Full version Google-sökning. Använda Googles föga kända funktioner för att hitta vad som är dolt
Google (Google) är den största sökmotorn på Internet, som började fungera i september 1998.
Google ägs av det amerikanska företaget Google Inc. och rankas först i världen i popularitet med en indikator på 77%.
Google.ru - Hemsida
Det råder ingen tvekan om att huvudfunktionen hos Google.ru är att söka efter den nödvändiga informationen baserat på förfrågningar från användare. För att hitta den nödvändiga informationen behöver användaren bara ange önskat ord, fras eller mening i sökfältet. Efter detta klickar du bara på "Enter" på ditt tangentbord eller på förstoringsglasbilden direkt på sajten. Förresten, för att hitta nödvändig information på Internet kan du också använda portalen.
Det är ganska bekvämt att när man söker efter nödvändig information med Google.ru kan användaren ange önskade frågor inte bara direkt från tangentbordet på sin enhet, utan också använda tangentbordet på skärmen eller röstsökning, vilket utan tvekan är bekvämt och tillgänglig.

Google.ru - Tangentbord på skärmen
För att kunna komma åt Gmail, YouTube, Google+ och andra Google-tjänster behöver användaren bara skapa ett konto. Efter det, med en enda inloggning och lösenord för det, kan du besöka olika Google-tjänster.

Google.ru - Skapa konto
Det är värt att säga direkt att Google.ru har många tjänster och verktyg, som var och en har sitt eget syfte och applikation.
Det finns produkter vars uppgift är att göra arbetet på Internet enklare. Bland dessa finns den berömda webbläsaren Google Chrome.

Google.ru - Google Chrome
Produkter har utvecklats för mobila enheter (Sök, Maps) och specifikt för företag, som inkluderar AdWords, AdMob, AdSense och andra.
För dem som är intresserade av multimedia kommer YouTube, bildsökning och videosökning, böcker, nyheter och Picasa att vara användbara.

Google.ru - YouTube
Utan tvekan kommer tjänsten Google Maps, som är en karta och satellitbilder av jorden, att vara användbar. Det finns också en företagskatalog och en färdplan.

Google.ru - Google Maps
Detta är bara en del av de tillgängliga tjänsterna. Du kan se deras fullständiga lista direkt på webbplatsen Google.ru genom att klicka på ikonen "Tjänster" högst upp på sidan.

Google.ru - Tabs
För dem som tycker att detta inte räcker och behöver ännu mer information om Google.ru är det värt att besöka fliken "Allt om Google", som finns längst ner på sidan.

Google.ru - Tabs
Att skaffa privata data innebär inte alltid hacking – ibland publiceras det offentligt. Kunskap om Google-inställningar och lite uppfinningsrikedom gör att du kan hitta många intressanta saker - från kreditkortsnummer till FBI-dokument.
VARNING
All information tillhandahålls endast i informationssyfte. Varken redaktörerna eller författaren är ansvariga för eventuell skada orsakad av materialet i denna artikel.Idag är allt anslutet till Internet, med liten oro för att begränsa åtkomsten. Därför blir många privata data sökmotorernas offer. Spindelrobotar är inte längre begränsade till webbsidor, utan indexerar allt innehåll som finns på Internet och lägger ständigt till icke-offentlig information till sina databaser. Att ta reda på dessa hemligheter är lätt - du behöver bara veta hur man frågar om dem.
Letar efter filer
I kapabla händer hittar Google snabbt allt som inte finns på Internet, till exempel personlig information och filer för officiellt bruk. De är ofta gömda som en nyckel under en matta: det finns inga egentliga åtkomstbegränsningar, uppgifterna ligger helt enkelt på baksidan av sajten, dit inga länkar leder. Googles standardwebbgränssnitt ger bara grundläggande avancerade sökinställningar, men även dessa kommer att räcka.
Du kan begränsa din Google-sökning till en specifik filtyp med två operatorer: filtyp och ext . Den första anger formatet som sökmotorn bestämde från filtiteln, den andra anger filtillägget, oavsett dess interna innehåll. När du söker i båda fallen behöver du bara ange tillägget. Från början var ext-operatorn bekväm att använda i de fall där filen inte hade specifika formategenskaper (till exempel för att söka efter ini- och cfg-konfigurationsfiler, som kunde innehålla vad som helst). Nu har Googles algoritmer förändrats, och det finns ingen synlig skillnad mellan operatörerna – i de flesta fall är resultaten desamma.

Filtrera resultaten
Som standard söker Google efter ord och i allmänhet alla inmatade tecken i alla filer på indexerade sidor. Du kan begränsa sökområdet efter toppdomän, en specifik webbplats eller platsen för söksekvensen i själva filerna. För de två första alternativen använder du webbplatsoperatören följt av namnet på domänen eller den valda webbplatsen. I det tredje fallet låter en hel uppsättning operatörer dig söka information i tjänstefält och metadata. Till exempel kommer allinurl att hitta den givna i själva länkarna, allinanchor - i texten utrustad med taggen , allintitle - i sidtitlar, allintext - i brödtexten.
För varje operatör finns en lättviktsversion med ett kortare namn (utan prefixet all). Skillnaden är att allinurl hittar länkar med alla ord, och inurl hittar bara länkar med det första av dem. Det andra och efterföljande orden från frågan kan visas var som helst på webbsidor. Inurl-operatören skiljer sig också från en annan operatör med liknande betydelse - site. Den första låter dig också hitta vilken sekvens av tecken som helst i en länk till det sökta dokumentet (till exempel /cgi-bin/), som används flitigt för att hitta komponenter med kända sårbarheter.
Låt oss prova det i praktiken. Vi tar allintext-filtret och gör att begäran producerar en lista med nummer och verifieringskoder för kreditkort som kommer att förfalla först om två år (eller när deras ägare tröttnar på att mata alla).
Allintext: kortnummer utgångsdatum /2017 cvv 
När du läser i nyheterna att en ung hacker "hackade in på servrarna" hos Pentagon eller NASA och stal hemligstämplad information, talar vi i de flesta fall om just en sådan grundläggande teknik för att använda Google. Anta att vi är intresserade av en lista över NASA-anställda och deras kontaktinformation. Säkert finns en sådan lista tillgänglig i elektronisk form. För enkelhetens skull eller på grund av förbiseende kan det också finnas på själva organisationens webbplats. Det är logiskt att det i det här fallet inte kommer att finnas några länkar till det, eftersom det är avsett för internt bruk. Vilka ord kan finnas i en sådan fil? Åtminstone - fältet "adress". Att testa alla dessa antaganden är lätt.

Inurl:nasa.gov filtyp:xlsx "adress"

Vi använder byråkrati
Fynd som detta är en fin touch. En verkligt solid fångst tillhandahålls av en mer detaljerad kunskap om Googles operatörer för webbansvariga, själva nätverket och särdragen i strukturen för det som eftersträvas. Genom att känna till detaljerna kan du enkelt filtrera resultaten och förfina egenskaperna för de nödvändiga filerna för att få verkligt värdefull data i resten. Det är roligt att byråkratin kommer till undsättning här. Den producerar standardformuleringar som är bekväma för att söka efter hemlig information som av misstag läckt ut på Internet.
Till exempel betyder distributionsstämpeln, som krävs av det amerikanska försvarsdepartementet, standardiserade begränsningar för distributionen av ett dokument. Bokstaven A betecknar offentliga offentliggöranden där det inte finns något hemligt; B - endast avsedd för internt bruk, C - strikt konfidentiell, och så vidare tills F. Bokstaven X sticker ut separat, vilket markerar särskilt värdefull information som representerar en statshemlighet av högsta nivå. Låt de som ska göra detta i tjänst söka efter sådana dokument, så begränsar vi oss till filer med bokstaven C. Enligt DoDI-direktivet 5230.24 tilldelas denna märkning dokument som innehåller en beskrivning av kritiska teknologier som faller under exportkontroll . Du kan hitta sådan noggrant skyddad information på webbplatser i toppdomänen.mil, tilldelad för den amerikanska armén.
"DISTRIBUTIONSUTTALANDE C" inurl:navy.mil 
Det är mycket bekvämt att .mil-domänen endast innehåller webbplatser från det amerikanska försvarsdepartementet och dess kontraktsorganisationer. Sökresultat med en domänbegränsning är exceptionellt rena, och titlarna talar för sig själva. Att söka efter ryska hemligheter på detta sätt är praktiskt taget värdelöst: kaos råder i domains.ru and.rf, och namnen på många vapensystem låter som botaniska (PP "Kiparis", självgående vapen "Akatsia") eller till och med fantastiska ( TOS "Buratino").

Genom att noggrant studera alla dokument från en webbplats i .mil-domänen kan du se andra markörer för att förfina din sökning. Till exempel en hänvisning till exportrestriktionerna "Sec 2751", som också är praktiskt för att söka efter intressant teknisk information. Då och då tas den bort från officiella webbplatser där den en gång dök upp, så om du inte kan följa en intressant länk i sökresultaten, använd Googles cache (cache-operator) eller webbplatsen Internet Archive.
Att klättra upp i molnen
Förutom oavsiktligt avvisade myndighetsdokument, dyker ibland upp länkar till personliga filer från Dropbox och andra datalagringstjänster som skapar "privata" länkar till offentligt publicerade data i Googles cache. Det är ännu värre med alternativa och hemgjorda tjänster. Till exempel hittar följande fråga data för alla Verizon-kunder som har en FTP-server installerad och aktivt använder sin router.
Allinurl:ftp:// verizon.net
Det finns nu mer än fyrtio tusen sådana smarta människor, och våren 2015 var det många fler av dem. Istället för Verizon.net kan du ersätta namnet på vilken välkänd leverantör som helst, och ju mer känt det är, desto större kan fångsten bli. Genom den inbyggda FTP-servern kan du se filer på en extern lagringsenhet ansluten till routern. Vanligtvis är detta en NAS för fjärrarbete, ett personligt moln eller någon form av peer-to-peer-filnedladdning. Allt innehåll på sådana medier indexeras av Google och andra sökmotorer, så du kan komma åt filer som lagras på externa enheter via en direktlänk.

Tittar på konfigurationerna
Innan den utbredda migreringen till molnet styrde enkla FTP-servrar som fjärrlagring, som också hade en hel del sårbarheter. Många av dem är fortfarande aktuella idag. Till exempel lagrar det populära WS_FTP Professional-programmet konfigurationsdata, användarkonton och lösenord i filen ws_ftp.ini. Det är lätt att hitta och läsa, eftersom alla poster sparas i textformat och lösenord krypteras med Triple DES-algoritmen efter minimal förvirring. I de flesta versioner är det tillräckligt att bara kassera den första byten.

Det är lätt att dekryptera sådana lösenord med hjälp av verktyget WS_FTP Password Decryptor eller en gratis webbtjänst.

När man talar om att hacka en godtycklig webbplats betyder de vanligtvis att man skaffar ett lösenord från loggar och säkerhetskopior av konfigurationsfiler för CMS eller e-handelsapplikationer. Om du känner till deras typiska struktur kan du enkelt ange sökorden. Rader som de som finns i ws_ftp.ini är extremt vanliga. Till exempel, i Drupal och PrestaShop finns det alltid en användaridentifierare (UID) och ett motsvarande lösenord (pwd), och all information lagras i filer med tillägget .inc. Du kan söka efter dem enligt följande:
"pwd=" "UID=" ext:inc
Avslöja DBMS-lösenord
I SQL-servrarnas konfigurationsfiler lagras användarnamn och e-postadresser i klartext, och deras MD5-hashar skrivs istället för lösenord. Strängt taget är det omöjligt att dekryptera dem, men du kan hitta en matchning bland de kända hash-lösenordsparen.

Det finns fortfarande DBMS som inte ens använder lösenordshashning. Konfigurationsfilerna för någon av dem kan enkelt ses i webbläsaren.
Intext:DB_PASSWORD filtyp:env 
Med tillkomsten av Windows-servrar togs platsen för konfigurationsfiler delvis av registret. Du kan söka igenom dess grenar på exakt samma sätt, med reg som filtyp. Till exempel, så här:
Filtyp:reg HKEY_CURRENT_USER "Lösenord"= 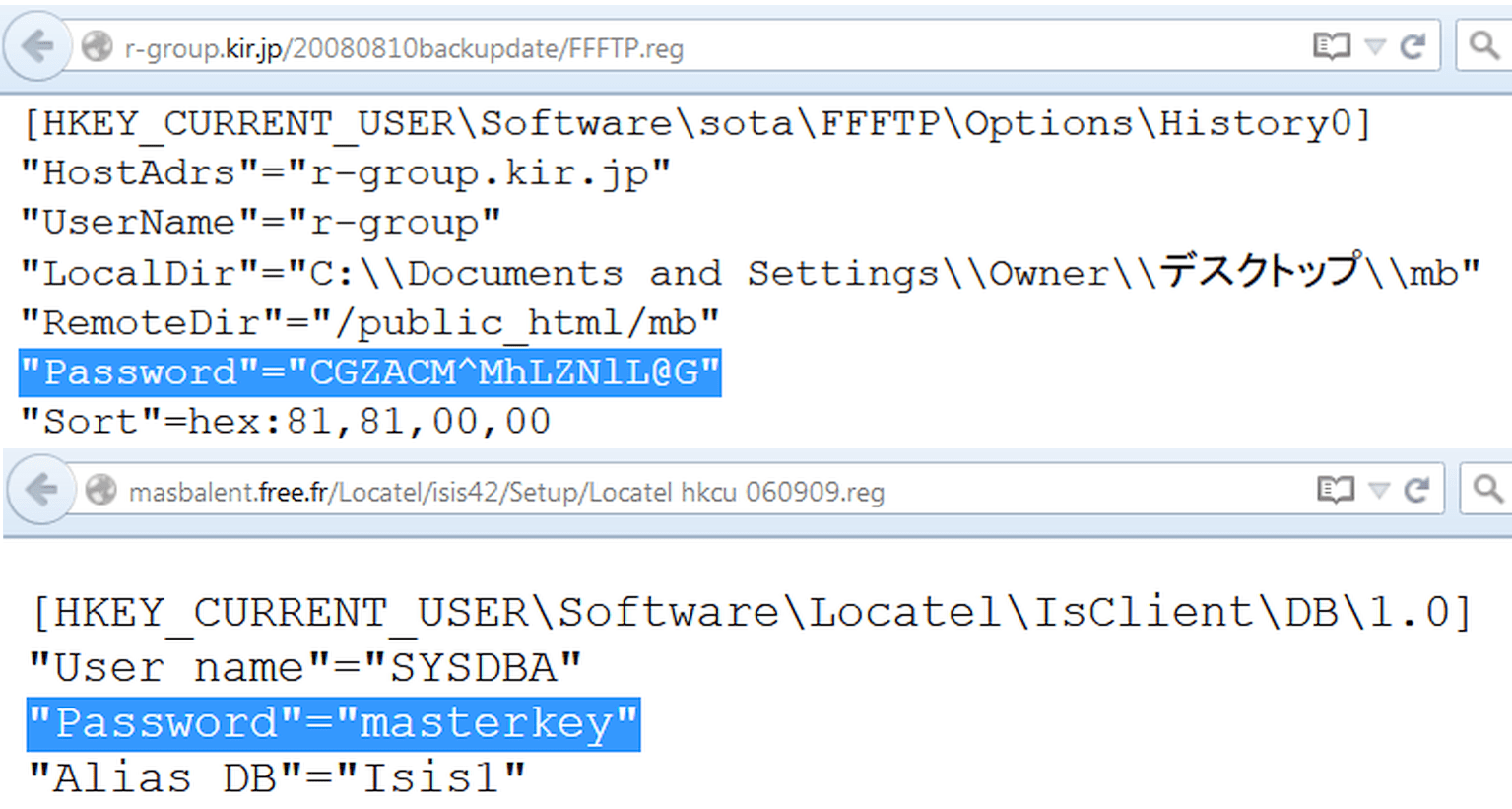
Låt oss inte glömma det uppenbara
Ibland är det möjligt att komma till hemligstämplad information med hjälp av data som av misstag öppnades och kom till Googles kännedom. Det perfekta alternativet är att hitta en lista med lösenord i något vanligt format. Endast desperata människor kan lagra kontoinformation i en textfil, Word-dokument eller Excel-kalkylblad, men det finns alltid tillräckligt med dem.
Filtyp:xls inurl:lösenord 
Å ena sidan finns det många medel för att förhindra sådana incidenter. Det är nödvändigt att specificera adekvata åtkomsträttigheter i htaccess, patcha CMS, inte använda vänsterhänta skript och stänga andra hål. Det finns också en fil med en lista över robots.txt-undantag som förbjuder sökmotorer att indexera de filer och kataloger som anges i den. Å andra sidan, om strukturen för robots.txt på någon server skiljer sig från standarden, blir det omedelbart klart vad de försöker dölja på den.

Listan över kataloger och filer på alla webbplatser föregås av standardindexet för. Eftersom det för tjänsteändamål måste finnas i titeln, är det meningsfullt att begränsa sökningen till intitle-operatören. Intressanta saker finns i katalogerna /admin/, /personal/, /etc/ och till och med /secret/.

Håll utkik efter uppdateringar
Relevans är oerhört viktigt här: gamla sårbarheter stängs väldigt långsamt, men Google och dess sökresultat förändras ständigt. Det finns till och med en skillnad mellan ett "sista sekund"-filter (&tbs=qdr:s i slutet av webbadressen för begäran) och ett "realtidsfilter" (&tbs=qdr:1).
Tidsintervallet för datumet för den senaste uppdateringen av filen anges också implicit av Google. Genom det grafiska webbgränssnittet kan du välja en av standardperioderna (timme, dag, vecka, etc.) eller ställa in ett datumintervall, men denna metod är inte lämplig för automatisering.
Från utseendet på adressfältet kan du bara gissa om ett sätt att begränsa resultatet av resultat med &tbs=qdr:-konstruktionen. Bokstaven y efter den sätter gränsen på ett år (&tbs=qdr:y), m visar resultaten för den senaste månaden, w - för veckan, d - för den senaste dagen, h - för den senaste timmen, n - för minuten, och s - för ge mig en sekund. De senaste resultaten som Google just har gjort kända hittas med filtret &tbs=qdr:1 .
Om du behöver skriva ett smart skript är det användbart att veta att datumintervallet är inställt i Google i julianskt format med hjälp av daterange-operatorn. Så här kan du till exempel hitta en lista över PDF-dokument med ordet konfidentiell, nedladdade från 1 januari till 1 juli 2015.
Konfidentiell filtyp:pdf datumområde:2457024-2457205
Intervallet anges i julianskt datumformat utan att ta hänsyn till bråkdelen. Att översätta dem manuellt från den gregorianska kalendern är obekvämt. Det är lättare att använda en datumomvandlare.
Inriktning och filtrering igen
Förutom att ange ytterligare operatorer i sökfrågan kan de skickas direkt i länkens brödtext. Till exempel motsvarar filtyp:pdf-specifikationen konstruktionen as_filetype=pdf . Detta gör det bekvämt att fråga eventuella förtydliganden. Låt oss säga att resultatet av resultat endast från Republiken Honduras specificeras genom att lägga till konstruktionen cr=countryHN i sökwebbadressen, och endast från staden Bobruisk - gcs=Bobruisk. Du kan hitta en komplett lista i utvecklarsektionen.
Googles automationsverktyg är utformade för att göra livet enklare, men de skapar ofta problem. Till exempel används en användares IP för att fastställa deras stad via WHOIS. Baserat på denna information balanserar Google inte bara belastningen mellan servrar, utan ändrar också sökresultaten. Beroende på region, för samma begäran, kommer olika resultat att visas på första sidan, och några av dem kan vara helt dolda. Koden på två bokstäver efter gl=country-direktivet hjälper dig att känna dig som en kosmopolit och söka information från vilket land som helst. Nederländernas kod är till exempel NL, men Vatikanen och Nordkorea har ingen egen kod i Google.
Ofta hamnar sökresultaten röriga även efter att ha använt flera avancerade filter. I det här fallet är det lätt att förtydliga begäran genom att lägga till flera undantagsord till den (ett minustecken placeras framför var och en av dem). Till exempel används banktjänster, namn och handledning ofta med ordet Personal. Därför kommer renare sökresultat inte att visas av ett läroboksexempel på en fråga, utan av ett förfinat:
Intitle:"Index för /Personligt/" -namn -tutorial -bank
Ett sista exempel
En sofistikerad hacker kännetecknas av att han förser sig själv med allt han behöver på egen hand. Till exempel är VPN en bekväm sak, men antingen dyrt eller tillfälligt och med restriktioner. Att teckna ett abonnemang för dig själv är för dyrt. Det är bra att det finns gruppabonnemang och med hjälp av Google är det lätt att bli en del av en grupp. För att göra detta, hitta bara Cisco VPN-konfigurationsfilen, som har ett ganska icke-standardiserat PCF-tillägg och en igenkännbar sökväg: Program Files\Cisco Systems\VPN Client\Profiles. En förfrågan och du går med, till exempel, det vänliga teamet vid universitetet i Bonn.
Filtyp:pcf vpn ELLER Grupp 
INFO
Google hittar lösenordskonfigurationsfiler, men många av dem är krypterade eller ersatta med hash. Om du ser strängar med en fast längd, leta omedelbart efter en dekrypteringstjänst.Lösenord lagras krypterade, men Maurice Massard har redan skrivit ett program för att dekryptera dem och tillhandahåller det gratis via thecampusgeeks.com.
Google kör hundratals olika typer av attacker och penetrationstester. Det finns många alternativ som påverkar populära program, stora databasformat, många sårbarheter i PHP, moln och så vidare. Att veta exakt vad du letar efter kommer att göra det mycket lättare att hitta den information du behöver (särskilt information som du inte hade för avsikt att offentliggöra). Shodan är inte den enda som matar med intressanta idéer, utan varje databas med indexerade nätverksresurser!
Tryck inställningsikonen inställningar.
En ny flik öppnas.

Google.
Lägg till.
OK.

Tryck inställningsikonen i det övre högra hörnet och välj inställningar.
En ny flik öppnas.


Steg 2: Gör Google till din standardsökning
I avsnittet Sök väljer du från rullgardinsmenyn Google.
Steg 3: Gör Google till din startsida
Under Starta grupp väljer du Nästa sidor: och klickar Lägg till.
Ange www.site i fältet som visas. Klick OK.
Stäng fliken Inställningar. Ändringar sparas automatiskt.

Gör Google till din standardsökning
Klick nedåtpil till vänster i sökfönstret.
Välj Google i rullgardinsmenyn.


startsida
Ja.
Klicka på Firefox i det övre vänstra hörnet och välj sedan alternativ, och klicka sedan på alternativ i den högra menyn.
Klicka på Allmän knappen i toppmenyn med bilden av en strömbrytare.
Bredvid När Firefox startar, öppna rullgardinsmenyn och välj Visa min hemsida.
Skriv www.site i Hemsida rutan och klicka OK att spara.

Steg 1: Gör Google till din standardsökning
Klick nedåtpil till vänster i sökfönstret.
Välj Google i rullgardinsmenyn.


Dessutom: Gör Google till din startsida
Använd musen och dra den blå Google-ikonen som visas nedan till ikonen startsida, som finns i det övre högra hörnet av din webbläsare.
Klicka sedan i popup-fönstret Ja.
...eller ändra startsidan manuellt
Välj Firefox från menyraden och klicka sedan på Inställningar.
Skriv www.site i Hemsida och stäng fönstret Inställningar för att spara.

Steg 1: Öppna webbläsarinställningarna
Klick Safari från Apple-menyn och välj inställningar.


Steg 2: Gör Google till din standardsökning
I rullgardinsmenyn Huvudsökmotor Välj Google.
Steg 3: Gör Google till din startsida
Bredvid Nya fönster öppnas med, öppna rullgardinsmenyn och välj Hemsida. Öppna nästa rullgardinsmeny och välj Hemsida för att se din startsida i nya flikar.
Skriv sedan www.site i rutan bredvid Hemsida.
Dina ändringar sparas.

Steg 1: Öppna webbläsarinställningarna
Klick Opera i toppmenyn och välj inställningar, och då Allmänna Inställningar.Inställningar, inställningar eller alternativ. Om det finns ett objekt i huvudmenyn Service, klicka på den och välj Internet-alternativ.
Vårt råd: ladda ner , en snabb och gratis webbläsare. Google Chrome öppnar webbsidor och applikationer blixtsnabbt.
skapelsehistoria
Googles sökmotor skapades som ett utbildningsprojekt av Stanford University-studenterna Larry Page och Sergey Brin. De arbetade på BackRub-sökmotorn 1995, och 1998 skapade de Googles sökmotor utifrån den.
Webbplatsindexering
Rangordningsalgoritm
Metataggen Keywords tas inte med i beräkningen när webbplatser rankas.
PageRank
Google använder en algoritm för att beräkna auktoriteten för en sida, PageRank. PageRank är en av hjälpfaktorerna för att rangordna webbplatser i sökresultat. PageRank är inte det enda, utan mycket viktiga sättet att bestämma positionen för en webbplats i Googles sökresultat. Google använder PageRank för sidor som hittas för en fråga för att avgöra i vilken ordning dessa sidor visas i sökresultat för en besökare.
Sökfrågor
Fråga syntax
Googles gränssnitt innehåller ett ganska komplext frågespråk som låter dig begränsa din sökning till specifika domäner, språk, filtyper etc. Om du till exempel söker efter "intitle:Google site:wikipedia.org" kommer alla Wikipedia-artiklar på alla språk att returneras som har ordet i titeln Google.
Sökning hittades
För vissa sökresultat tillhandahåller Google ett upprepat sökfält som gör att användaren kan hitta det de letar efter på en specifik webbplats. Denna idé kom från hur användare använde sökning. Enligt mjukvaruingenjören Ben Lee och produktchefen Jack Menzel är "teleportering" på webben det som hjälper Google-användare att slutföra sina sökningar. Google har tagit detta koncept ett steg längre och istället för att bara "teleportera", vilket innebär att användare bara behöver skriva in en del av webbplatsens namn i Google för att hitta den webbplats de vill ha (de behöver inte komma ihåg hela adressen), användare kan ange nyckelord för att söka på den valda webbplatsen. Det visade sig att användare ofta har svårt att hitta vad de letar efter på en företagswebbplats.
Även om det här sökverktyget är nytt för användare, har det orsakat kontroverser bland vissa utgivare och distributörer. Googles sökresultatsidor visar betalda (betala per klick) annonser från konkurrerande företag som baserar sina annonser på varumärken. "Medan tjänsten kan hjälpa till att öka trafiken, "läcks" vissa användare eftersom Google använder varumärkesigenkänning för att sälja annonser, vanligtvis till konkurrerande företag." För att jämna ut denna konflikt föreslog Google att den här funktionen skulle inaktiveras för företag som vill göra det.
Anteckningar
se även
Länkar
| Google Inc. | |
|---|---|
| Reklam | |
| Kommunikationer | |
| FÖRBI | |
| Plattformar | |
| Under utveckling verktyg |
|
| Offentliggörande | |
| Sök(PageRank, handböcker) |
|
| se även | |
Wikimedia Foundation. 2010.
Hej kära läsare av bloggsidan. För ett par månader sedan skrev jag om funktionerna i marknadsföring specifikt för den här sökmotorn och hävdade att jag inte kan låta bli att betala tillbaka samma mynt till företaget som tar med mer än hälften av alla besökare till min blogg. Vad tror du har hänt sedan dess?
Just det, allt vändes upp och ner och nu får Google mer än hälften av alla besökare till min blogg. Jag är lite rädd att han efter den här artikeln också kommer att vända mig ryggen, men jag tar ändå risken. Även om det är värt det, för nu är det ett av de dyraste och mest lovande företagen i världen.
Och kvaliteten på själva Google-sökningen är på många sätt överlägsen analogen från Runet-spegeln (läs om det), men majoriteten sitter fortfarande i Yandex huvudsakligen av vana (som jag faktiskt).
Historik för sökmotorn Google.com
Så historien om utvecklingen av detta företag kan börja räknas från 1996, även om sökmotorn officiellt började fungera först hösten 1998 (det visar sig att Googlers var ett år efter Yandex, men ändå lyckades komma ikapp med allt).
Det var 1996 som prototypen av dagens sökmotor började arbeta på campus vid Stanford University, där Sergei Brin och Larry Page, nu välkända i världen, studerade på forskarskolan vid den tiden.
Båda dessa herrar föddes 1973 (praktiskt taget i min ålder) och båda kom från professorsfamiljer med judiska rötter. Mödrar och fäder till båda Google-grundarna var engagerade i matematik (undervisad) och datorteknik, vilket i själva verket väckte deras barns intresse för dessa vetenskapsområden. Både Sergey Brin och Larry Page har alltid prioriterat att få en specialiserad utbildning av hög kvalitet (bra jobbat, vad kan jag säga).
De hade dock en skillnad i ursprung. Sergey Brin föddes i Sovjetunionen i den ärorika staden Moskva och fördes 1979 av sina föräldrar till staterna under emigrationsprogrammet för judiska familjer. Och Larry Page var redan ursprungligen en född amerikan, även om detta i själva verket inte är så viktigt, eftersom Sergei bara var sex år gammal när han slutade vara vår landsman. Det som är anmärkningsvärt är att Brin fortfarande talar ryska mycket bra.
Om du har läst historien om Yandex, har du förmodligen märkt att det i huvudsak verkade som en utveckling av ämnet som dess skapare var engagerade i när de var vetenskapsmän. Detsamma kan sägas om Google.com. Brin och Page, medan doktorander vid Stanford, arbetade med att lösa problemet med att söka igenom stora, ostrukturerade datamängder. Till en början ville de knyta detta till något relaterat till att identifiera de mest populära varorna, men problemet med att söka på Internet dök upp med tiden.
De sökmotorer som fanns tillgängliga vid den tiden kunde knappast klara av sin uppgift. Sökresultaten hade en mycket låg korrelation med vad användaren ville se som svar på sin fråga. Faktum är att då var huvudmarkören (faktorn) som det utfördes i sökresultaten ord frekvens från en användarförfrågan i ett dokument.
Det är tydligt att ett sådant urvalskriterium är mycket lätt att fuska från webbansvariga genom att helt enkelt öka illamåendet av texter. Kan du föreställa dig hur lång tid som redan har gått sedan textspam dök upp, vilket sökmotorer först nu på allvar har börjat bekämpa och utrota (eftersom andra faktorer har dykt upp som avsevärt kan minska betydelsen av frekvensen av förekomst av nycklar i texten vid rankning ).
Här har du. Från barndomen såg och förstod Larry Page, med sina föräldrars exempel, som rörde sig i vetenskapliga kretsar, att auktoriteten hos en viss vetenskapsman till stor del beror på hur många vetenskapliga verk som refererar till honom som en primär källa eller som en auktoritativ specialist. Ju fler länkar, desto mer auktoritativt namn på vetenskapsmannen. Logisk?
Naturligtvis är det logiskt, men vad har Google med det att göra? Faktum är att Page hade idén att överföra detta rankingsystem till internetsökning. Han förknippade forskare med enskilda dokument (inte webbplatser, utan enskilda webbsidor), och länkar på Internet har funnits sedan 1989 (förresten, ett par år senare var det Tim som grundade).
Tja, som ett resultat dök en välkänd rankningsfaktor upp, som fortfarande beaktas av sökmotorer - PageRank. Denna term är sammansatt. Rank betyder rankning, men Page kan betyda antingen en webbsida i den engelska stavningsvarianten, eller det faktum att denna rankningsparameter uppfanns av ingen mindre än Page (som är Larry).
Men det är inte meningen, eftersom PageRank gjorde en revolution och gjorde det möjligt att höja kvaliteten på framtidens Googles sökning till ouppnåeliga höjder. I allmänhet, för allmän utveckling, kan du läsa en artikel om , där jag försökte förklara deras väsen med mina fingrar, eller titta diagonalt på min största skapelse på den här bloggen, som är helt tillägnad specifikt.
PR gjorde det möjligt att ta hänsyn till när dokument rangordnas inte bara kvantiteten utan också kvaliteten på länkar som leder till en viss webbsida. Tja, kvaliteten på länken berodde följaktligen på antalet inkommande bakåtlänkar till givarsidan (i SEO kallas en donator vanligtvis den som länken kommer från, och en acceptor är den som den placeras till) .
De där. Det är här begreppet statisk vikt av sidor på Internet dyker upp, enligt vilken kvaliteten på länkar som leder från dem bedöms. All denna skam beräknades av Google i flera omgångar (iterationer) och var (åtminstone på den tiden) en utmärkt rankningsfaktor. I allmänhet är ämnet PageRank inte så uppenbart, så för en detaljerad bekantskap måste du läsa artiklarna som nämns ovan.
Nåväl, låt oss gå tillbaka till Googles historia och se hur två begåvade herrar från demokratins högborg lyckades väcka idén om att rangordna dokument från det globala nätverket till liv och slentrianmässigt tjäna tjugo miljarder dollar på det (även om detta för dem var inte ett mål i sig, utan blev helt enkelt ett resultat av deras arbete, som det vore dumt att vägra).
Först och främst, för att kontrollera funktionaliteten i beräkningsprogrammet Page Rank, var det nödvändigt att få en enorm mängd data. Larry Page bestämde sig för att han kunde för detta ändamål ladda ner hela Internet till din dator, som lämnade sina ledare i förvirring.
Men med medel från Stanford University kunde Larry och Sergey sätta ihop det erforderliga antalet datorer från komponenter (detta gjorde det möjligt för samma pengar att få tre gånger mer hårdvara än genom att köpa redan monterade servrar) och starta sin spider (en program som kopierar webbsidorna det hittade på Internet).
Förresten, jag noterar att Larry och Sergey förblev trogen sin idé - Google är nu nummer ett datormontör i världen(avsevärt före Dell och HP) utan att sälja en enda server, utan att använda dem alla för sina datacenter, som enligt ungefärliga uppgifter redan har mer än en miljon enheter över hela världen. Detta gör att de kan få betydligt högre produktivitet till samma kostnad och utan att spara på redundans, vilket gör det till den absoluta ledaren när det gäller hastighet och tillförlitlighet.
Men låt oss återvända till historien igen. Så, som ett resultat, började Brin och Pages idé att fungera som ett sökverktyg för alla användare av Stanford University. Sergey och Larry bad sina första användare att uttrycka sina intryck och kommentarer om sökoperationen, försökte ta hänsyn till dem och förfina dem (i själva verket var detta alfatestningsstadiet). Sökningen blev tillgänglig 1997 kl google.stanford.edu. En ansökan lämnades in från Stanford för sökteknik med hjälp av PageRank.
Som du kan se använder webbadressen redan ordet Google (även om det fanns en tid då sökalgoritmen hette BackRub, eftersom den var baserad på bakåtlänkar), som uppfanns dagen innan som ett av de möjliga namnen på sökmotorn . Ursprunget till detta ord beror på felstavning term Googol, som betecknar ett knepigt tal som består av ett och hundra nollor efter det.
I allmänhet fanns det först ett förslag om att kalla sökningen GooglePlex (i korrekt stavning Googolplex - tio till makten av googol), men det verkade för långt och de bestämde sig för den nämnda termen (av någon anledning skrevs den felaktigt som ett resultat, men de ändrade det inte längre, eftersom .k-domänen förvärvades nästan omedelbart av Google.com). Med detta namn ville skaparna förmodligen betona eller förutsäga den enorma indexbasen för den framtida världssökledaren.
Google och Yandex - gemensamma punkter i utveckling och bildning
Ett utmärkande drag för Googles huvudsida vid den tiden var dess fullständiga askes, som finns kvar till denna dag. Jämför (där ibland kan du se en banner under sökfältet, kostnaden för att placera den i en vecka är lika med kostnaden för en lägenhet i Moskva):

Och titta på huvudsidan för Google.ru:

Som de säger, känn skillnaden. Under det avlägsna nittiotalet var alla sajter och portaler fulla av färgglada banderoller och inskriptioner (ala dagens Terekhoff, och jag är inte heller utan synd), vilket orsakade genuin irritation hos Larry och Sergei. När Sergey Brin arbetade med utformningen av huvudsidan för sin sökning, använde Sergey Brin därför principen om minimalism, och tillät sig bara att måla bokstäverna i Google-logotypen i olika färger.
Det blev bra, men det blev ett kuriöst fall när testgruppen, som fick i uppdrag att hitta något där genom Google.com, satt i flera minuter framför datorskärmen med en ganska förbryllad blick. Det visar sig att de väntade på att huvudsidan skulle laddas helt (det fanns inga sajter i minimalistisk stil på Internet vid den tiden).
Därför var utvecklarna tvungna att öka typsnittet längst ner på huvudsidan så att det skulle bli en slags markör för användarna när sidan har laddats klart.
Vet du vad som är det mest intressanta i Googles historia? Att det kan sluta runt den här punkten. Som jag nämnde tidigare, för Sergei och Larry var det viktigaste att få en kvalitetsutbildning, och arbetet med sökmotorn tog upp hela tiden och lämnade ingen tid för att studera. Vad tror du att de kom fram till?
Säkert, sälja alla rättigheter om användningen av PageRank-teknik och sätta stopp för utvecklingen av Google-projektet. Det som är anmärkningsvärt är att de erbjöd sin produkt för en relativt liten mängd av en grön citron till så välkända titaner på den tiden som AltaVista, och andra företag som inte längre är kända. Anmärkningsvärt nog lyckades AltaVista till och med sänka priset med en fjärdedel, men köpte det ändå inte.
Efter detta bestämde sig Larry Page och Sergei för att trots allt sluta studera (många av oss tog samma beslut även av mycket mindre övertygande skäl) och började noggrant förfina och främja ett innovativt, på den tiden, söksystem med ett okänt namn till vem som helst som Google.
Det hela berodde på att för utveckling behövde vi pengar för att köpa servrar. Utan detta hade det varit omöjligt att gå vidare, för även med Googles relativt låga popularitet vid den tiden, krävde det redan ganska stora resurser för att lagra och behandla många användarförfrågningar i farten.
Så låt mig påminna dig om att domänen registrerades i september 1997, och exakt ett år senare var den redan registrerad Google Inc.. Några dagar tidigare lyckades Sergey Brin och Larry Page få sin första utvecklingscheck från en kompetent kille från Sun Microsystems. De säger att när checken utfärdades existerade företaget som sådant ännu inte, därför, efter att ha angett namnet på checken, var det redan under den officiella registreringen av företaget nödvändigt att fokusera på detta namn (annars skulle det ha funnits problem med att ta ut pengar).
Detta belopp spenderades på inköp av komponenter och montering av nya servrar, som utformades för att behandla det ständigt ökande antalet förfrågningar till Google.com, eftersom sökmotorns popularitet växte. Även trots att inskriptionen Beta fortfarande dök upp på deras huvudsida i slutet av 1998, hade ledande medier som skrev om IT-teknik redan uppmärksammat den unga sökmotorn och uttryckt sina positiva recensioner om dess arbete.
Populariteten för Googol växte och de hundratusen gröna som mottogs spenderades snabbt på komponenter. Killarna slog igen en vägg, men de lyckades återigen göra det otroliga - få tjugofem lyams gröna pengar för utveckling från två riskkapitalföretag, utan att driva sig själva i träldom (att lämna förbehåller sig full rätt att leda företaget och lösa alla problem efter eget gottfinnande). Bra gjort, vad kan jag säga.
Än en gång tröttnar jag aldrig på att dra paralleller mellan utvecklingen av borgerliga och ryska sökningar. Arkady Volozh och Ilya Segalovich tvingades på samma sätt söka pengar för utveckling från investerare och lyckades på samma sätt försvara sin rätt att styra företaget efter eget gottfinnande.
I allmänhet har Yandex och Googles ideologer mycket gemensamt (smarta, utbildade och intelligenta människor) och det viktigaste som förenar dem är önskan, först och främst, att utveckla sina projekt (och få en buzz från det), och inte dumt tjäna pengar (men inte utan det):

Det är klart att detta inte kunde fortsätta i all oändlighet. Projektet måste generera inkomster eller åtminstone vara på självförsörjningsnivå. Det finns sant att det finns exempel på stora internetprojekt som inte tjänar pengar på sin idé. . Men andra rika företag, vars ägare förstår vikten av Wiki för Internet, hjälper det att hålla sig flytande.
Google är ett så förstående företag som donerar flera lyams till Wiki. Förresten, ägaren till det sociala nätverket "" hotade också nyligen att ge Wikipedia omkring en miljon dollar grönska, vilket gör honom ära och sätter honom i nivå med de stora.
Men Google (liksom Yandex) vågade inte följa den legosoldats väg. Sergey Brin och Larry Page var tvungna att ge upp lite om principerna om att inte acceptera reklam på sidorna av deras idé. Men de gjorde det väldigt elegant och deras sätt att presentera reklam ger användarna mycket mer positivitet än de banderoller som då var vanliga.
jag talar om Google AdWords innehållsbaserad annonsering, vilket är textsträngar med en länk till annonsörens webbplats. Dessutom visas annonser strikt i enlighet med den specifika fråga som användaren anger i sökfältet. Sådan reklam skapar inte obehag för användarna, men det ger dem verkligen fantastiska inkomster:

Förresten, Google är inte girigt och tillåter alla webbansvariga att tjäna pengar på kontextuell reklam genom att visa det på sina webbplatser. Visserligen håller han för sig själv ungefär hälften av det belopp som betalas av annonsören, men detta är en helt logisk betalning för att använda annonsörsbasen. Många webbansvariga lever enbart av viljan att passera.
Eftersom vi regelbundet jämför Google och Yandex här, kommer jag att säga att sättet som en RuNet-spegel tjänar på inte skiljer sig från ledaren för världssökning - det är fortfarande samma sammanhang, men allt heter . Jo, det tillåter också webbansvariga att tjäna pengar på sitt sammanhang (för halva marginalen) och för detta ändamål skapades det, med vilket du kan arbeta både direkt och genom partnerservicecenter (jag arbetar genom Profit Partner).
Google lanserade sitt sammanhang 2000 och Yandex 2002. Frågan om den ursprungliga källan till idén uppstår förmodligen inte. Även om grundaren inte omedelbart började använda betalningssystemet enbart för klick gjorda av användare på annonsörers annonser, utan arbetade för detta i flera år.
Tja, idén med att organisera en kontinuerlig auktion för försäljning av vissa sökfrågor (när de anges kommer annonser från annonsörer att visas) är generellt en genialisk lösning som avsevärt kan öka intäkterna och förenkla och underlätta prissättningen så mycket som möjligt . Som de säger, vi träffade tjuren.
2001 visade sig Google.com vara i svart med så mycket som sju miljoner dollar, och nu är vinsten för världssökledaren i miljarder. Förutom den amerikanska publiken har den länge varit riktad mot hela världen. Du kan söka på 200 språk på olika regionala webbplatser. Förutom faktiskt sökteknologier har detta företag under sin existens öppnat många relaterade tjänster, som börjar med och , och slutar med .
Han har redan till och med inkräktat på regeringstiden för de mest populära i världen, och motarbetat det med sin idé. Han är till och med redo att utmana Melkosofts dominans på operativsystemmarknaden genom att utveckla sitt eget operativsystem baserat på Chrome. Jo, han har redan revolutionerat marknaden för mobila operativsystem med sin Android, som nu är installerad på de flesta surfplattor och smartphones.
Jag skrev redan att Yandex blev börsnoterat 2011 och mycket framgångsrikt blev ett öppet aktiebolag med en ganska stor marginal för sig själv. 2004 offentliggjordes även Google på liknande sätt, men inte så framgångsrikt som det kunde ha varit. Men i båda fallen stod företagens ideologer fortfarande vid rodret och kan välja sina egna utvecklingsvägar och inte följa någons ledning. I princip är detta bra, eftersom båda lagen saknar entusiasm.
Google.ru - funktioner för marknadsföring och SEO-optimering
Låt oss nu prata lite om Google och hur det skiljer sig från en liknande åtgärd under Yandex. Naturligtvis finns det i stort sett ingen anledning att göra speciella skillnader mellan dessa sökmotorer, utan de har sina egna egenskaper och olika rankningsfaktorer tas olika hänsyn till i dem.
Tja, jag tror att det är klart att vi kommer att prata om det ryskspråkiga Google.ru, eftersom.com gör rankningar med en annan formel och flera andra faktorer tas i beaktande (vi är efterblivna, vad du än säger). Jag har redan skrivit om aktier på RuNets sökmarknad:

- Lite av ett mindre faktum, men jag kom ihåg att en borgerlig sökning kommer (från samma artikel) att leda till samma sida bara om det är hashlänkar.
- I Googles regioner representerar länder, och inte enskilda personer i Ryssland eller Ukraina, som i Yandex. Därför bör du ta hänsyn till detta, samt ta hänsyn till de faktorer som den kan tillskriva din webbplats till en viss region (läs mer nedan).
- Sökmotorn Google.ru lägger stor vikt vid närvaron och antalet inkommande länkar (externa och interna) till ett dokument med mera respekterar direkta händelser Sök fråga. I Yandex är länkfaktorn något mindre viktig och där kommer det att vara mycket viktigt att inte överdriva det med direkta förekomster, att använda ordformer och utspädningar mer. Men återigen, sökalgoritmer utvecklas och med tiden kommer de att närma sig vad vi nu har inom global sökning med tillägget .com.
- Jag har inte kontrollerat det själv och har inte upplevt det själv, men man tror att länkar från slut till ände (placerade från alla sidor i resursen, till exempel i givarens sidofält) fungerar bra i Google, eftersom För honom är det det kvantitativa förhållandet mellan länkmassan som är viktigt. Yandex limmar helt enkelt ihop utkasten och det är osannolikt att deras totala vikt överstiger vikten av en vanlig extern länk från en enda sida från samma givare.
Men det är värt att tänka på det faktum att säljande frågor ställs mycket oftare i Yandex (kanske till och med många gånger oftare), men andelen informationsfrågor är högre i den borgerliga motsvarigheten. Därför kan bloggar som min ha en ännu högre andel remisser från Google än från RuNet-spegeln.
Allt har att göra med målgruppsinriktningen för dessa sökmotorer. Låt ingen bli förolämpad av mig, men Yandex domineras av vanliga människor som vill köpa något eller ha kul, och i Page och Brins skapelse finns intellektuella (nåja, typ) som vill lära sig något. Personligen, av vana, använder jag en inhemsk produkt, men om den inte ger mig ett heltäckande svar, vänder jag mig till borgarklassen, och som regel gör han mig inte besviken.
Ni har säkert alla redan upplevt att Google inte bara fungerar snabbare och indexerar nya sidor snabbare, utan också att du kan komma till toppen mycket snabbare.
Huvudfaktorn här är troligen att Yandex för en tid sedan införde en fördröjning (från flera månader till ett år, beroende på ämnet för sökfrågan), varefter bakåtlänkarna som placerats (köpts) på dokumentet börjar tas hänsyn (således ökade det deras inkomst, eftersom under den period som krävs för att främja till toppen kommer webbplatsägaren att tvingas att locka användare genom Yandex Direct).
Med Google är denna fördröjning mycket mindre (om den överhuvudtaget finns) och du kan komma till Toppen ganska snabbt om du har bra och inte spammig text på en anständig sajt, samt ett visst antal externa länkar.
Tja, igen, det verkar för mig att Google älskar texter som de som du kan hitta på den här bloggen mer än Yandex - stora i volym och strukturerade (rubriker som använder H1-H6-taggar, OL eller UL-listor, och du kunde också jag önskar att jag skulle kunna använda tabeller för variation).
Strukturerade texter ger dig i alla fall en fördel. Sökmotorer tar hänsyn till tätheten av nycklar i passager, och listor, tabeller och rubriker tillåter skapa fler passager, vilket innebär att det kommer att vara möjligt att använda ett större antal förekomster av nycklar utan risk att hamna under .
Den har också en funktion - när den rankas, ägnar den mer uppmärksamhet åt indikatorerna för en specifik webbsida (vars relevans den beräknar) och ägnar mindre uppmärksamhet åt indikatorerna för hela webbplatsen. Detta betyder i jämförelse med Yandex, för marknadsföring där det är mycket viktigt att ha en förtroenderesurs.
Vad ger detta oss? Det visar sig att ett ungt projekt som inte har tillräckligt förtroende är mycket Det är lättare att komma till toppen av Googleän i Top Runet-spegeln, förutsatt att artikeln är av hög kvalitet, optimerad och välpumpad med länkar från kvalitetsgivare (till exempel från det eviga länkutbytet eller från artikelutbytet) och från de interna sidorna på samma webbplats (och, tillsammans med externa länkar, bidrar till att bygga statisk och dynamisk sidvikt).
Till exempel är min blogg i toppen av Google för många vanliga frågor, men inte i toppen av RuNet-spegeln. Det visar sig att antingen det allmänna förtroendet för resursen ännu inte är tillräckligt för detta, eller så har bakåtlänkarna ännu inte börjat fungera på grund av fördröjningen som används, eller så är dessa dokument under ett filter för att överoptimera texter (vilket också är möjligt) .
Söktrafik- detta är manna från himlen för alla ägare av en webbresurs, den mest stabila och som regel huvudkällan för tillströmning av besökare till webbplatsen. För mig utgör det till exempel ungefär tre fjärdedelar av den totala närvaron. Därför tröttnar jag aldrig på att upprepa i nästan varje artikel – ta alla minsta nyanser av sökmotoroptimering på allvar. Det som kan tyckas trivialt eller onödigt för dig kan bli en nyckelfaktor för ditt projekts framgång.
Det är sant att det också finns en hel del nyanser i att uppfylla alla krav, varav den viktigaste är den snabba förändringen av spelreglerna av sökmotorer. Naturligtvis förblir de viktigaste grundläggande och grundläggande optimeringsteknikerna oförändrade (åtminstone under lång tid), men ändå kännetecknas Yandex av en kraftig förändring i attityder till vissa metoder för fusk.
Tidigare kunde man känna sig mer lugn med Google, eftersom hon inte var så febrig. Men våren 2012 kom och med den kom djurparken: Pingvin och panda. De kom direkt på en global skala och påverkade alla länder. Efter detta började sökresultaten skaka konstant och nästan varannan webbplats i världen led i en eller annan grad av dessa filter.
Det var som en blixt från klar himmel. Alla kritiserade enhälligt Yandex och bytte sedan plötsligt till sin borgerliga konkurrent. Penguin började straffa den dåliga kvaliteten på inkommande länkar till sajten, och Panda började straffa för överoptimering av innehåll. Man får en känsla av att utvecklarna har satt sig i uppgift att göra marknadsföring under Google är så oförutsägbar som möjligt(idag är du i Toppen, och imorgon i...). Varför behöver de detta?
Anledningen är troligen pengar. Om SEO inte ger åtminstone några garantier och stabilitet, kommer alla att börja använda en alternativ metod ännu mer aktivt, nämligen att köpa kontextuell reklam. Egentligen är det detta som händer nu. Så länge sökmotorer finns kommer situationen att bli värre och värre.
Men ändå genereras söktrafik just från Yandex och Google, och i många fall kommer dessa två sökmotorer att ge ungefär samma antal besökare. Detta innebär att du måste ta hänsyn till nyanserna av optimering för båda.
Global (Google.com) och regional sökning (.ru, .ua)
Låt oss börja med att Google positionerar sig som en sökmotor för hela det globala Internet. I detta avseende har den både en global sökmotor.com, som fungerar med engelsktalande användare från hela världen, och regionala sökmotorer (till exempel .ru eller.com.ua, relaterade till Ryssland och Ukraina).
På den globala google.com finns det förutom ett enormt antal besökare också ett stort antal indexerade webbplatser i databasen (en enorm samling samlas där), och av detta följer slutsatsen att det kommer att vara mycket svårt att komma in i de bästa sökresultaten. Dessutom kommer det i en global sökmotor att vara nästan omöjligt att ta en plats i toppen för högfrekventa frågor på kort tid.
Detta beror främst på det stora antalet filter som används. Global sökmotor.com använder pessimisering och utövar därigenom strikt kontroll över kvaliteten på givare (webbplatser från vilka länkar till din resurs kommer att placeras), utvecklingen av ditt projekt, hastigheten för att bygga upp länkmassan, etc. saker.
Som ett resultat kommer endast resurser som har funnits och utvecklats under ganska lång tid att vara i toppen för mycket konkurrenskraftiga frågor (tillräckligt för att sökningen ska vara övertygad om deras lönsamhet).
Samtidigt, i regionala sökmotorer (till exempel google.ru eller.com.ua) är det fullt möjligt att komma till toppen för en högfrekvent fråga inom en eller två månader efter att projektet skapades. Detta beror på att många av filtren som används in.com inte fungerar där, eller inte fungerar till fullo.
Men han överför och förstärker gradvis filtren i sina regionala sökmotorer, så detta problem kommer också att behöva mötas inom en snar framtid vid marknadsföring. Egentligen har detta redan hänt. Efter ankomsten av Panda och Penguin blev alla lika.
Med all sin sofistikering och perfektion kan sökmotorn inte garantera en 100% korrekt bestämning av den region som din resurs tillhör. Som ett resultat av detta kan en ganska obehaglig situation uppstå, bestående av frånvaron av din webbplats i sökresultaten för den önskade regionala Google-sökmotorn (vi marknadsförde till exempel under England, och sökningen beslutade att din webbplats tillhör till Australien, som ett resultat kommer ditt projekt inte att visas i de engelska resultaten).
Inte ens språket för innehållet i din resurs kan fungera garant för korrekt bestämning av regionen. Tyvärr betyder inte ens det faktum att din webbplats är på albanska att den kommer att visas i de albanska Google-resultaten. Hur bestämmer han vilken region det eller det projektet tillhör och hur kan vi från vår sida hjälpa honom att göra rätt val?
Allt är ganska enkelt här. Först och främst, när man försöker tillskriva en resurs till en viss region, tittar Google på den region som detta internetprojekt tillhör. Om domänen tydligt indikerar en regional tillhörighet (till exempel: zon .RU - Ryssland, .DE - Tyskland eller .US - stater), kommer sökmotorn att välja region för webbplatsen baserat på detta.
Därför, om du använder ett domännamn för din webbplats som tillhör en zon i ett visst land, bör det inte vara några problem med att välja fel region för din resurs.
Men din resurs kan mycket väl ha en domän som tillhör någon gemensam zon (som .COM eller .NET). Vad styr sökningen vid val av region i det här fallet? Det visar sig att han analyserar Värdserverns IP-adress, där detta projekt ligger. Vilket land denna IP-adress kommer att tillhöra kommer webbplatsen att tilldelas denna region.
När du skapar ett nytt projekt som fokuserar på att marknadsföra en specifik region (land) i Googles sökmotor bör du därför se till att det omedelbart och exakt identifierar regionen på din webbplats. För att göra detta måste du antingen välja ett namn i domänzonen för den önskade regionen eller använda hosting med IP-adresserna för servrarna i det land du behöver.
Om den för din resurs inte har identifierat den regionala tillhörigheten korrekt, kan du i princip lägga till ytterligare ett ord till sökorden för de sökfrågor som du marknadsför, vilket anger den regionala tillhörigheten (till exempel "sökmotormarknadsföring) Ryssland").
Och i det här fallet kommer din webbplats att delta i de regionala Google-resultaten för det land du behöver (Ryssland), men inte för en högfrekvent fråga ("sökmotorkampanj"), utan för en mycket mindre högfrekvent fråga (" ... Ryssland”).
Om du tvärtom vill skapa en resurs fokuserad på många länder, se till att välja ett domännamn från en gemensam zon (som .COM eller .NET) och välj värd med IP-adressen för det land som det största antalet besökare förväntas.
Ställa in platsregionen i Yandex sökmotor
Yandex sökmotor har nyligen också börjat särskilja webbplatser efter region. Men i det här fallet betyder regioner inte länder (som i Google), utan regioner i Ryssland. En webbplatss regionala tillhörighet bestäms utifrån omnämnandet av regionen på dess sidor eller baserat på inställningarna som gjorts av ägaren av resursen i .
När du har loggat in från ditt konto till panelen för webbansvariga, måste du välja "Webbplatsgeografi" - "Region" från den vänstra menyn:

Som du kan se från skärmdumpen ovan definierade Yandex inte en region för min blogg: Innehållet på webbplatsen har inte en tydlig regional tillhörighet. Annars måste du ange önskad region på webbplatsen i lämpligt fält och ange i fältet under webbadressen till din bloggsida var namnet på denna region kommer att visas.
Återigen vill jag uppmärksamma dig på att du bör välja värd inte bara baserat på den korrekta definitionen av regionen (med IP-adressen för det land där du vill se din resurs), utan också på graden av dess tillförlitlighet. När det gäller webbplatsoptimering är tillförlitlig och stabil värddrift mycket viktig, för ständigt för sökmotorrobotar, som ett resultat av eller andra värdfel, kan det leda till en lägre position för webbplatsen i sökmotorresultat.
Ta därför hand om ditt projekt med fullt ansvar. Personligen är jag för tillfället, efter ett antal experiment, mest imponerad av Infobox-leverantör, mina första intryck som du kan läsa om i artikeln om.
Kort sagt, InfoBox har för närvarande en hel del bonusar (30 dagars freebies plus en gratis domän för alltid, om du betalar för hosting i tre månader) och en utmärkt teknisk supporttjänst.
Om du tror att jag är här och pratar om denna värd bara i hopp om att få , då skyndar jag mig att avråda dig, eftersom InfoBox endast finns för juridiska personer, och jag är en individ. Det är verkligen inte ett dåligt värd och jag rekommenderar det uppriktigt, utan någon fördel för mig själv, till dig.
Hur Googles sökmotor fungerar
I princip finns det inga speciella skillnader i logiken i Googles arbete från andra sökmotorers arbete. Jag har redan skrivit en ganska detaljerad artikel om, och nästan allt detta kan tillskrivas vår hjälte. Därför, utan att uppehålla mig vid detaljerna, kommer jag att försöka kortfattat beskriva hur det hela fungerar ur synvinkeln att identifiera de dokument som är mest relevanta för en viss begäran.
Så i Google, såväl som i andra sökmotorer, används två grundläggande principer, vägledda av vilka det bestämmer positionen för ett visst dokument (med dokument menar jag en webbsida) i sökresultaten för en specifik begäran. Först analyserar den dokumentets textinnehåll och bestämmer på så sätt dess ämne och gör beräkningar.
Och baserat på dessa två faktorer (dokumentinnehåll och länkrankning) bestämmer den webbplatsens position i sökresultaten för en viss sökfråga. Google söker inte på riktiga sajter, men enligt den så kallade samlingen, som representerar alla dokument som indexeras av sökmotorn på nätverket.
Indexering innebär att läsa innehållet på en sida och lagra alla ord som den innehåller i form av omvända index, som tar hänsyn till var ett givet ord finns i ett dokument och hur ofta det används.
Sparade kopior av dokument läggs också till i sökdatabasen, på basis av vilka söksystemet sedan genererar specifika frågor. Skanning av webbplatser på Internet utförs av så kallade sökrobotar, som flyttar från dokument till dokument med hjälp av länkar som leder från dessa dokument.
Hur kan Google sökrobotar hitta nya resurssidor? För det första kan en sökrobot få en uppgift att besöka ett visst dokument efter att du har lagt till adressen till en viss sida till . För det andra kan boten indexera ett dokument genom att följa en länk från en annan eller från din egen resurs.
Av detta kan vi dra slutsatsen att bra och genomtänkt navigering inte bara kommer att vara användbar för dina besökare, utan också hjälpa öka farten sökmotorer. Ett av sätten att uppnå denna acceleration är designat specifikt för bots.
Bakåtlänkar till det här dokumentet samlas in av Googles sökmotor när dokumenten som de placerades på indexeras. Som ett resultat, när en användare anger en specifik fråga i sökfältet, kommer han att analysera och hitta alla dokument som har åtminstone någon relation till denna fråga, och sedan bland dem kommer dokumenten att sorteras enligt relevansen (efterlevnaden) av dokumenten med denna fråga.
Vid beräkning av relevans beaktas innehållet i dokumentet, såväl som kvantiteten och kvaliteten på bakåtlänkar som leder till det.
Huvud- och kompletterande Google-index
Googles materiella kapacitet (både monetär och hårdvara) gör att denna sökmotor kan indexera alla sidor i rad och lagra dem i sin indexdatabas (samling). Mindre sökmotorer, inklusive Yandex, har inte råd med sådan lyx och tar bort duplicerat innehåll (till exempel) och andra dokument av låg kvalitet från indexet.
Men vår hjälte är inte sådan - han har så stor makt att han kan lagra i sin samling alla dokument (webbsidor) som indexerats av honom på nätverket.
Det är sant att detta är till liten fördel för webbansvariga, eftersom Googles databas består av två delar: huvudindex och tillägg(kompletterande, det kallas också ibland snorig eller helt enkelt snor). Så den söker bara efter dokument som finns i huvudindexet, och dokument (webbsidor) som ingår i snotten deltar praktiskt taget inte i sökningen, såvida det i allmänhet inte finns några svar som är relevanta för begäran alls. Och sannolikheten för ett sådant fall är extremt låg.
Jag har redan skrivit om speciella och utvärderar därför indirekt kvaliteten på ditt webbprojekt. Även om du själv, utan att använda några tjänster, kan se hur många sidor din webbplats har finns i Googles huvudindex.
För att komma igång anger du följande fråga i sökfältet:
Webbplats:webbplats
byter ut min bloggs domännamn med ditt eget. Som ett resultat kommer en sida med resultat att öppnas, där alla sidor i din resurs som finns i indexet kommer att listas. Dokument inte bara från huvudindexet, utan också från det kompletterande indexet kommer att listas här. Under frågesträngen kommer det totala antalet sidor i din resurs att indexeras av denna sökmotor:

Nu, efter att ha kommit ihåg det totala antalet sidor i indexet, ändra frågan i Googles sökfält till följande:
Site:site/&
byter ut min bloggs domännamn med ditt eget. Som ett resultat kommer en sida med resultat att öppnas, där endast de sidorna på din webbplats kommer att listas. som finns i huvudindexet:

Endast dessa dokument som finns i huvudindexet kommer att genomsökas. Jag har redan skrivit om vilka orsaker som kan leda till att sidor hamnar i ett tillägg snarare än i huvudindexet, men jag kommer att upprepa mig själv lite och kanske lägga till några nya möjliga orsaker till varför en sida kan hamna i Googles snopp:
- icke-unikhet hos sidinnehållet (hel eller delvis kopiering av texten på en annan sida av din egen resurs eller någon annan)
- det finns för lite text på webbsidan (bilder, även om de beaktas vid bildsökning, och hyperlänkar räknas inte). Jag kan inte säga exakt hur mycket text i tecken eller ord som ska finnas i ett dokument för att få det ur Googles snop, men jag har redan skrivit om hur textstorleken ska vara för att bäst optimera den för sökfrågor
- sidan kan hamna i ett extra index om du glömt att registrera dig för den
- snot hotar också sidor vars titel eller beskrivning megataggar inte är unika eller består av ett ord
Video från youtube.com om principerna för marknadsföring i Google:
Lycka till! Vi ses snart på bloggsidans sidor
Du kanske är intresserad
Exkludera en webbplats från Google Penguin-filtret - steg-för-steg-guide  SEO-terminologi, akronymer och jargong
SEO-terminologi, akronymer och jargong  Dechiffrera och förklara SEO-förkortningar, termer och jargong
Dechiffrera och förklara SEO-förkortningar, termer och jargong  Hur man lägger till en webbplats för att lägga till URL till Yandex, Google och andra sökmotorer, registrering i paneler för webbansvariga och kataloger
Hur man lägger till en webbplats för att lägga till URL till Yandex, Google och andra sökmotorer, registrering i paneler för webbansvariga och kataloger  Med hänsyn till språkets morfologi och andra problem lösta av sökmotorer, såväl som skillnaden mellan högfrekventa, mellanregister och lågfrekventa frågor
Med hänsyn till språkets morfologi och andra problem lösta av sökmotorer, såväl som skillnaden mellan högfrekventa, mellanregister och lågfrekventa frågor  Statistik över sökfrågor från Yandex, Google och Rambler, hur och varför man arbetar med Wordstat
Statistik över sökfrågor från Yandex, Google och Rambler, hur och varför man arbetar med Wordstat