt uppmärksamhet, åtminstone bekantskap med det. Detta program är ett moget projekt med ett stort antal funktioner (inte alltid och inte alla, naturligtvis behövs de, men ändå). Chansen att programmet kommer att få några förbättringar när det gäller behandling av sökfrågor är inte känt, men för närvarande kan det rekommenderas för nästan universellt bruk. Och med tanke på att det fortfarande är för tungt för hemsystem, är de viktigaste platserna för installationen företagsnätverk.
Officiell webbplats:
Distributionsstorlek: 40 MbSearchInform 
Klicka på bilden för att förstora
Du bör förmodligen inte börja med en beskrivning av SearchInform -gränssnittet direkt. Först bör du beskriva installationsprocessen, eller snarare en av dess detaljer: du kan inte installera programmet utan en internetanslutning. Faktum är att programmet före den första lanseringen kräver användarregistrering (gratis) och skickar alla inmatade data till servern. Uppenbarligen var utvecklarna tvungna att vidta sådana åtgärder i kampen mot piratkopiering, men detta hade ingen positiv effekt på enkel installation.
Programgränssnittet är gjort i enlighet med alla allmänt accepterade regler, men vid första anblicken är det något krångligt. Att använda programmet för första gången verkar det som att det är för komplicerat, ibland är det inte lätt att komma ihåg i vilken meny eller på vilken flik det önskade alternativet ligger, men vid längre användning verkar gränssnittet inte längre så fruktansvärt komplicerat . Det viktigaste är att läsa hjälpen först.
Med lite förståelse för gränssnittet kan du börja skapa indexet. Själva processen är mycket enkel och indexeringshastigheten, även med ögat, är mycket högre än alla andra sökmotorer från granskningen. De tydliga riktmärken visar att SearchInform två gånger har överträffat dtSearch och iSYS i indexeringshastighet! Programmet indexerade tillhandahållna data i mängden 20 gigabyte på en rekordtid - 3 timmar och 17 minuter. Och storleken på det skapade indexet visade sig vara det minsta 4,4 GB - 100 MB mindre än Google Desktop Search.
Programmet stöder, förutom vanliga filer och mappar, indexering av e-post, anslutning och indexering av databaser (!) Och andra externa källor (DMS, CRM), direkt under indexering kan du ange en ordlista för morfologisk sökning, och alla attribut kan indexeras filer. När du har skapat indexet kan du bli lite förvirrad när du försöker göra den första testsökningen av dokument: "det finns två typer av sökningar, men vilken behöver jag?". Som nämnts tidigare - det viktigaste är att läsa hjälpen, då blir allt klart. Programmet kan verkligen utföra två typer av sökningar - det här är en frasesökning och en sökning efter dokument som liknar innehållet i frågetexten.
Beskrivningen av alla huvudfunktioner för analys av en sökfråga gavs ovan, så nu kommer vi bara att lista de sökfunktioner som tillhandahålls av detta program. Låt oss börja med frasalsökning: naturligtvis, morfologisk sökning, citationssökning, logiska operationer, sökning av ord (sökning i början av ett ord, i slutet, i mitten eller en fullständig matchning), blandad citatsökning (när alla ord från frågan måste finnas i dokumentet, men inte nödvändigtvis i den angivna ordningen), sökning med felkorrigering, användning av synonymer, "nästan citationssökning" (söker efter den inmatade frasen som citat, men andra ord kan vara närvarande mellan de inmatade orden), etc. Några av de listade alternativen har sina egna specifika inställningar. Dessutom är det möjligt att använda en ordbok med obetydliga ord, och programmet har redan en färdig lista över dessa ord, och du kan också använda ordlistan med prioriterade ord för att söka (du måste naturligtvis fylla i det i dig själv).
Här gick vi i princip igenom alla de grundläggande möjligheterna för frasesökning.
Låt oss gå vidare till att överväga funktionerna i detta program - sökningen efter liknande dokument. Utvecklarna hävdar att detta absolut inte är en enkel sökning efter text, detta är just en "sökning efter liknande" - så beskrivs det överallt, men okej, du kan kalla det vad du vill - huvudpoängen. En kort sökning på Internet kan snabbt avslöja att så kallad "liknande sökning" är en ny utveckling inom textanalysområdet. Detta system låter dig hitta texter som liknar deras semantiska innehåll. Det trevligaste var att efter att ha genomfört testsökningar visade det sig att teori är ganska samma som praktik! Programmet söker faktiskt efter dokument med liknande innehåll och visar dem i en lista, sorterade efter likhetsprocent.
Därefter kommer vi att överväga vad SearchInform erbjuder (i synnerhet dess företagsversion SearchInform Corporate) för att arbeta i ett företagsnätverk. Det finns två typer av applikationer: back-end och användarsida. Serversidan behandlar de angivna indexen på egen hand, och användarna kan använda dem för att söka, beroende på åtkomsträttigheter som tilldelats dem. Användare kan konfigureras automatiskt med Windows -konton (på ett professionellt språk använder SearchInform Windows NTFS -autentisering) eller manuellt (användare måste läggas till separat). Varje användare kan tillåtas eller nekas åtkomst till vissa index, du kan också kombinera användare i grupper. I allmänhet ligger SearchInforms nätverksinställningar före Google när det gäller flexibilitet och Snoop Server när det gäller bekvämlighet och enkelhet.
Officiell webbplats:
Distributionsstorlek: 14,7 Mb Jämförelse av indexeringshastighet
| Sökmotor | Indexeringstid | Indexstorlek |
| Snoop Prof Deluxe 4.5 | 38 timmar 46 minuter | 19 GB |
| Isys Desktop 7.0 | 6 timmar 13 minuter | 7,9 GB |
| DtSearch 7.0 | 6 timmar 3 minuter | 8,6 GB |
| Google Desktop Search Enterprise | 8 timmar 17 minuter | 4,5 GB |
| Copernic Desktop Search * | 10 timmar 51 minuter | 7 GB |
| SearchInform 1.5.02 | 3 timmar 17 minuter | 4,4 GB |
* De flesta av de .html- och .txt -dokument som innehåller rysk text, även om de indexerades, men förutom efter deras namn, var det omöjligt att hitta dem.
Alla program är anmärkningsvärda.
Baserat på testerna och noggrann granskning av varje program som presenteras i granskningen kan vissa slutsatser dras. Så Google Desktop Search Copernic Desktop Search är ganska lämpligt för en oerfaren användare som ett heminformationssökningssystem. De gör ett bra jobb med enkla förfrågningar, överbelastar inte användaren med inställningar och är dessutom helt gratis. Googles försök att komma in på företagens sökmotormarknad är ännu inte mycket motiverat: för fullvärdig drift måste programmet hängas med ytterligare moduler, och det är långt ifrån enkelt att konfigurera. Därför talar namnen Desktop Search, det Copernic, som Google lämnar efter sig nischen med "stationära" sökmotorer.
Sant, mer kraftfulla lösningar - dtSearch, iSYS och SearchInform bakas inte heller och erbjuder användarna sina "stationära" versioner. Men till ett rimligt pris, till skillnad från gratis programvara från Google och Copernic. Naturligtvis måste du betala för kraft, hastighet och funktionalitet. Men huvudsyftet med utvecklarna av dtSearch, iSYS och SearchInform är naturligtvis på företagssektorn. Nätverk, funktionalitet, indexeringshastighet och sökning är det som skiljer dessa produkter från sina "konkurrenter". Enligt testresultaten bestämdes favoriten - SearchInform. Programmet ger möjlighet att söka efter liknande dokument, har den högsta indexerings- och sökhastigheten, har en bra uppsättning funktioner.
Hälsningar grabbar. Berätta hur mycket tid det tar för dig att hitta filer på din dator. Jag tänker mycket, och ännu mer om du bloggar på Internet eller bara en fotograf. I det här fallet samlas ett mycket stort antal filer. Det finns flera sätt att snabbt hitta den fil du vill ha. Till exempel så här eller så här
Det är bra om du säkert vet att de finns där. Och om du letar efter önskad fil och du säkert vet att den finns på din dator, och var och i vilken mapp? Jo, bara skleros kommer på besök. Och då hjälper FileSearchy -programmet oss. Se dess möjligheter.
Coolt program, jag använder det ofta själv och rekommenderar det till dig.
Det ser ut så här.  På vänster sida finns en sökruta där du måste ange namnet på den förlorade filen. Klicka sedan på knappen längst ner i programfönstret.
På vänster sida finns en sökruta där du måste ange namnet på den förlorade filen. Klicka sedan på knappen längst ner i programfönstret.
På mindre än fem sekunder kommer programmet att söka igenom alla hårddiskar och returnera alla filer som har namnet som du angav i sökmotorn. Du ser hur FileSearchy -programmet fungerar smart, och om du började söka manuellt skulle det definitivt inte passa in under den tid som programmet klarade av.
Så vi söker efter alla filer där det finns en matchning för vår begäran. Och det kan finnas många filer som innehåller samma ord och därför måste vi fortfarande slösa bort en del av tiden. I det här fallet ger programmet oss en avancerad sökning. Det vill säga förenklat.
Sök efter filer på din dator efter typ
Om vi bara behöver hitta bilder, letar vi efter bilder. Om bara mappar, då ber vi programmet att bara visa de hittade mapparna under det namn som vi registrerade i sökmotorn. I allmänhet sorterar vi. Hitta alla filer och ange sedan filtypen ,
genom att markera rutan. 
Detta sparar dig ännu mer tid. FileSearchy kan känna igen filtyper som bilder, ljud, video, dokument, program och mappar.
FileSearchy har också andra alternativ. Till exempel behöver vi bara filer från "D" -enheten. Under sökrutan sätter du en bock framför objektet "I katalogen" Vi söker på en viss plats och inte i hela datorminnet. Se bilden för hur detta görs.

Förresten, programmet tillåter oss att välja flera platser att söka på en gång. Tillåt det på hårddisken "E" och i en av mapparna på någon annan disk.
Du kan också uteslut från sökning vissa kataloger (diskar eller mappar). Det betyder att om du söker över hela datorn, kommer de kataloger som är uteslutna från sökningen helt enkelt inte att skannas och visas inte som ett resultat av sökresultaten.
 Observera att de mappar och enheter som inte skannas har ett utropstecken före enhetsbokstaven eller mappnamnet.
Observera att de mappar och enheter som inte skannas har ett utropstecken före enhetsbokstaven eller mappnamnet.  Så genom att klicka på pilen i sökningen vet vi vad som ska skannas och vad programmet kommer att kasta ut ur sökningen.
Så genom att klicka på pilen i sökningen vet vi vad som ska skannas och vad programmet kommer att kasta ut ur sökningen.
Tja, och några fler funktioner i det här programmet, som jag i princip väldigt sällan använder. Även om de i vissa fall kommer att vara mycket användbara.
Hitta filer i dokumentinnehåll
I sökparametrarna finns ett objekt "Innehåll" Detta sökläge är mer relaterat till sökningen efter textdokument. Låt oss säga att du har glömt hur dokumentet signerades. Till exempel laddades en bok ner från Internet, vars titel var på engelska eller i translitteration. Du vet inte hur du skriver det korrekt, men kom ihåg vilka ord som användes i det.

Och ytterligare två filter som kan tillämpas är sökning efter datum och storlek. Allt är klart här.
Den version jag använder.

Och som inte vill installera programmet på en dator, det finns en bärbar version av ett liknande program. Jag måste säga direkt att det inte är så attraktivt när det gäller gränssnitt, men det har sina egna intressanta funktioner.
Du kan ta reda på det och ladda ner från den officiella webbplatsen http://www.voidtools.com
Detta är användbart att veta:

Ett program för att snabbt söka efter filer i angivna mappar, både efter filnamn och innehåll. Den skiljer sig från standard Windows -sökfunktion i sin höga hastighet och effektivitet, liksom möjligheten att hitta filer även i arkiv!
Skärmdump galleri
Att arbeta vid en dator, på ett eller annat sätt, är förknippat med drift av en mängd olika textdata. Oavsett om vi letar efter information på Internet, skriver en årsrapport eller bara läser en bok - överallt hittar vi text!
Vi vet vanligtvis var alla våra arbetsfiler finns, eftersom vi öppnar dem nästan varje dag. Men ibland finns det situationer när vi kommer ihåg att någonstans hade vi ett dokument med nödvändig information, men vi glömde var det var och vad det hette.
Vi har två alternativ: du kan antingen manuellt försöka hitta filen du vill ha genom att öppna och kontrollera alla dina arbetsmappar, eller så kan du använda Windows -funktionen för att söka efter ett ord eller en fras.
Men om vi har många mappar och filer är det nästan omöjligt att hitta något manuellt, och det inbyggda sökverktyget kan bara söka i vanliga textfiler (Windows 7 vet dock redan hur man söker i DOC).
I det här fallet kan endast tredjepartsprogramvara som har avancerade sökfunktioner hjälpa oss. Alla program av detta slag kan delas in i två kategorier: de som använder indexeringsmekanismen och de som inte gör det.
De applikationer som inte använder indexering under skanning kontrollerar faktiskt varje gång att alla filer finns för söksträngen, det vill säga att de automatiskt implementerar en mekanism som liknar manuell sökning.
Ökningen av hastigheten i jämförelse med standardsökverktyget erhålls främst på grund av bättre parallellisering av förfrågningar till filsystemet, men det kan ta ganska lång tid.
Principen för indexering av filer på en lokal dator är i huvudsak densamma som på Internet. Programmet förskannar den angivna enheten eller mappen och skapar en databas med filer med möjlighet att snabbt hitta deras innehåll. På grund av detta sker sökningen på några sekunder!
Nackdelen med den här typen av program är deras fördel - behovet av indexering av filer, vilket tar ganska lång tid :(. Annars, enligt min mening, är den här klassen av program bättre och mer funktionell än sina motsvarigheter som fungerar utan index, så jag föreslår att du bekantar dig med en av de bästa gratisprogramvarorna i sitt slag - DocFetcher.
Idag finns det ganska många program för lokal indexering och filsökning, men alla har inte samma funktioner. När det gäller bredden i dess funktionalitet kan DocFetcher jämföras med det populära betalda indexeringssystemet Archivarius 3000.
Jämförelse med betald analog
Jämförelsen visar att programmen skiljer sig lite från varandra (förutom kanske gränssnittet). Båda programmen fungerar med nästan alla typer av filer, båda låter dig använda komplexa frågor som innehåller sökmasker.
Den enda fördelen med arkivaren är att den använder en beständig databas för indexering, vilket gör att du kan se innehållet i fjärrmappar och flyttbara medier som för närvarande inte är tillgängliga.
Även om det faktum att DocFetcher använder en dynamisk bas inte är en sådan nackdel, eftersom det automatiskt indexerar tillagda och borttagna filer, vilket gör att du alltid kan ha den senaste versionen av listan över alla arbetsfiler till hands.
Förbereder att arbeta med programmet
En ytterligare fördel med DocFetcher är tillgängligheten av en bärbar version, som rekommenderas för utvecklarna själva (även om det finns en). Utvecklarna rekommenderar att du använder den bärbara versionen av två skäl:
- Den bärbara versionen kan köras på alla populära system, eftersom den är skriven på det plattformsoberoende JAVA-språket och innehåller körbara filer för alla populära operativsystem (Windows, UNIX och Mac OS).
- Om du är van att bära med dig alla dina arbetsfiler på en flash -enhet eller extern hårddisk, kan den bärbara versionen indexera filer även på en flyttbar enhet, så att du kan hitta de filer du behöver så snabbt som på en dator . Återigen kan flash -enheten anslutas till vilken dator som helst med vilket operativsystem som helst, och överallt kommer vi att kunna göra en snabb sökning!
För egen räkning kommer jag att tillägga att den bärbara versionen fungerar lite snabbare (jag vet inte vad den är ansluten till) än installationsversionen, så jag rekommenderar också att använda den!
I arkivet som laddats ner från vår webbplats hittar du den bärbara versionen av programmet. För att det ska fungera är det bara att packa upp mappen "DocFetcher 1.1.9" var som helst på din dator (förutom mappen Program Files).
Du behöver också en uppsättning Java Runtime Environment (JRE) -bibliotek installerade på din dator, version 1.6.0 eller högre (för närvarande version 7.40 är aktuell). Vanligtvis är JAVA redan installerat på alla moderna system, men för säkerhets skull, kolla;)
När allt är klart kan du starta DocFetcher.
Programgränssnitt
Efter att ha kört den körbara DocFetcher.exe vi kommer att se programmets arbetsfönster:
![]()
Om ditt system är på ryska är programgränssnittsspråket automatiskt ryskt, så inget behöver ändras!
Själva gränssnittet består av fyra sektioner som kan döljas / visas med knapparna med svarta pilar:
- I det övre vänstra hörnet finns avsnittet sökalternativ. Här kan du ställa in minsta och högsta storlek på den sökte filen, samt ange dess tillägg (som standard är alla tillägg aktiva);
- I det övre högra hörnet av fönstret finns en sökfält med ett fält för att visa resultat. Här, till höger om sökfältet, kan du se ytterligare knappar som öppnar hjälp, inställningar och döljer programfönstret i facket.
- Sökområdet finns i nedre vänstra hörnet. Det är i detta avsnitt som alla indexerade mappar med våra arbetsfiler kommer att visas.
- I det nedre högra hörnet finns ett förhandsgranskningsfönster för den valda filen. Som standard visas programmet readme i det här fönstret, men så snart vi väljer en fil visas dess innehåll omedelbart här och sökfrasen eller ordet markeras i färg!
Mappindexeringsmekanism
Om du försöker hitta något just nu med hjälp av DocFetcher kommer du att misslyckas, för att programmet måste först indexera mapparna med de filer vi behöver!
För att göra detta måste vi ringa snabbmenyn i sökområdet och hålla markören över det enda aktiva objektet "Skapa index från":

Till exempel kommer jag att indexera min arbetsmapp med artiklar genom att välja "Mapp". Förutom mappar kan dock DocFetcher indexera arkiv, Outlook-e-postdatalagringsfiler och av någon anledning Urklipp.
Efter att ha valt indexeringsläget kommer vi att bli ombedda att ange en mapp för skanning, och sedan kommer vi att se följande fönster:

Här kan vi ställa in indexeringsparametrar, till exempel:
- speciella instruktioner för behandling av vissa typer av filer;
- exkludera vissa filer från indexet genom tillägg eller MIME -typ (reguljära uttryck stöds);
- andra avancerade inställningar.
Om du är en vanlig användare behöver du inte ändra något här. Om du är en utvecklare rekommenderar jag att du anger filerna som innehåller din kod som textfiler i avsnittet "Filtillägg".
Detta är nödvändigt för att DocFetcher ska kunna söka efter de nödvändiga uttrycken i koden (som standard bearbetas till exempel PHP -filer som HTML, det vill säga sökningen utförs endast på texten, tydligen i webbläsaren!) .
Om du är nöjd med alla inställningar, klicka på "Kör" -knappen och vänta tills indexeringen är klar:
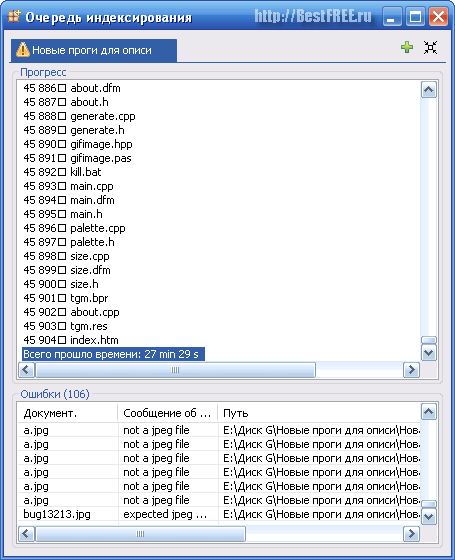
Det tar bara några sekunder att skanna små mappar med få filer. Men om mapparna är stora och har en komplex struktur av bilagor med arkiv och bilder, kan indexering ta ett tag.
Som du kan se från skärmdumpen bearbetade min arbetsmapp som väger 3,6 gigabyte, som skannern försäkrar oss, nästan 46 tusen filer (inklusive arkiv) DocFetcher bearbetade i nästan en halvtimme! Ganska lång, men värt det!
ja! Jag rekommenderar inte att indexera systemmappar (och Drive C, i allmänhet), eftersom detta för det första kommer att sakta ner programmet, och för det andra kan det till och med leda till en "blå skärm av döden" på grund av frekventa innehållsändringar. .
Och en sak till ... Ju fler filer i den indexerade mappen, desto mer RAM kommer programmet att konsumera för att behålla indexet. Mina 46 tusen filer, till exempel, i viloläge "slukar" upp till 200 megabyte RAM och upp till 20% av processorn! Och i sökläget händer det att alla resurser är inblandade (lyckligtvis tar sökningen bara ett par sekunder).
Tja, nu verkar du veta allt - låt oss komma till den roliga delen.
Enkel filsökning i DocFetcher
Efter att stänga skanningsfönstret kommer vi tillbaka till huvudfönstret igen, men nu kommer vi att ha en indexerad mapp i sökområdet:

Genom att klicka på plustecknet till vänster om mappnamnet, utökar vi dess struktur och vi kan se katalogträdet. Dessutom, tillsammans med vanliga mappar, innehåller trädet också arkiv, vars struktur vi också kan se!
Som standard kontrolleras alla mappar i den indexerade katalogen för sökning. Vi kan dock alltid begränsa sökfältet genom att bara markera nödvändiga kataloger eller arkiv.
Låt oss lämna hela mappen markerad och försök att ställa in det första sökordet. Till exempel, låt det vara ordet "Installatör"... Skriv in ordet i sökrutan och klicka på knappen "Sök":

Programmet tänkte i 3 sekunder och returnerade sedan en lista med 180 filer (se nedre vänstra hörnet för värdet "Resultat") där sökordet förekommer i samma form som vi angav.
Alla filer är som standard sorterade efter "Hit", som i procent uttrycker graden av relevans för varje fil för den angivna frågan. I vårt exempel tilldelades den maximala matchningsprocenten - 22% - till en fil där sökordet förekommer två gånger (dessutom i samma stycke).
Om du väljer den här filen i söklistan, kommer dess innehåll att visas i förhandsgranskningsfönstret, och den första matchningen som hittas markeras med blått (som ett vanligt urval). Efterföljande matchningar kommer att markeras med gult och kan snabbt navigeras till pilknapparna upp och ner i visningsportens verktygsfält.
På samma panel för vanliga textfiler finns det ytterligare två knappar som låter dig stänga av markeringen av sökresultat och aktivera / inaktivera HTML -visningsläget (om tillgängligt för denna filtyp).
Och det sista. Varje fil i listan över hittade kan öppnas med ett vanligt dubbelklick eller genom att använda snabbmenyn. Den senare innehåller också objekt som låter dig öppna överordnad mapp för filen eller kopiera själva filen till Urklipp.
Använda sökmasker
Avancerade (och ibland inte så) användare vet att du i sökmotorer på Internet kan söka inte bara med enkla sökfrågor utan också med en mängd specialfunktioner som gör att du kan inkludera / utesluta vissa ord i / från sökresultat, söka efter felaktiga matchningar , etc. .NS.
DocFetcher, i huvudsak samma sökmotor, men lokal, kan också göra det :). Till skillnad från de vanliga sökrobotarna söker den dock som standard endast efter strikta matchningar med frågan. För att komma runt denna begränsning måste du använda specialtecken «?» och «*» ... Låt mig förklara med ett exempel med ordet som redan nämnts ovan "Installatör":

Specialkaraktären "?" ersätter en bokstav. Det vill säga, om du lägger det i slutet av sökordet, kan vi hitta filer där det finns olika former av detta ord, där endast den sista bokstaven ändras (se skärmdumpen ovan: "installer", "installer" , etc.) ... Det bör dock komma ihåg att en sådan sökning inte hittar filer med sökformens grundform!
För en mer flexibel sökning, använd specialtecknet "*":

Denna symbol låter dig hitta resultat som är helt likvärdiga med frågan, eller som har olika ändelser som kanske inte består av en bokstav, som i föregående fall (till exempel filer med orden "installerare", "installatörer", "installatörer") "och till och med" installatör ").
Använd en asterisk när du vill matcha en fråga felaktigt!
Förresten, på skärmdumpen ovan kan vi se aktiveringen av HTML -kodbehandlingsfunktionen. I det här läget förvandlas förhandsgranskningsfönstret till en miniläsare med navigeringsknappar, en sökfält och alla erforderliga attribut. Du kan växla till kodvisningsläget med den yttersta knappen till höger.
Förutom att använda de ovan nämnda specialtecknen stöder DocFetcher några andra sökfunktioner:
- Boolska operatörer "OCH", "ELLER" och "INTE" (liknande "&&", "||" och "-") för sökningar som innehåller två sökord samtidigt, ett av sökorden eller uteslutande ett av orden . Till exempel: "cat && dog" - alla dokument finns där orden "cat" och "dog" finns, "cat OR dog" - dokument där det finns minst ett av orden "cat -dog" - dokument där det bara finns ordet "katt", utan att nämna ordet "hund". Du kan kombinera flera operatörer, till exempel "(katt ELLER hund) OCH mus" returnerar alla dokument som innehåller ordet "katt" eller "hund" och ordet "mus".
- Frasala specialtecken. Detta inkluderar citattecken och tecknet "+". Till exempel kommer en fras i citattecken att sökas oförändrad (den där du skrev ner den). Denna funktion liknar den exakta sökfunktionen i konventionella sökmotorer. Tecknet "+" indikerar att ordet markerat med det har prioritet, medan resten av frågorden kan saknas. Till exempel kommer frågan "+ katthund" först att ge oss alla filer, det finns båda sökorden och sedan de där det bara finns ordet "katt". Om du lägger till "+" till alla ord i frågan motsvarar resultatet att använda "OCH" -operatorn.
- Sök efter liknande ord. Med hjälp av DocFetcher kan vi söka efter filer som innehåller ord som liknar nyckelordet. För att göra detta, använd specialtecknet "~" i slutet av sökordet. Till exempel kan frågan "katt ~" ge oss orden "kod", "det", "svett", etc. Dessutom kan vi ange graden av likhet i intervallet från "0" till "1". Som standard (om vi inte har angett ett värde) är denna grad lika med "0,5" (motsvarar frågan "katt ~ 0,5").
- Sök efter filattribut. I praktiken är det ofta nödvändigt att hitta filer inte bara (och inte så mycket) efter deras innehåll, utan också efter vissa attribut. Till exempel vill vi hitta alla brev från Vasya Pupkin. För att göra detta kan du använda följande fråga: "avsändare:" Vasya Pupkin "". Tyvärr är attributsökning endast tillgänglig för textfiler (attribut: titel, filnamn och författare) och e -postfiler (attribut: ämne, avsändare och mottagare).
Det finns också vissa specifika sökfunktioner, men vi kommer inte att överväga dem på grund av deras låga efterfrågan (om du vill kan du läsa om dem i den engelska manualen för programmet i avsnittet "Frågesyntax").
Sökområdets snabbmeny
Jag funderade länge om det var värt att stanna kvar på snabbmenyn, men till slut, för att slutföra bilden, så att säga, bestämde jag mig för att sluta ändå :). Om du kommer ihåg, här i början hade vi bara det första objektet aktivt - "Skapa index från". Nu, efter indexering av mappen, blir alla andra alternativ tillgängliga för oss:

Om vi inte tar hänsyn till de uppenbara funktionerna, till exempel "Uppdatera index" eller "Radera" döda "index", kommer vi bara att vara intresserade av den sista posten i snabbmenyn - "Lista över dokument". Genom att aktivera det får vi inte resultatet av någon fråga i sökresultatfältet, utan en lista över alla filer i mappen för vilken funktionen att visa dokumentlistan kallades. Ibland kommer ett sådant tillfälle att vara användbart och till och med bekvämt!
DocFetcher -inställningar
Du kan komma in i de få inställningarna för programmet genom att klicka på den andra knappen till höger om sökfältet:

Här ska alla parametrar vara tydliga och utan ytterligare förklaringar. Det enda du bör vara uppmärksam på är länken "Avancerade inställningar" i nedre vänstra hörnet. Genom att klicka på den öppnas en textkonfigurationsfil där du kan göra några fina inställningar.
Tyvärr är kommentarerna till inställningarna (och de själva) på engelska, så jag råder dig att ändra något, bara om du har en klar uppfattning om vad den valda parametern kommer att påverka!
Fördelar och nackdelar med programmet
- nästan omedelbar sökning med filnamn och innehåll;
- förmågan att skriva komplexa frågor;
- sortera sökresultat efter relevans;
- sök i arkiv;
- förhandsgranskning av filinnehåll med förfrågningsmarkering.
- behovet av preliminär indexering av filer;
- som standard eftersträvas en strikt matchning, vilket inte alltid är bekvämt;
- hög resursförbrukning vid indexering av ett stort antal filer.
Slutsatser
DocFetcher är inte det enda programmet i sitt slag, utan ett av de mest funktionella, även i jämförelse med betald programvara.
Den enda allvarliga nackdelen, enligt min mening, är det faktum att applikationen är skriven i JAVA, som trots alla utvecklares uttalanden belastar systemet tungt. Naturligtvis, för moderna flerkärniga datorer är detta inget problem, men på gamla maskiner kan ibland "bromsar" observeras.
När det gäller resten är DocFetcher en utmärkt sökmotor, som på några få ögonblick kan hitta en viktig fil med bara ett ord som den innehöll. Programmet kommer också att vara oumbärligt för utvecklare, eftersom det låter dig söka efter komplexa kodkonstruktioner.
P.S. Det är tillåtet att fritt kopiera och citera denna artikel, förutsatt att en öppen aktiv länk till källan indikeras och författarskapet till Ruslan Tertyshny bevaras.