Изучение системы команд процессора ARM. Изучение системы команд процессора ARM Создание собственной операционной системы для Raspberry Pi
Привет всем!
По роду деятельности я программист на Java. Последние месяцы работы заставили меня познакомиться с разработкой под Android NDK и соответственно написание нативных приложений на С. Тут я столкнулся с проблемой оптимизации Linux библиотек. Многие оказались абсолютно не оптимизированы под ARM и сильно нагружали процессор. Ранее я практически не программировал на ассемблере, поэтому сначала было сложно начать изучать этот язык, но все же я решил попробовать. Эта статья написана, так сказать, от новичка для новичков. Я постараюсь описать те основы, которые уже изучил, надеюсь кого-то это заинтересует. Кроме того, буду рад конструктивной критике со стороны профессионалов.
Введение
Итак, для начала разберёмся что же такое ARM. Википедия дает такое определение:Архитектура ARM (Advanced RISC Machine, Acorn RISC Machine, усовершенствованная RISC-машина) - семейство лицензируемых 32-битных и 64-битных микропроцессорных ядер разработки компании ARM Limited. Компания занимается исключительно разработкой ядер и инструментов для них (компиляторы, средства отладки и т. п.), зарабатывая на лицензировании архитектуры сторонним производителям.
Если кто не знает, сейчас большая часть мобильных устройств, планшетов разработаны именно на этой архитектуре процессоров. Основным преимуществом данного семейства является низкое энергопотребление, благодаря чему он часто используется в различных встроенных системах. Архитектура развивалась с течением времени, и начиная с ARMv7 были определены 3 профиля: ‘A’(application) - приложения, ‘R’(real time) - в реальном времени,’M’(microcontroller) - микроконтроллер. Историю разработки этой технологии и другие интересный данные вы можете прочитать в Википедии или погуглив в интернете. ARM поддерживает разные режимы работы (Thumb и ARM, кроме того в последние время появился Thumb-2, являющийся смесью ARM и Thumb). В данной статье рассмотрим собственно режим ARM, в котором исполняется 32-битный набор команд.
Каждый ARM процессор создан из следующих блоков:
- 37 регистров (из которых видимых при разработке только 17)
- Арифметико-логи́ческое устройство (АЛУ) - выполняет арифметические и логические задачи
- Barrel shifter - устройство, созданное для перемещения блоков данных на определенное количество бит
- The CP15 - специальная система, контроллирующая ARM сопроцессоры
- Декодер инструкций - занимается преобразованием инструкции в последовательность микроопераций
Конвейерное исполнение (Pipeline execution)
В ARM процессорах используется 3-стадийный конвейер (начиная с ARM8 был реализова 5-стадийный конвейер). Рассмотрим простой конвейер на примере процессора ARM7TDMI. Исполнение каждой инструкции состоит из трёх ступеней:1. Этап выборки (F)
На этом этапе инструкции поступают из ОЗУ в конвейер процессора.
2. Этап декодирования (D)
Инструкции декодируются и распознаётся их тип.
3. Этап исполнения (E)
Данные поступают в ALU и исполняются и полученное значение записывается в заданный регистр.
Но при разработке надо учитывать, что, есть инструкции, которые используют несколько циклов исполнения, например, load(LDR) или store. В таком случае этап исполнения (E) разделяется на этапы (E1, E2, E3...).
Условное выполнение
Одна из важнейших функций ARM ассемблера - условное выполнение. Каждая инструкция может исполняться условно и для этого используются суффиксы. Если суффикс добавляется к названию инструкции, то прежде чем выполнить ее, происходит проверка параметров. Если параметры не соответствуют условию, то инструкция не выполняется. Суффиксы:MI - отрицательное число
PL - положительное или ноль
AL - выполнять инструкцию всегда
Суффиксов условного выполнения намного больше. Остальные суффиксы и примеры прочитать в официальной документации: ARM документация
А теперь пришло время рассмотреть…
Основы синтаксиса ARM ассемблера
Тем, кто раньше работал с ассемблером этот пункт можно фактически пропустить. Для всех остальных опишу основы работы с этим языком. Итак, каждая программа на ассемблере состоит из инструкций. Инструкция создаётся таким образом:{метка} {инструкция|операнды} {@ комментарий}
Метка - необязательный параметр. Инструкция - непосредственно мнемоника инструкции процессору. Основные инструкции и их использование будет разобрано далее. Операнды - константы, адреса регистров, адреса в оперативной памяти. Комментарий - необязательный параметр, который не влияет на исполнение программы.
Имена регистров
Разрешены следующие имена регистров:1.r0-r15
3.v1-v8 (переменные регистры, с r4 по r11)
4.sb and SB (статический регистр, r9)
5.sl and SL (r10)
6.fp and FP (r11)
7.ip and IP (r12)
8.sp and SP (r13)
9.lr and LR (r14)
10.pc and PC (программный счетчик, r15).
Переменные и костанты
В ARM ассемблере, как и любом (практически) другом языке программирования могут использоваться переменные и константы. Они разделяются на такие типы:- Числовые
- Логические
- Строковые
a SETA 100; создается числовая переменная «a» с значением 100.
Строковые переменные:
improb SETS «literal»; создается переменная improb с значение «literal». ВНИМАНИЕ! Значение переменной не может превышать 5120 символов.
В логических переменных соответственно используются значения TRUE и FALSE.
Примеры инструкций ARM ассемблера
В данной таблице я собрал основные инструкции, которая потребуется для дальнейшей разработки (на самом базовом этапе:):Чтобы закрепить использование основных инструкций давайте напишем несколько простых примеров, но сначала нам понадобится arm toolchain. Я работаю в Linux поэтому выбрал: frank.harvard.edu/~coldwell/toolchain (arm-unknown-linux-gnu toolchain). Ставится он проще простого, как и любая другая программа на Linux. В моем случае (Russian Fedora) понадобилось только установить rpm пакеты с сайта.
Теперь пришло время написать простейший пример. Программа будет абсолютно бесполезной, но главное, что будет работать:) Вот код, который я вам предлагаю:
start: @ Необязательная строка, обозначающая начало программы
mov r0, #3 @ Грузим в регистр r0 значение 3
mov r1, #2 @ Делаем тоже самое с регистром r1, только теперь с значением 2
add r2, r1, r0 @ Складываем значения r0 и r1, ответ записываем в r2
mul r3, r1, r0 @ Умножаем значение регистра r1 на значение регистра r0, ответ записываем в r3
stop: b stop @ Строка завершения программы
Компилируем программу до получения.bin файла:
/usr/arm/bin/arm-unknown-linux-gnu-as -o arm.o arm.s
/usr/arm/bin/arm-unknown-linux-gnu-ld -Ttext=0x0 -o arm.elf arm.o
/usr/arm/bin/arm-unknown-linux-gnu-objcopy -O binary arm.elf arm.bin
(код в файле arm.s, а toolchain в моем случае лежит в директории /usr/arm/bin/)
Если все прошло успешно, у вас будет 3 файла: arm.s (собственно код), arm.o, arm.elf, arm.bin (собственно исполняемая программа). Для того, чтобы проверить работу программы не обязательно иметь собственное arm устройство. Достаточно установить QEMU. Для справки:
QEMU - свободная программа с открытым исходным кодом для эмуляции аппаратного обеспечения различных платформ.Включает в себя эмуляцию процессоров Intel x86 и устройств ввода-вывода. Может эмулировать 80386, 80486, Pentium, Pentium Pro, AMD64 и другие x86-совместимые процессоры; PowerPC, ARM, MIPS, SPARC, SPARC64, m68k - лишь частично.
Работает на Syllable, FreeBSD, FreeDOS, Linux, Windows 9x, Windows 2000, Mac OS X, QNX, Android и др.
Итак, для эмуляции arm понадобится qemu-system-arm. Этот пакет есть в yum, так что тем, у кого Fedora, можно не заморачиваться и просто выполнить комманду:
yum install qemu-system-arm
Далее надо запустить эмулятор ARM, так, чтобы он выполнил нашу программу arm.bin. Для этого создадим файл flash.bin, который будет флэш памятью для QEMU. Сделать это очень просто:
dd if=/dev/zero of=flash.bin bs=4096 count=4096
dd if=arm.bin of=flash.bin bs=4096 conv=notrunc
Теперь грузим QEMU с полученой flash памятью:
qemu-system-arm -M connex -pflash flash.bin -nographic -serial /dev/null
На выходе вы получите что-то вроде этого:
$ qemu-system-arm -M connex -pflash flash.bin -nographic -serial /dev/null
QEMU 0.15.1 monitor - type "help" for more information
(qemu)
Наша программа arm.bin должна была изменить значения четырех регистров, следовательно для проверки правильности работы давайте посмотрим на эти самые регистры. Делается это очень простой коммандой: info registers
На выходе вы увидите все 15 ARM регистров, при чем у четырех из них будут измененные значения. Проверьте:) Значения регистров совпадают с теми, которые можно ожидать после исполнения программы:
(qemu) info registers
R00=00000003 R01=00000002 R02=00000005 R03=00000006
R04=00000000 R05=00000000 R06=00000000 R07=00000000
R08=00000000 R09=00000000 R10=00000000 R11=00000000
R12=00000000 R13=00000000 R14=00000000 R15=00000010
PSR=400001d3 -Z-- A svc32
P.S. В этой статье я постарался описать основы программирования на ARM ассемблер. Надеюсь вам понравилось! Этого хватит для того, чтобы далее углубляться в дебри этого языка и писать на нем программы. Если все получится, буду писать дальше о том, что узнаю сам. Если есть ошибки, прошу не пинать, так как я новичок в ассемблере.
Если вы используете дистрибутив Raspbian в качестве операционной системы вашего Raspberry Pi, вам понадобятся две утилиты, а именно, as (ассемблер, который преобразует исходный код на языке ассемблера в бинарный код) и ld (линковщик, который создает результирующий исполняемый файл). Обе утилиты находятся в пакете программного обеспечения binutils , поэтому они уже могут присутствовать в вашей системе. Разумеется, вам также понадобится хороший текстовый редактор; я всегда рекомендую использовать Vim для разработки программ, но он имеет высокий порог вхождения, поэтому Nano или любой другой текстовый редактор с графическим интерфейсом также отлично подойдет.
Готовы начать? Скопируйте следующий код и сохраните его в файле myfirst.s:
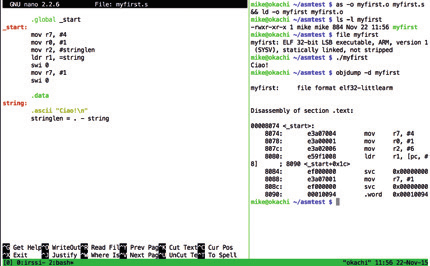
Global _start _start: mov r7, #4 mov r0, #1 ldr r1, =string mov r2, #stringlen swi 0 mov r7, #1 swi 0 .data string: .ascii "Ciao!\n" stringlen = . - string
Эта программа всего-навсего выводит строку "Ciao!" на экран и если вы читали статьи, посвященные использованию языка ассемблера для работы с центральными процессорами архитектуры x86, некоторые из использованных инструкций могут быть вам знакомы. Но все же, существует множество различий между инструкциями архитектур x86 и ARM, что также можно сказать и синтаксисе исходного кода, поэтому мы подробно разберем его.
Но перед этим следует упомянуть о том, что для ассемблирования приведенного кода и связывания результирующего объектного файла в исполняемый файл нужно использовать следующую команду:
As -o myfirst.o myfirst.s && ld -o myfirst myfirst.o
Теперь вы можете запустить созданную программу с помощью команды./myfirst . Вы наверняка обратили внимание на то, что исполняемый файл имеет очень скромный размер около 900 байт - если бы вы использовали язык программирования C и функцию puts() , размер бинарного файла был бы больше примерно в пять раз!
Создание собственной операционной системы для Raspberry Pi
Если вы читали предыдущие статьи серии, посвященные программированию на языке ассемблера для архитектуры x86, вы наверняка помните тот момент, когда вы в первый раз запустили свою собственную операционную систему, выводящую сообщение на экран без помощи Linux или какой-либо другой операционной системы. После этого мы доработали ее, добавив простой интерфейс командной строки и механизм загрузки и запуска программ с диска, оставив задел на будущее. Это была очень интересная, но не очень сложная работа главным образом благодаря помощи со стороны прошивки BIOS - она предоставляла упрощенный интерфейс для доступа к экрану, клавиатуре и устройству чтения флоппи-дисков.
В случае Raspberry Pi в вашем распоряжении больше не будет полезных функций BIOS, поэтому вам придется самостоятельно разрабатывать драйверы для устройств, что само по себе является сложной и малоинтересной работой по сравнению с рисованием на экране и реализацией механизма исполнения собственных программ. При этом в сети существует несколько руководств, в которых подробно описаны начальные этапы процесса загрузки Raspberry Pi, особенности механизма доступа к выводам GPIO и так далее.
Одним из лучших подобных документов является документ под названием Baking Pi (www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/index.html) от сотрудников Университета Кэмбриджа. По сути, он является набором руководств, описывающих приемы работы с языком ассемблера для включения светодиодов, доступа к пикселям на экране, получения клавиатурного ввода и так далее. В процессе чтения вы узнаете очень много об аппаратном обеспечении Raspberry Pi, причем руководства были написаны для оригинальных моделей этих одноплатных компьютеров, поэтому нет никаких гарантий того, что они будут актуальны для таких моделей, как A+, B+ и Pi 2.
Если вы предпочитаете язык программирования C, вам следует обратиться к документу с ресурса Valvers, расположенному по адресу http://tinyurl.com/qa2s9bg и содержащему описание процесса настройки кросскомпилятора и сборки простейшего ядра операционной системы, причем в разделе Wiki полезного ресурса OSDev, расположенном по адресу http://wiki.osdev.org/Raspberry_Pi_Bare_Bones , также приведена информация о том, как создать и запустить простейшее ядро ОС на Raspberry Pi.
Как говорилось выше, самой большой проблемой в данном случае является необходимость разработки драйверов для различных аппаратных устройств Raspberry Pi: контроллера USB, слота SD-карты и так далее. Ведь даже код для упомянутых устройств может занять десятки тысяч строк. Если вы все же хотите разработать собственную полнофункциональную операционную систему для Raspberry Pi, вам стоит посетить форумы по адресу www.osdev.org и поинтересоваться, не разработал ли уже кто-либо драйверы для этих устройств и, при наличии возможности, адаптировать их для ядра своей операционной системы, сэкономив тем самым большое количество своего времени.
Как все это работает
Первые две строки кода являются не инструкциями центрального процессора, а директивами ассемблера и линковщика. Каждая программа должна иметь четко заданную точку входа под названием _start , причем в нашем случае она оказалась в самом начале кода. Таким образом мы сообщаем линковщику, что исполнение кода должно начинаться с первой же инструкции и никаких дополнительных действий не требуется.
С помощью следующей инструкции мы помещаем число 4 в регистр r7 . (Если вы никогда не работали с языком ассемблера ранее, вам следует знать, что регистром называется ячейка памяти, расположенная непосредственно в центральном процессоре. В большинстве современных центральных процессоров реализовано небольшое количество регистров по сравнению с миллионами или миллиардами ячеек оперативной памяти, но при этом регистры незаменимы, так как работают гораздо быстрее.) Чипы архитектуры ARM предоставляют разработчикам большое количество регистров общего назначения: разработчик может использовать до 16 регистров с именами от r0 до r15 , причем эти регистры не связаны с какими-либо историческими сложившимися ограничениями, как в случае архитектуры x86, где некоторые из регистров могут использоваться для определенных целей в определенные моменты.
Итак, хотя инструкция mov и очень похожа на одноименную инструкцию архитектуры x86, вам в любом случае следует обратить внимание на символ решетки рядом с числом 4 , указывающий на то, что далее расположено целочисленное значение, а не адрес в памяти. В данном случае мы желаем использовать системный вызов write ядра Linux для вывода нашей строки; для использования системных вызовов следует заполнять регистры необходимыми значениями перед тем, как простить ядро выполнить свою работу. Номер системного вызова должен помещаться в регистр r7 , причем число 4 является номером системного вызова write.
С помощью следующей инструкции mov мы помещаем дескриптор файла, в который должна быть записана строка "Ciao!", то есть, дескриптор стандартного потока вывода, в регистр r0 . Так как в данном случае используется поток стандартного вывода, в регистр помещается его стандартный дескриптор, то есть, 1 . Далее нам нужно поместить адрес строки, которую мы хотим вывести, в регистр r1 с помощью инструкции ldr (инструкция "загрузки в регистр"; обратите внимание на знак равенства, указывающий на то, что далее следует метка, а не адрес). В конце кода, а именно, в секции данных мы объявляем эту строку в форме последовательности символов ASCII. Для успешного использования системного вызова "write" нам также придется сообщить ядру операционной стемы о том, какова длина выводимой строки, поэтому мы помещаем значение stringlen в регистр r2 . (Значение stringlen рассчитывается путем вычитания адреса окончания строки из адреса ее начала.)
На данный момент мы заполнили все регистры необходимыми данными и готовы к передаче управления ядру Linux. Для этого мы используем инструкцию swi , название которой расшифровывается как "software interrupt" ("программное прерывание"), осуществляющую переход в пространство ядра ОС (практически таким же образом, как и инструкция int в статьях, посвященных архитектуре x86). Ядро ОС исследует содержимое регистра r7 , обнаруживает в нем целочисленное значение 4 и делает вывод: "Так, вызывающая программа хочет вывести строку". После этого оно исследует содержимое других регистров, осуществляет вывод строки и возвращает управление нашей программе.
Таким образом мы видим на экране строку "Ciao!", после чего нам остается лишь корректно завершить исполнение программы. Мы решаем эту задачу путем помещения номера системного вызова exit в регистр r7 с последующим вызовом инструкции программного прерывания номер ноль. И на этом все - ядро ОС завершает исполнение нашей программы и мы снова перемещаемся в командную оболочку.

Vim (слева) является отличным текстовым редактором для написания кода на языке ассемблера - файл для подсветки синтаксиса данного языка для архитектуры ARM доступен по ссылке http://tinyurl.com/psdvjen .
Совет: при работе с языком ассемблера следует не скупиться на комментарии. Мы не использовали большого количества комментариев в данной статье для того, чтобы код занимал как можно меньше места на страницах журнала (а также потому, что мы подробно описали назначение каждой из инструкций). Но при разработке сложных программ, код которых кажется очевидным на первый взгляд вы всегда должны задумываться о том, как он будет выглядеть после того, как вы частично забудете синтаксис языка ассемблера для архитектуры ARM и вернетесь к разработке по прошествии нескольких месяцев. Вы можете забыть обо всех использованных в коде трюках и сокращениях, после чего код будет выглядеть как полнейшая абракадабра. Исходя из всего вышесказанного, следует добавлять в код как можно больше комментариев, даже в том случае, если некоторые из них кажутся слишком очевидными в текущий момент!
Обратный инжиниринг
Преобразование бинарного файла в код на языке ассемблера также может оказаться полезным в некоторых случаях. Результатом данной операции обычно является не особо качественно оформленный код без читаемых имен меток и комментариев, который тем не менее, может пригодиться для изучения преобразований, которые были выполнены ассемблером с вашим кодом. Для дизассемблирования бинарного файла myfirst достаточно выполнить следующую команду:
Objdump -d myfirst
Эта команда позволит осуществить дизассемблирование секции исполняемого кода бинарного файла (но не секции данных, так как она содержит текст в кодировке ASCII). Если вы ознакомитесь с кодом, полученным в результате дизассемблирования, вы наверняка заметите, что инструкции в нем практически не отличаются от инструкций в оригинальном коде. Дизассемблеры используются главным образом тогда, когда нужно изучить поведение программы, которая доступна лишь в форме бинарного кода, например, вируса или простой программы с закрытым исходным кодом, поведение которой вы желаете эмулировать. При этом вы должны всегда помнить об ограничениях, накладываемых автором исследуемой программы! Дизассемблирование бинарного файла программы и простое копирование полученного кода в код вашего проекта, разумеется, является плохой идеей; при этом вы вполне можете использовать полученный код для изучения принципа работы программы.
Подпрограммы, циклы и условные инструкции
Теперь, когда мы знаем, как разрабатывать, ассемблировать и связывать простые программы, давайте перейдем к рассмотрению кое-чего более сложного. В следующей программе для вывода строк используются подпрограммы (благодаря им мы можем повторно использовать фрагменты кода и избавить себя от необходимости выполнения однотипных операций заполнения регистров данными). В данной программе реализован главный цикл обработки событий, который позволяет осуществлять вывод строки до того момента, как пользователь введет "q". Изучите код и попытайтесь понять (или угадать!) назначение инструкций, но не отчаивайтесь, если вам что-то не понятно, ведь чуть позже мы также рассмотрим его в мельчайших подробностях. Обратите внимание на то, что с помощью символов @ в языке ассемблера для архитектуры ARM выделяются комментарии.
Global _start _start: ldr r1, =string1 mov r2, #string1len bl print_string loop: mov r7, #3 @ read mov r0, #0 @ stdin ldr r1, =char mov r2, #2 @ два символа swi 0 ldr r1, =char ldrb r2, cmp r2, #113 @ Код ASCII символа "q" beq done ldr r1, =string2 mov r2, #string2len bl print_string b loop done: mov r7, #1 swi 0 print_string: mov r7, #4 mov r0, #1 swi 0 bx lr .data string1: .ascii "Enter q to quit!\n" string1len = . - string1 string2: .ascii "That wasn"t q...\n" string2len = . - string2 char: .word 0
Наша программа начинается с помещения указателя на начало строки и значения ее длины в соответствующие регистры для последующего осуществления системного вызова write , причем сразу же после этого осуществляется переход к подпрограмме print_string , расположенной ниже в коде. Для осуществления этого перехода используется инструкция bl , название которой расшифровывается как "branch and link" ("ветвление с сохранением адреса"), причем сама она сохраняет текущий адрес в коде, что позволяет вернуться к нему впоследствии с помощью инструкции bx . Подпрограмма print_string просто заполняет другие регистры для осуществления системного вызова write таким же образом, как и в нашей первой программе перед переходом в пространство ядра ОС с последующим возвратом к сохраненному адресу кода с помощью инструкции bx .
Вернувшись к осуществляющему вызов коду, мы можем обнаружить метку под названием loop - название метки уже намекает на то, что мы вернемся к ней через некоторое время. Но сначала мы используем еще один системный вызов с именем read (под номером 3) для чтения символа, введенного пользователем с помощью клавиатуры. Поэтому мы помещаем значение 3 в регистр r7 и значение 0 (дескриптор стандартного потока ввода) в регистр r0 , так как нам нужно прочитать пользовательский ввод, а не данные из файла.
Далее мы размещаем адрес, по которому мы хотим сохранить символ, прочитанный и помещенный ядром ОС в регистр r1 - в нашем случае это область памяти char , описанная в конце секции данных. (На самом деле, нам нужно машинное слово, то есть, область памяти для хранения двух символов, ведь в ней будет храниться и код клавиши Enter. При работе с языком ассемблера важно всегда помнить о возможности переполнения областей памяти, ведь в нем нет никаких высокоуровневых механизмов, готовых прийти вам на помощь!).
Вернувшись к основному коду, мы увидим, что в регистр r2 помещается значение 2 , соответствующее двум символам, которые мы хотим сохранить, после чего осуществляется переход в пространство ядра ОС для выполнения операции чтения. Пользователь вводит символ и нажимает клавишу Enter. Теперь нам нужно проверить, что это за символ: мы помещаем адрес области памяти (char в секции данных) в регистр r1 , после чего с помощью инструкции ldrb загружаем байт из области памяти, на которую указывает значение из этого регистра.
Квадратные скобки в данном случае указывают на то, что данные хранятся в интересующей нас области памяти, а не в самом регистре. Таким образом, регистр r2 теперь содержит единственный символ из области памяти char из секции данных, причем это именно тот символ, который ввел пользователь. Наша следующая задача будет заключаться в сравнении содержимого регистра r2 с символом "q" , который является 113 символом таблицы ASCII (обратитесь к таблице символов, расположенной по адресу www.asciichart.com). Теперь мы используем инструкцию cmp для выполнения операции сравнения, после чего используем инструкцию beq , имя которой расшифровывается как "branch if equal" (переход при условии равенства), для перехода к метке done в том случае, если значение из регистра r2 равно 113. Если это не так, то мы выводим нашу вторую строку, после чего осуществляем переход к началу цикла с помощью инструкции b .
Наконец, после метки done мы сообщаем ядру ОС о том, что мы хотим завершить исполнение программы, точно так же, как и в первой программе. Для запуска данной программы следует просто осуществить ее ассемблирование и связывание в соответствии с инструкциями, приведенными для первой программы.

Итак, мы рассмотрели достаточно большой объем информации в максимально сжатой форме, но будет лучше, если вы займетесь самостоятельным изучением материала, экспериментируя с приведенным выше кодом. Нет лучшего способа знакомства с языком программирования, чем проведение экспериментов, заключающихся в модификации чужого кода и наблюдении за достигнутым эффектом. Теперь вы можете разрабатывать простые программы на языке ассемблера для архитектуры ARM, осуществляющие чтение пользовательского ввода и вывод данных, при этом использующие циклы, операции сравнения и подпрограммы. Если вы не сталкивались с языком ассемблера до сегодняшнего дня, я надеюсь, что данная статья сделала этот язык немного более понятным для вас помогла развеять популярный стереотип о том, что он является мистическим ремеслом, доступным лишь нескольким талантливым разработчикам.
Разумеется, приведенная в статье информация относительно использования языка ассемблера для архитектуры ARM является всего лишь вершиной айсберга. Использование данного языка программирования всегда связано с огромным количеством нюансов и если вы хотите, чтобы мы написали о них в одной из следующих статей, просто дайте нам знать об этом! Пока же рекомендуем посетить отличный ресурс с множеством материалов для изучения приемов создания программ для систем Linux, исполняющихся на компьютерах с центральными процессорами архитектуры ARM, который расположен по адресу http://tinyurl.com/nsgzq89 . Удачного программирования!
Предыдущие статьи из серии "Школа ассемблера":
Итак, мы создали новый проект, выполнили основные настройки, создали и подключили к проекту файл, в котором хотим написать на ассемблере какую-нибудь простенькую программу.
Что дальше? Дальше, собственно говоря, можно писать программу, используя набор команд thumb-2, поддерживаемый ядром Cortex-M3. Список и описание поддерживаемых команд можно посмотреть в документе под названием Cortex-M3 Generic User Guide (глава The Cortex-M3 Instruction Set ), который можно найти на вкладке Books в менеджере проекта, в Keil uVision 5. Подробно о командах thumb-2 будет написано в одной из следующих частей этой статьи, а пока поговорим о программах для STM32 в общем.
Как и любая другая программа на ассемблере, программа для STM32 состоит из команд и псевдокоманд, которые будут транслированы непосредственно в машинные коды, а также из различных директив, которые в машинные коды не транслируются, а используются в служебных целях (разметка программы, присвоение константам символьных имён и т.д.)
Например, разбить программу на отдельные секции позволяет специальная директива — AREA . Она имеет следующий синтаксис: AREA Section_Name {,type} {, attr} … , где:
- Section_name — имя секции.
- type — тип секции. Для секции, содержащей данные нужно указывать тип DATA, а для секции, содержащей команды — тип CODE.
- attr — дополнительные атрибуты. Например, атрибуты readonly или readwrite указывают в какой памяти должна размещаться секция, атрибут align=0..31 указывает каким образом секция должна быть выровнена в памяти, атрибут noinit используется для выделения областей памяти, которые не нужно инициализировать или инициализирующиеся нулями (при использовании этого атрибута можно не указывать тип секции, поскольку он может использоваться только для секций данных).
Директива EQU наверняка всем хорошо знакома, поскольку встречается в любом ассемблере и предназначена для присвоения символьных имён различным константам, ячейкам памяти и т.д. Она имеет следующий синтаксис: Name EQU number и сообщает компилятору, что все встречающиеся символьные обозначения Name нужно заменять на число number . Скажем, если в качестве number использовать адрес ячейки памяти, то в дальнейшем к этой ячейке можно будет обращаться не по адресу, а используя эквивалентное символьное обозначение (Name ).
Директива GET filename вставляет в программу текст из файла с именем filename . Это аналог директивы include в ассемблере для AVR. Её можно использовать, например, для того, чтобы вынести в отдельный файл директивы присвоения символьных имён различным регистрам. То есть мы выносим все присвоения имён в отдельный файл, а потом, чтобы в программе можно было пользоваться этими символьными именами, просто включаем этот файл в нашу программу директивой GET.
Разумеется, кроме перечисленных выше есть ещё куча всяких разных директив, полный список которых можно найти в главе Directives Reference документа Assembler User Guide , который можно найти в Keil uVision 5 по следующему пути: вкладка Books менеджера проектов -> Tools User’s Guide -> Complete User’s Guide Selection -> Assembler User Guide .
Большинство команд, псевдокоманд и директив в программе имеют следующий синтаксис:
{label} SYMBOL {expr} {,expr} {,expr} {; комментарий}
{label} — метка. Она нужна для того, чтобы можно было определить адрес следующей за этой меткой команды. Метка является необязательным элементом и используется только когда необходимо узнать адрес команды (например, чтобы выполнить переход на эту команду). Перед меткой не должно быть пробелов (то есть она должна начинаться с самой первой позиции строки), кроме того, имя метки может начинаться только с буквы.
SYMBOL — команда, псевдокоманда или директива. Команда, в отличии от метки, наоборот, должна иметь некоторый отступ от начала строки даже если перед ней нет метки.
{expr} {,expr} {,expr} — операнды (регистры, константы…)
; — разделитель. Весь текст в строке после этого разделителя воспринимается как комментарий.
Ну а теперь, как и обещал, простейшая программа:
| AREA START , CODE , READONLY dcd 0x20000400 dcd Program_start ENTRY Program_start b Program_start END |
AREA START, CODE, READONLY dcd 0x20000400 dcd Program_start ENTRY Program_start b Program_start END
В этой программе у нас всего одна секция, которая называется START. Эта секция размещается во flash-памяти (поскольку для неё использован атрибут readonly).
Первые 4 байта этой секции содержат адрес вершины стека (в нашем случае 0x20000400), а вторые 4 байта — адрес точки входа (начало исполняемого кода). Далее следует сам код. В нашем простейшем примере исполняемый код состоит из одной единственной команды безусловного перехода на метку Program_start, то есть снова на выполнение этой же команды.
Поскольку секция во флеше всего одна, то в scatter-файле для нашей программы в качестве First_Section_Name нужно будет указать именно её имя (то есть START).
В данном случае у нас перемешаны данные и команды. Адрес вершины стека и адрес точки входа (данные) записаны с помощью директив dcd прямо в секции кода. Так писать конечно можно, но не очень красиво. Особенно, если мы будем описывать всю таблицу прерываний и исключений (которая получится достаточно длинной), а не только вектор сброса. Гораздо красивее не загромождать код лишними данными, а поместить таблицу векторов прерываний в отдельную секцию, а ещё лучше — в отдельный файл. Аналогично, в отдельной секции или даже файле можно разместить и инициализацию стека. Мы, для примера, разместим всё в отдельных секциях:
AREA STACK, NOINIT, READWRITE SPACE 0x400 ; пропускаем 400 байт Stack_top ; и ставим метку AREA RESET, DATA, READONLY dcd Stack_top ; адрес метки Stack_top dcd Program_start ; адрес метки Program_start AREA PROGRAM, CODE, READONLY ENTRY ; точка входа (начало исполняемого кода) Program_start ; метка начала программы b Program_start END
Ну вот, та же самая программа (которая по прежнему не делает нифига полезного), но теперь выглядит намного нагляднее. В scatter-файле для этой программы нужно указать в качестве First_Section_Name имя RESET, чтобы эта секция располагалась во flash-памяти первой.
Привет всем!
По роду деятельности я программист на Java. Последние месяцы работы заставили меня познакомиться с разработкой под Android NDK и соответственно написание нативных приложений на С. Тут я столкнулся с проблемой оптимизации Linux библиотек. Многие оказались абсолютно не оптимизированы под ARM и сильно нагружали процессор. Ранее я практически не программировал на ассемблере, поэтому сначала было сложно начать изучать этот язык, но все же я решил попробовать. Эта статья написана, так сказать, от новичка для новичков. Я постараюсь описать те основы, которые уже изучил, надеюсь кого-то это заинтересует. Кроме того, буду рад конструктивной критике со стороны профессионалов.
Введение
Итак, для начала разберёмся что же такое ARM. Википедия дает такое определение:Архитектура ARM (Advanced RISC Machine, Acorn RISC Machine, усовершенствованная RISC-машина) - семейство лицензируемых 32-битных и 64-битных микропроцессорных ядер разработки компании ARM Limited. Компания занимается исключительно разработкой ядер и инструментов для них (компиляторы, средства отладки и т. п.), зарабатывая на лицензировании архитектуры сторонним производителям.
Если кто не знает, сейчас большая часть мобильных устройств, планшетов разработаны именно на этой архитектуре процессоров. Основным преимуществом данного семейства является низкое энергопотребление, благодаря чему он часто используется в различных встроенных системах. Архитектура развивалась с течением времени, и начиная с ARMv7 были определены 3 профиля: ‘A’(application) - приложения, ‘R’(real time) - в реальном времени,’M’(microcontroller) - микроконтроллер. Историю разработки этой технологии и другие интересный данные вы можете прочитать в Википедии или погуглив в интернете. ARM поддерживает разные режимы работы (Thumb и ARM, кроме того в последние время появился Thumb-2, являющийся смесью ARM и Thumb). В данной статье рассмотрим собственно режим ARM, в котором исполняется 32-битный набор команд.
Каждый ARM процессор создан из следующих блоков:
- 37 регистров (из которых видимых при разработке только 17)
- Арифметико-логи́ческое устройство (АЛУ) - выполняет арифметические и логические задачи
- Barrel shifter - устройство, созданное для перемещения блоков данных на определенное количество бит
- The CP15 - специальная система, контроллирующая ARM сопроцессоры
- Декодер инструкций - занимается преобразованием инструкции в последовательность микроопераций
Конвейерное исполнение (Pipeline execution)
В ARM процессорах используется 3-стадийный конвейер (начиная с ARM8 был реализова 5-стадийный конвейер). Рассмотрим простой конвейер на примере процессора ARM7TDMI. Исполнение каждой инструкции состоит из трёх ступеней:1. Этап выборки (F)
На этом этапе инструкции поступают из ОЗУ в конвейер процессора.
2. Этап декодирования (D)
Инструкции декодируются и распознаётся их тип.
3. Этап исполнения (E)
Данные поступают в ALU и исполняются и полученное значение записывается в заданный регистр.
Но при разработке надо учитывать, что, есть инструкции, которые используют несколько циклов исполнения, например, load(LDR) или store. В таком случае этап исполнения (E) разделяется на этапы (E1, E2, E3...).
Условное выполнение
Одна из важнейших функций ARM ассемблера - условное выполнение. Каждая инструкция может исполняться условно и для этого используются суффиксы. Если суффикс добавляется к названию инструкции, то прежде чем выполнить ее, происходит проверка параметров. Если параметры не соответствуют условию, то инструкция не выполняется. Суффиксы:MI - отрицательное число
PL - положительное или ноль
AL - выполнять инструкцию всегда
Суффиксов условного выполнения намного больше. Остальные суффиксы и примеры прочитать в официальной документации: ARM документация
А теперь пришло время рассмотреть…
Основы синтаксиса ARM ассемблера
Тем, кто раньше работал с ассемблером этот пункт можно фактически пропустить. Для всех остальных опишу основы работы с этим языком. Итак, каждая программа на ассемблере состоит из инструкций. Инструкция создаётся таким образом:{метка} {инструкция|операнды} {@ комментарий}
Метка - необязательный параметр. Инструкция - непосредственно мнемоника инструкции процессору. Основные инструкции и их использование будет разобрано далее. Операнды - константы, адреса регистров, адреса в оперативной памяти. Комментарий - необязательный параметр, который не влияет на исполнение программы.
Имена регистров
Разрешены следующие имена регистров:1.r0-r15
3.v1-v8 (переменные регистры, с r4 по r11)
4.sb and SB (статический регистр, r9)
5.sl and SL (r10)
6.fp and FP (r11)
7.ip and IP (r12)
8.sp and SP (r13)
9.lr and LR (r14)
10.pc and PC (программный счетчик, r15).
Переменные и костанты
В ARM ассемблере, как и любом (практически) другом языке программирования могут использоваться переменные и константы. Они разделяются на такие типы:- Числовые
- Логические
- Строковые
a SETA 100; создается числовая переменная «a» с значением 100.
Строковые переменные:
improb SETS «literal»; создается переменная improb с значение «literal». ВНИМАНИЕ! Значение переменной не может превышать 5120 символов.
В логических переменных соответственно используются значения TRUE и FALSE.
Примеры инструкций ARM ассемблера
В данной таблице я собрал основные инструкции, которая потребуется для дальнейшей разработки (на самом базовом этапе:):Чтобы закрепить использование основных инструкций давайте напишем несколько простых примеров, но сначала нам понадобится arm toolchain. Я работаю в Linux поэтому выбрал: frank.harvard.edu/~coldwell/toolchain (arm-unknown-linux-gnu toolchain). Ставится он проще простого, как и любая другая программа на Linux. В моем случае (Russian Fedora) понадобилось только установить rpm пакеты с сайта.
Теперь пришло время написать простейший пример. Программа будет абсолютно бесполезной, но главное, что будет работать:) Вот код, который я вам предлагаю:
start: @ Необязательная строка, обозначающая начало программы
mov r0, #3 @ Грузим в регистр r0 значение 3
mov r1, #2 @ Делаем тоже самое с регистром r1, только теперь с значением 2
add r2, r1, r0 @ Складываем значения r0 и r1, ответ записываем в r2
mul r3, r1, r0 @ Умножаем значение регистра r1 на значение регистра r0, ответ записываем в r3
stop: b stop @ Строка завершения программы
Компилируем программу до получения.bin файла:
/usr/arm/bin/arm-unknown-linux-gnu-as -o arm.o arm.s
/usr/arm/bin/arm-unknown-linux-gnu-ld -Ttext=0x0 -o arm.elf arm.o
/usr/arm/bin/arm-unknown-linux-gnu-objcopy -O binary arm.elf arm.bin
(код в файле arm.s, а toolchain в моем случае лежит в директории /usr/arm/bin/)
Если все прошло успешно, у вас будет 3 файла: arm.s (собственно код), arm.o, arm.elf, arm.bin (собственно исполняемая программа). Для того, чтобы проверить работу программы не обязательно иметь собственное arm устройство. Достаточно установить QEMU. Для справки:
QEMU - свободная программа с открытым исходным кодом для эмуляции аппаратного обеспечения различных платформ.Включает в себя эмуляцию процессоров Intel x86 и устройств ввода-вывода. Может эмулировать 80386, 80486, Pentium, Pentium Pro, AMD64 и другие x86-совместимые процессоры; PowerPC, ARM, MIPS, SPARC, SPARC64, m68k - лишь частично.
Работает на Syllable, FreeBSD, FreeDOS, Linux, Windows 9x, Windows 2000, Mac OS X, QNX, Android и др.
Итак, для эмуляции arm понадобится qemu-system-arm. Этот пакет есть в yum, так что тем, у кого Fedora, можно не заморачиваться и просто выполнить комманду:
yum install qemu-system-arm
Далее надо запустить эмулятор ARM, так, чтобы он выполнил нашу программу arm.bin. Для этого создадим файл flash.bin, который будет флэш памятью для QEMU. Сделать это очень просто:
dd if=/dev/zero of=flash.bin bs=4096 count=4096
dd if=arm.bin of=flash.bin bs=4096 conv=notrunc
Теперь грузим QEMU с полученой flash памятью:
qemu-system-arm -M connex -pflash flash.bin -nographic -serial /dev/null
На выходе вы получите что-то вроде этого:
$ qemu-system-arm -M connex -pflash flash.bin -nographic -serial /dev/null
QEMU 0.15.1 monitor - type "help" for more information
(qemu)
Наша программа arm.bin должна была изменить значения четырех регистров, следовательно для проверки правильности работы давайте посмотрим на эти самые регистры. Делается это очень простой коммандой: info registers
На выходе вы увидите все 15 ARM регистров, при чем у четырех из них будут измененные значения. Проверьте:) Значения регистров совпадают с теми, которые можно ожидать после исполнения программы:
(qemu) info registers
R00=00000003 R01=00000002 R02=00000005 R03=00000006
R04=00000000 R05=00000000 R06=00000000 R07=00000000
R08=00000000 R09=00000000 R10=00000000 R11=00000000
R12=00000000 R13=00000000 R14=00000000 R15=00000010
PSR=400001d3 -Z-- A svc32
P.S. В этой статье я постарался описать основы программирования на ARM ассемблер. Надеюсь вам понравилось! Этого хватит для того, чтобы далее углубляться в дебри этого языка и писать на нем программы. Если все получится, буду писать дальше о том, что узнаю сам. Если есть ошибки, прошу не пинать, так как я новичок в ассемблере.