On the period of operation of the pseudorandom sequence generator. Pseudo-random number generator – random
Note that ideally the distribution density curve random numbers would look like shown in Fig. 22.3. That is, ideally, each interval contains the same number of points: N i = N/k , Where N total number of points, k number of intervals, i= 1, , k .
generated theoretically by an ideal generator
It should be remembered that generating an arbitrary random number consists of two stages:
- generating a normalized random number (that is, uniformly distributed from 0 to 1);
- normalized random number conversion r i to random numbers x i, which are distributed over to the required user(arbitrary) distribution law or in the required interval.
Random number generators according to the method of obtaining numbers are divided into:
- physical;
- tabular;
- algorithmic.
Physical RNG
An example of a physical RNG can be: a coin (“heads” 1, “tails” 0); dice; a drum with an arrow divided into sectors with numbers; hardware noise generator (HS), which uses a noisy thermal device, for example, a transistor (Fig. 22.422.5).
| Task “Generating random numbers using a coin” | |
|
Generate a random three-digit number, uniformly distributed in the range from 0 to 1, using a coin. Accuracy three decimal places. |
|
The first way to solve the problem
Draw an interval from 0 to 1. Reading the numbers in sequence from left to right, split the interval in half and each time choose one of the parts of the next interval (if you get a 0, then the left one, if you get a 1, then the right one). Thus, you can get to any point in the interval, as accurately as you like. So, 1 : the interval is divided in half and , the right half is selected, the interval is narrowed: . Next number 0 : the interval is divided in half and , the left half is selected, the interval is narrowed: . Next number 0 : the interval is divided in half and , the left half is selected, the interval is narrowed: . Next number 1 : the interval is divided in half and , the right half is selected, the interval is narrowed: . According to the accuracy condition of the problem, a solution has been found: it is any number from the interval, for example, 0.625. In principle, if we take a strict approach, then the division of intervals must be continued until the left and right boundaries of the found interval COINCIDE with an accuracy of the third decimal place. That is, from the point of view of accuracy, the generated number will no longer be distinguishable from any number from the interval in which it is located.
The second way to solve the problem
|
Tabular RNG
Tabular RNGs use specially compiled tables containing verified uncorrelated, that is, in no way dependent on each other, numbers as a source of random numbers. In table Figure 22.1 shows a small fragment of such a table. By traversing the table from left to right from top to bottom, you can obtain random numbers evenly distributed from 0 to 1 with the required number of decimal places (in our example, we use three decimal places for each number). Since the numbers in the table do not depend on each other, the table can be traversed different ways, for example, from top to bottom, or from right to left, or, say, you can select numbers that are in even positions.
| Table 22.1. Random numbers. Evenly random numbers distributed from 0 to 1 |
||||||||||||||||||||||||||||||||||||||||||||
| Random numbers | Evenly distributed 0 to 1 random numbers |
|||||||
| 9 | 2 | 9 | 2 | 0 | 4 | 2 | 6 | 0.929 |
| 9 | 5 | 7 | 3 | 4 | 9 | 0 | 3 | 0.204 |
| 5 | 9 | 1 | 6 | 6 | 5 | 7 | 6 | 0.269 |
The advantage of this method is that it produces truly random numbers, since the table contains verified uncorrelated numbers. Disadvantages of the method: for storage large quantity numbers require a lot of memory; There are great difficulties in generating and checking such tables; repetitions when using a table no longer guarantee randomness number sequence, and therefore the reliability of the result.
There is a table containing 500 absolutely random verified numbers (taken from the book by I. G. Venetsky, V. I. Venetskaya “Basic mathematical and statistical concepts and formulas in economic analysis”).
Algorithmic RNG
The numbers generated by these RNGs are always pseudo-random (or quasi-random), that is, each subsequent number generated depends on the previous one:
r i + 1 = f(r i) .
Sequences made up of such numbers form loops, that is, there is necessarily a cycle that repeats infinite number once. Repeating cycles are called periods.
The advantage of these RNGs is their speed; generators require virtually no memory resources and are compact. Disadvantages: the numbers cannot be fully called random, since there is a dependence between them, as well as the presence of periods in the sequence of quasi-random numbers.
Let's consider several algorithmic methods for obtaining RNG:
- method of median squares;
- method of middle products;
- stirring method;
- linear congruent method.
Midsquare method
There is some four-digit number R 0 . This number is squared and entered into R 1 . Next from R 1 takes the middle (four middle digits) new random number and writes it into R 0 . Then the procedure is repeated (see Fig. 22.6). Note that in fact, as a random number you need to take not ghij, A 0.ghij with a zero and a decimal point added to the left. This fact is reflected as in Fig. 22.6, and in subsequent similar figures.
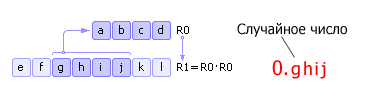 |
Disadvantages of the method: 1) if at some iteration the number R 0 becomes equal to zero, then the generator degenerates, so the correct choice of the initial value is important R 0 ; 2) the generator will repeat the sequence through M n steps (at best), where n number digit R 0 , M base of the number system.
For example in Fig. 22.6: if the number R 0 will be presented in binary system number, then the sequence pseudorandom numbers repeats in 2 4 = 16 steps. Note that the repetition of the sequence can occur earlier if the starting number is chosen poorly.
The method described above was proposed by John von Neumann and dates back to 1946. Since this method turned out to be unreliable, it was quickly abandoned.
Midproduct method
Number R 0 multiplied by R 1, from the result obtained R 2 the middle is extracted R 2 * (this is another random number) and multiplied by R 1 . All subsequent random numbers are calculated using this scheme (see Fig. 22.7).
 |
Stirring method
The shuffle method uses operations to cyclically shift the contents of a cell left and right. The idea of the method is as follows. Let the cell store the initial number R 0 . Cyclically shifting the contents of the cell to the left by 1/4 of the cell length, we obtain a new number R 0 * . In the same way, cycling the contents of the cell R 0 to the right by 1/4 of the cell length, we get the second number R 0**. Sum of numbers R 0* and R 0** gives a new random number R 1 . Further R 1 is entered in R 0, and the entire sequence of operations is repeated (see Fig. 22.8).
 |
Please note that the number resulting from the summation R 0* and R 0 ** , may not fit completely in the cell R 1 . In this case, the extra digits must be discarded from the resulting number. Let us explain this in Fig. 22.8, where all cells are represented by eight binary digits. Let R 0 * = 10010001 2 = 145 10 , R 0 ** = 10100001 2 = 161 10 , Then R 0 * + R 0 ** = 100110010 2 = 306 10 . As you can see, the number 306 occupies 9 digits (in the binary number system), and the cell R 1 (same as R 0) can contain a maximum of 8 bits. Therefore, before entering the value into R 1, it is necessary to remove one “extra”, leftmost bit from the number 306, resulting in R 1 will no longer go to 306, but to 00110010 2 = 50 10 . Also note that in languages such as Pascal, “trimming” of extra bits when a cell overflows is performed automatically in accordance with the specified type of the variable.
Linear congruent method
The linear congruent method is one of the simplest and most commonly used procedures currently simulating random numbers. This method uses the mod( x, y) , which returns the remainder when the first argument is divided by the second. Each subsequent random number is calculated based on the previous random number using the following formula:
r i+ 1 = mod( k · r i + b, M) .
The sequence of random numbers obtained using this formula is called linear congruent sequence. Many authors call a linear congruent sequence when b = 0 multiplicative congruent method, and when b ≠ 0 mixed congruent method.
For a high-quality generator, it is necessary to select suitable coefficients. It is necessary that the number M was quite large, since the period cannot have more M elements. On the other hand, the division used in this method is a rather slow operation, so for a binary computer the logical choice would be M = 2 N, since in this case finding the remainder of division is reduced inside the computer to binary logical operation"AND". Choosing the largest prime number is also common M, less than 2 N: in the specialized literature it is proven that in this case the low-order digits of the resulting random number r i+ 1 behave just as randomly as the older ones, which has a positive effect on the entire sequence of random numbers as a whole. As an example, one of the Mersenne numbers, equal to 2 31 1, and thus, M= 2 31 1 .
One of the requirements for linear congruent sequences is that the period length be as long as possible. The length of the period depends on the values M , k And b. The theorem we present below allows us to determine whether it is possible to achieve the period maximum length for specific values M , k And b .
Theorem. Linear congruent sequence defined by numbers M , k , b And r 0, has a period of length M if and only if:
- numbers b And M relatively simple;
- k 1 times p for every prime p, which is a divisor M ;
- k 1 is a multiple of 4, if M multiple of 4.
Finally, let's conclude with a couple of examples of using the linear congruent method to generate random numbers.
It was determined that a series of pseudo-random numbers generated based on the data from example 1 would be repeated every M/4 numbers. Number q is set arbitrarily before the start of calculations, however, it should be borne in mind that the series gives the impression of being random at large k(and therefore q). The result can be improved somewhat if b odd and k= 1 + 4 · q in this case the row will be repeated every M numbers. After a long search k the researchers settled on values of 69069 and 71365.
A random number generator using the data from Example 2 will produce random, non-repeating numbers with a period of 7 million.
The multiplicative method for generating pseudorandom numbers was proposed by D. H. Lehmer in 1949.
Checking the quality of the generator
The quality of the entire system and the accuracy of the results depend on the quality of the RNG. Therefore, the random sequence generated by the RNG must satisfy a number of criteria.
The checks carried out are of two types:
- checks for uniformity of distribution;
- tests for statistical independence.
Checks for uniformity of distribution
1) The RNG should produce close to the following values of statistical parameters characteristic of a uniform random law:
2) Frequency test
A frequency test allows you to find out how many numbers fall within an interval (m r σ r ; m r + σ r) , that is (0.5 0.2887; 0.5 + 0.2887) or, ultimately, (0.2113; 0.7887). Since 0.7887 0.2113 = 0.5774, we conclude that in a good RNG, about 57.7% of all random numbers drawn should fall into this interval (see Fig. 22.9).
in case of checking it for frequency test
It is also necessary to take into account that the number of numbers falling into the interval (0; 0.5) should be approximately equal to the number of numbers falling into the interval (0.5; 1).
3) Chi-square test
The chi-square test (χ 2 test) is one of the most well-known statistical tests; it is the main method used in combination with other criteria. The chi-square test was proposed in 1900 by Karl Pearson. His remarkable work is considered as the foundation of modern mathematical statistics.
For our case, testing using the chi-square criterion will allow us to find out how much the real The RNG is close to the RNG benchmark, that is, whether it satisfies the uniform distribution requirement or not.
Frequency diagram reference The RNG is shown in Fig. 22.10. Since the distribution law of the reference RNG is uniform, then the (theoretical) probability p i getting numbers into i th interval (all these intervals k) is equal to p i = 1/k . And thus, in each of k intervals will hit smooth By p i · N numbers ( N total number of numbers generated).
A real RNG will produce numbers distributed (and not necessarily evenly!) across k intervals and each interval will contain n i numbers (in total n 1 + n 2 + + n k = N ). How can we determine how good the RNG being tested is and how close it is to the reference one? It is quite logical to consider the squared differences between the resulting number of numbers n i and "reference" p i · N . Let's add them up and the result is:
χ 2 exp. = ( n 1 p 1 · N) 2 + (n 2 p 2 · N) 2 + + ( n k p k · N) 2 .
From this formula it follows that the smaller the difference in each of the terms (and therefore the smaller the value of χ 2 exp.), the stronger the law of distribution of random numbers generated by a real RNG tends to be uniform.
In the previous expression, each of the terms is assigned the same weight (equal to 1), which in fact may not be true; therefore, for chi-square statistics, it is necessary to normalize each i th term, dividing it by p i · N :
Finally, let’s write the resulting expression more compactly and simplify it:
We obtained the chi-square test value for experimental data.
In table 22.2 are given theoretical chi-square values (χ 2 theoretical), where ν = N 1 is the number of degrees of freedom, p this is a user-specified confidence level that indicates how much the RNG should satisfy the requirements of uniform distribution, or p is the probability that the experimental value of χ 2 exp. will be less than the tabulated (theoretical) χ 2 theor. or equal to it.
| Table 22.2. Some percentage points of the χ 2 distribution |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| p = 1% | p = 5% | p = 25% | p = 50% | p = 75% | p = 95% | p = 99% | |
| ν = 1 | 0.00016 | 0.00393 | 0.1015 | 0.4549 | 1.323 | 3.841 | 6.635 |
| ν = 2 | 0.02010 | 0.1026 | 0.5754 | 1.386 | 2.773 | 5.991 | 9.210 |
| ν = 3 | 0.1148 | 0.3518 | 1.213 | 2.366 | 4.108 | 7.815 | 11.34 |
| ν = 4 | 0.2971 | 0.7107 | 1.923 | 3.357 | 5.385 | 9.488 | 13.28 |
| ν = 5 | 0.5543 | 1.1455 | 2.675 | 4.351 | 6.626 | 11.07 | 15.09 |
| ν = 6 | 0.8721 | 1.635 | 3.455 | 5.348 | 7.841 | 12.59 | 16.81 |
| ν = 7 | 1.239 | 2.167 | 4.255 | 6.346 | 9.037 | 14.07 | 18.48 |
| ν = 8 | 1.646 | 2.733 | 5.071 | 7.344 | 10.22 | 15.51 | 20.09 |
| ν = 9 | 2.088 | 3.325 | 5.899 | 8.343 | 11.39 | 16.92 | 21.67 |
| ν = 10 | 2.558 | 3.940 | 6.737 | 9.342 | 12.55 | 18.31 | 23.21 |
| ν = 11 | 3.053 | 4.575 | 7.584 | 10.34 | 13.70 | 19.68 | 24.72 |
| ν = 12 | 3.571 | 5.226 | 8.438 | 11.34 | 14.85 | 21.03 | 26.22 |
| ν = 15 | 5.229 | 7.261 | 11.04 | 14.34 | 18.25 | 25.00 | 30.58 |
| ν = 20 | 8.260 | 10.85 | 15.45 | 19.34 | 23.83 | 31.41 | 37.57 |
| ν = 30 | 14.95 | 18.49 | 24.48 | 29.34 | 34.80 | 43.77 | 50.89 |
| ν = 50 | 29.71 | 34.76 | 42.94 | 49.33 | 56.33 | 67.50 | 76.15 |
| ν > 30 | ν + sqrt(2 ν ) · x p+ 2/3 · x 2 p 2/3 + O(1/sqrt( ν )) | ||||||
| x p = | 2.33 | 1.64 | 0.674 | 0.00 | 0.674 | 1.64 | 2.33 |
Considered acceptable p from 10% to 90%.
If χ 2 exp. much more than χ 2 theory. (that is p is large), then the generator does not satisfy the requirement of uniform distribution, since the observed values n i go too far from theoretical p i · N and cannot be considered random. In other words, such a large confidence interval is established that the restrictions on the numbers become very loose, the requirements on the numbers become weak. In this case, a very large absolute error will be observed.
Even D. Knuth in his book “The Art of Programming” noted that having χ 2 exp. for small ones, in general, it’s also not good, although this seems, at first glance, to be wonderful from the point of view of uniformity. Indeed, take a series of numbers 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, they are ideal from the point of view of uniformity, and χ 2 exp. will be practically zero, but you are unlikely to recognize them as random.
If χ 2 exp. much less than χ 2 theory. (that is p small), then the generator does not satisfy the requirement of a random uniform distribution, since the observed values n i too close to theoretical p i · N and cannot be considered random.
But if χ 2 exp. lies in a certain range between two values of χ 2 theor. , which correspond, for example, p= 25% and p= 50%, then we can assume that the random number values generated by the sensor are completely random.
In addition, it should be borne in mind that all values p i · N must be large enough, for example more than 5 (found out empirically). Only then (with a sufficiently large statistical sample) can the experimental conditions be considered satisfactory.
So, the verification procedure is as follows.
Tests for statistical independence
1) Checking for the frequency of occurrence of numbers in the sequence
Let's look at an example. The random number 0.2463389991 consists of the digits 2463389991, and the number 0.5467766618 consists of the digits 5467766618. Connecting the sequences of digits, we have: 24633899915467766618.
It is clear that the theoretical probability p i loss i The th digit (from 0 to 9) is equal to 0.1.
2) Checking the appearance of series of identical numbers
Let us denote by n L number of series of identical digits in a row of length L. Everything needs to be checked L from 1 to m, Where m this is a user-specified number: the maximum occurring number of identical digits in a series.
In the example “24633899915467766618” 2 series of length 2 (33 and 77) were found, that is n 2 = 2 and 2 series of length 3 (999 and 666), that is n 3 = 2 .
The probability of occurrence of a series of length L is equal to: p L= 9 10 L (theoretical). That is, the probability of occurrence of a series one character long is equal to: p 1 = 0.9 (theoretical). The probability of a series of two characters appearing is: p 2 = 0.09 (theoretical). The probability of a series of three characters appearing is: p 3 = 0.009 (theoretical).
For example, the probability of occurrence of a series one character long is p L= 0.9, since there can be only one symbol out of 10, and there are 9 symbols in total (zero does not count). And the probability that two identical symbols “XX” will appear in a row is 0.1 · 0.1 · 9, that is, the probability of 0.1 that the symbol “X” will appear in the first position is multiplied by the probability of 0.1 that the same symbol will appear in the second position “X” and multiplied by the number of such combinations 9.
The frequency of occurrence of series is calculated using the chi-square formula we previously discussed using the values p L .
Note: The generator can be tested multiple times, but the tests are not complete and do not guarantee that the generator produces random numbers. For example, a generator that produces the sequence 12345678912345 will be considered ideal during tests, which is obviously not entirely true.
In conclusion, we note that the third chapter of Donald E. Knuth's book The Art of Programming (Volume 2) is entirely devoted to the study of random numbers. It studies various methods generating random numbers, statistical tests of randomness, and converting uniformly distributed random numbers to other types of random variables. More than two hundred pages are devoted to the presentation of this material.
Pseudo-random sequence generators
In practice, one of the most important is the following task. Based on the above and other properties of the RRSP, it is necessary to determine whether a particular sequence is an implementation of the RRSP. In what follows, for the sake of brevity, we will simply call the implementation of the RRSP a random sequence.
A constructive approach to defining a random sequence was proposed by Blum, Goldwasser, Micalli and Yao. Their definition considers a sequence to be random unless there is a polynomial (probabilistic) algorithm that can distinguish it from pure randomness. This sequence is called polynomially indistinguishable from random or pseudorandom.
This approach allows you to use pseudo-random sequences (PSR) to generate deterministic algorithms implemented finite state machines. Although from a mathematical point of view such sequences are not random, since they are completely determined by the initial filling, nevertheless, their practical use does not provide any advantages to the cryptanalyst due to its “indistinguishability” from random ones. Since this approach seems more constructive, we will dwell on it in more detail.
Random Sequences In terms of last definition also called “random for all” practical applications" Generators of such sequences are called cryptographically secure ( cryptographically strong) or cryptographically secure ( cryptographically secure). Pseudo-randomness in in this case there is not only a property of the sequence (or generator), but also a property of the observer, or rather his computational capabilities.
Two important statements have been proven for PSP:
1. A sequence is pseudorandom if and only if it unpredictable, i.e. withstands testing with the next bit. This means that even if a part of a sequence of any length is known, then for unknown initial filling generator and the parameters of the generation algorithm to obtain the next bit, it is impossible to offer an algorithm that is significantly better than simple guessing or tossing a coin.
2. Cryptographically strong generators exist if and only if there are functions that are easily computable, but computationally difficult to invert (one-way functions - one-way functions). In this case, each PSP generator can be assigned a one-to-one correspondence with a certain one-way function, which depends on certain parameters.
The simplest pseudorandom number sensor is linear congruent generator(LKG), which is described by a recurrent equation of the form X n =(aX n -1 +b) mod N, Where X 0 – random initial value, A– multiplier, b– increment, N– module.
The period of the output sequence of such a generator does not exceed N, maximum value achieved with the correct choice of parameters a,b,N, namely, when
· numbers N And b coprime: GCD(N,b)=1);
· a-1 multiple of any prime p, dividing N;
· a-1 multiple 4 , If N multiple 4 .
Below is a list of constants for LCG that ensure the maximum period of the sequence and, equally important, the corresponding sequences pass statistical tests.
To implement LKG on personal computers taking into account their bit grid, the module is often used N=2 31 -1»2.14×10 9. In this case, the highest quality statistical properties of the PSP are achieved for the constant a=397204094.
Compared to other types of PSP generators this type provides high performance due to the small number of operations to create one pseudo-random bit.
The disadvantage of LCGs in terms of their use for creating stream ciphers is the predictability of the output sequences. Effective attacks on LKG have been proposed Joan Boyar, she owns methods of attacks on quadratic ‑ X n =(aX n -1 2 +bX n -1 +c)modNand cubic ‑ X n =(aX n -1 3 +bX n -1 2 +cX n -1 +d)modN generators.
Other researchers have summarized the results of the work Boyar for the case of a general polynomial congruent generator. Stern And Boyar showed how to crack the LKG, even if not the entire sequence is known.
Wishmann And Hill, and later Pierre L'Ecuger studied LCG combinations. The results are not cryptographically stronger, but have longer periods and behave better under some randomness criteria.
Linear Feedback Shift Registers (Linear Feedback Shift Registers - LFSR) include the shift register itself and the circuit for calculating the feedback function ( tap sequence) – see fig. 12:
| Bit stream |
| n |
| ∙∙∙ |
| 2 |
| 1 |
Rice. 2. Linear feedback shift register ( LFSR)
In the diagram, the contents of the register - a sequence of bits - are shifted with the arrival of a clock pulse ( clock pulse) one place to the right. The least significant bit is considered the output LFSR in this work cycle. The value of the most significant digit is the result of addition by mod2(XOR function) feedback bits.
In theory, n-bit LFSR can generate a pseudo-random sequence with a period 2n-1 bit, such LFSR are called maximum period registers. To do this, the shift register must visit all 2n-1 internal states ( 2n-1, because filling the shift register with zero will cause an infinite sequence of zeros).
Recall that a polynomial is called irreducible if it cannot be expressed as the product of other polynomials of lesser degree different from 1 and itself.
Primitive polynomial degrees n is an irreducible polynomial that divides but does not divide x d +1 for anyone d: (2n-1│d)
Theorem(without proof): For the LFSR to have a maximum period, it is necessary and sufficient that the polynomial formed from the feedback elements ( tap sequence) plus one was a primitive polynomial modulo 2. (In fact, a primitive polynomial is a generator in a given field).
A list of practically applicable primitive polynomials is given in.
For example, a primitive polynomial is x 32 x 7 x 5 x 3 x 2 x1. Record ( 32,7,5,3,2,1,0 ) means that by taking a 32-bit shift register and generating a feedback bit by adding over mod2 7th, 5th, 3rd, 2nd and 1st bits, we get LFSR maximum length (with 2 32 -1 states).
Note that if p(x) is a primitive polynomial, then x n ×p(1/x)– also primitive.
For example, if the polynomial (a,b,0) primitive, then (a,a-b,0)– primitive. If a polynomial (a,b,c,d,0) primitive, then (a,a-d,a-c,a-b,0)– primitive, etc.
Primitive trinomials are especially convenient because Only 2 bits of the shift register are added, but they are also more vulnerable to attacks.
LFSR– convenient for technical implementation, but have unpleasant properties. Consecutive bits are linearly dependent, which makes them useless for encryption. Even if the feedback circuit is unknown, it is sufficient 2n output bits to determine it.
Large random numbers generated from sequential bits LFSR, are highly correlated and sometimes not even completely random. Nevertheless, LFSR quite often used as elements of more complex algorithms for generating an encryption key sequence.
There are also a number of PSP generators (including Fibonacci number generators), which for a number of reasons have not found wide application in cryptographic systems. Most effective solutions were obtained on the basis of composite generators.
The idea of constructing a compound generator is based on the fact that a combination of two or more simple PSP generators, in the case of the correct choice of the combining function (incl. mod 2, mod 2 32 -1 etc.), provides a generator with improved randomness properties, and, as a result, with increased cryptographic strength.
In the case of creating a cryptographically strong PSP generator, the issue of creating stream ciphers is simply resolved. The output of such PSP is indistinguishable (or rather, should be indistinguishable) from RRSP. Two generators can always be started synchronously from a single initial state vector, which is much shorter than the transmitted message, which distinguishes this scheme from the Vernam cipher.
There are 4 known approaches to designing appropriate generators:
1) system-theoretical approach;
2) complexity-theoretical approach;
3) information-theoretical approach;
4) randomized approach.
These approaches differ in their assumptions about the cryptanalyst's capabilities, the definition of cryptographic success, and the concept of reliability.
When system-theoretical approach the cryptographer creates a keystream generator that has verifiable properties, including the period length of the output sequence, the statistical distribution of the bitstream, the linear complexity of the transformation, etc. Taking into account known cryptanalysis techniques, the cryptographer optimizes the generator against these attacks.
Based on this approach, Rüppel formulated the following set of criteria for stream ciphers:
1. Long period of the output sequence, no repetitions;
2. High linear complexity, as a characteristic of our generator through a register LFSR the minimum length that can generate the same output;
3. Indistinguishability from RRSP according to statistical criteria;
4. Shuffle: any bit of the key stream must be a complex transformation of all or most of the bits of the initial state (key);
5. Dissipation: redundancy in all substructures of the generator algorithm must be dissipated;
6. Criteria for nonlinearity of transformations: in accordance with some metric, the distance to linear functions should be large enough, the criterion for the avalanche-like propagation of changes in the case of a change in one bit, etc.
Practice confirms the advisability of applying the specified criteria not only for the analysis and evaluation of stream ciphers created within the framework of a system-theoretical approach, but also for any stream and block ciphers.
The main problem with such cryptosystems is that it is difficult for them to prove any facts about their cryptographic strength, since for all these criteria their necessity or sufficiency has not been proven. A stream cipher can satisfy all of these principles and still be weak because resistance to a given set of cryptanalytic attacks does not guarantee anything.
An example of a successful construction of a composite generator from the point of view of increasing linear complexity is the Goleman cascade (Fig. 3).
The Goleman stage includes several registers LFSR, and the timing of each next LSFR controlled by the previous one so that the state change LFSR-(k+1) at time t occurs if in the previous step t-1 exit LFSR-k equals 1, and LFSR-(k+1) does not change its state otherwise.
If all LFSR– lengths l, then the linear complexity of the system with n registers equal l×(2 l-1)n-1.
| X(t) |
| LFSR-2 |
| LFSR-3 |
| Tact |
Rice. 4. Alternating start-stop generator
This generator has a long period and high linear complexity.
Applying complexity-theoretical approach, the cryptographer is trying to prove the strength of the generator using complexity theory. The basis for solutions in this approach are generators based on the concept unidirectional function.
One-way function f(x): D→R easy to calculate for everyone x О D, but it is very difficult to invert for almost all values from R. Otherwise, if V is the computational complexity of obtaining f(x), and V * is the computational complexity of finding f -1(x), then the inequality V * >>V holds. It is easy to see that a candidate for a one-way function can be a power function in some finite field f(x)=a x, Where a,xОGF(q)– Galois field from q elements.
It is easy to see that multiplication, due to the associativity property, can be performed in less than the number x-1 steps. For example, a 9 =a×((a 2) 2) 2, which allows you to calculate the required degree instead of eight in four steps (first a 2 =a × a, then a 4 =a 2 a 2, a 8 =a 4 a 4 and finally a 9 =a 8 a).
The inverse operation - finding the exponent from the value of the power function (logarithm) - in a finite field cannot yet be solved better than using optimized enumeration methods possible options. When big size fields (of order 2 1024 )this task is modern development computer technology is computationally intractable.
An example of a corresponding generator is the algorithm RSA. Let the parameter N=p×q, Where p,q– prime numbers, initial value of the generator x 0 N, e: GCD( e,(p-1)×(q-1))=1.
| x i+1 =x e i mod N |
The generator result is the smallest significant bit x i+1. The durability of this generator is equivalent to the durability RSA. If N large enough, the generator provides practical durability.
Another example of a generator built on a complexity approach is proposed Bloom, Bloom And Shub (BBS). On this moment This is one of the simple and effective algorithms. The mathematical theory of this generator is quadratic modulo residues n.
Let's choose two large prime numbers p And q, giving remainder 3 when divided by 4. Product n pq Let's call it the Bloom number. Let's choose X: GCD( n,x)=1. Let's find the initial value of the generator: x 0 =x 2 mod n.
Now i The th pseudorandom number is the least significant bit x i, Where x i =x 2 i -2 mod n.
Note that to obtain i- th bit, no calculation required ( i-1) states. If we know p,q, then we can calculate it immediately: b i There is smallest value bit:
This property allows you to use BBS- generator for working with random access files ( random-access).
Number n can be distributed freely so that each network subscriber can independently generate the necessary bits. Moreover, if the cryptanalyst cannot factorize the number n, it will not be able to predict the next bit, even in a probabilistic sense, such as "there is a 51% chance that the next bit is 1".
Note; that generators built on unidirectional functions are very slow; special processors are required for their practical implementation.
Next two approaches information theoretical and randomized have not found widespread practical application.
From point of view information-theoretical the most the best remedy in the fight against a cryptanalyst who has endless computing resources and time, is a one-time tape or one-time pad.
When randomized approach, the goal is to increase the number of bits that the cryptanalyst needs to work with (without increasing the key). This can be achieved by using large random public strings. The key will indicate which parts of these strings need to be used for encryption and decryption. Then the cryptanalyst will have to use the method of total search of options (brute force) on random strings.
The strength of this method can be expressed in terms of the average number of bits that a cryptanalyst would have to examine before the odds of determining the key become better than simple guessing.
Ueli Maurer described such a scheme. The probability of breaking such a cryptosystem depends on the amount of memory available to the cryptanalyst (but does not depend on his computing resources).
For this scheme to take on a practical form, about 100 bit sequences are required. 10 20 bit each. Digitizing the lunar surface is one way to obtain such a number of bits.
In conclusion, we note that to build a PSP generator it is necessary to obtain a few random bits. The simplest way is to use the least significant bit of the computer's timer.
Using this method, you cannot receive many bits, because Each call to the bit generation procedure can take an even number of timer steps, which will certainly affect the properties of the sequence.
Most The best way to obtain a random number is to resort to the natural randomness of the real world - noise as a result of transient processes in semiconductor diodes, thermal noise of high resistors, radioactive decay, etc. In principle, there is an element of randomness in computers:
Time of day;
CPU load;
Arrival time network packets and so on.
The problem is not to find the sources of randomness, but to maintain randomness in measurements.
For example, this can be done like this: let’s find an event that happens regularly, but randomly (the noise exceeds a certain threshold). Let's measure the time between the first event and the second, then between the second and third. If t 1.2 t 2.3, then we set the output of the generator equal to 1; If t 1,2 < t 2.3, then the output is 0. We will continue the process.
The American National Standards Institute (ANSI) has developed a method for generating 64-bit keys using the DES algorithm (ANSI X9.17). Its main purpose is to obtain a large number of keys for multiple communication sessions. Instead of the DES algorithm, you can use any other strong encryption algorithm.
Let the function E K (P) encrypt P using the DES algorithm on a pre-prepared key K, which is used only for generating secret keys. Next, let V 0 be the initial 64-bit value that is kept secret from the enemy, and T i represent the date-time stamp when the i-th key. Then the next random key R i is calculated using the transformation:
R i = E K (E K (T i) Å V i)
To get the next value of V i , you need to calculate
V i = E K (E K (T i) Å R i)
A significant problem with random data generation systems is the presence of deviations and correlations in the generated sequence. The processes themselves may be random, but problems can arise during the measurement process. How to deal with this?
1) Addition by mod 2 two independent sequences: if a random bit is shifted to 0 by the amount ε , then the probability of occurrence of 0 can be written as P(0)=0.5+ε.
Addition by mod 2: two equally distributed independent bits will give: P(0)=(0.5 +ε) 2+(0.5-ε) 2=0.5 +2×ε 2 , adding four bits we get: P(0)=0.5+8 ε 4, etc. The process converges to an equiprobable distribution of 0 and 1.
2) Let the distribution of ones and zeros in the sequence be the quantities p And q respectively. Let's use the encoding method: consider two bits:
If these are identical bits, then discard them and consider the next pair;
If the bits are different, then we take the first bit as the output value.
This method allows you to solve the bias problem while preserving the randomness properties of the source (with some loss in data volume).
A potential problem with both methods is that when there is correlation between adjacent bits, these methods increase the offset. One way to avoid this is to use different sources of random numbers.
The fact that a random number generator has a bias, generally speaking, does not mean that it is unsuitable. For example, to generate a 112-bit key for the “triple” algorithm DES(Triple DES) a generator with a bias to zero is used: P(x t =0)=0.55, P(x t =1)=0.45(entropy N= 0.99277 per key bit compared to 1 for an ideal generator).
In this case, the attacker can optimize the total key search procedure by searching for the key starting from the most probable value ( 00…0 ) and ending with the least likely ( 11…1 ). Due to the presence of bias, we can expect to find the key in an average of 2 109 attempts. If there were no displacement, then it would be necessary 2 111 attempts. There is a gain, but it is insignificant.
IN computer programs Emulation of randomness is often required. For example, when developing games. If the program has a certain generator, i.e., a producer, of a random number, then, using the number obtained in this way, you can select one or another branch of program execution, or an arbitrary object from the collection. In other words, the main thing is to generate a number. Emulation of a different kind of randomness is based on it.
We certainly don’t know whether there is randomness in nature, or whether it only seems to us due to the limitations of our knowledge. We only know that there is no real randomness in programming. Nowhere to come from any number, you can’t program it to appear out of nowhere. You can only create a program that, as a result of applying complex formula to the “grain” will produce a number, and it will seem to us that this number is random.
“Grain” is the input data for the formula. They could be, for example, system time in milliseconds, which is constantly changing. Consequently, the “grain” will be constantly different. Or the programmer can set it himself.
Such a program (in reality a module or function) is called a pseudorandom number generator. Included in the standard library Python language includes the random module. It contains many functions related to emulating randomness (for example, “shuffling” elements of a sequence), and not just functions for generating pseudorandom numbers.
This tutorial will cover the random(), randrange() and randint() functions from the random module. Please note that the random module contains the random() function of the same name. It happens.
To access functions, you need to import the random module:
>>> import random
Or import individual functions from it:
>>> from random import random , randrange, randint
Functions for obtaining "random" integer numbers - randint() and randrange()
The randint() and randrange() functions generate pseudorandom integers. The first of them is the simplest and always takes only two arguments - the limits of the integer range from which any number is selected:
>>> random .randint (0 , 10 ) 6
or (if individual functions were imported):
>>> randint(100 , 200 ) 110
In the case of randint(), both boundaries are included in the range, i.e., in the language of mathematics, the segment is described as .
Numbers can be negative:
>>> random .randint (-100 , 10 ) -83 >>> random .randint (-100 , -10 ) -38
But the first number must always be less than or at least equal to the second. That is, a<= b.
The randrange() function is more complex. It can take one argument, two or even three. If only one is specified, then it returns a random number between 0 and the specified argument. Moreover, the argument itself is not included in the range. In the language of mathematics, this is; function* rand() ( for (let i=3; i<1000; i++) {
if (i >99) i = 2; for (let n=0; n
We got a generator of numbers from 0 to 9, but the distribution is very uneven and it will generate the same sequence every time.
We can take not the number Pi, but time in numerical representation and consider this number as a sequence of numbers, and in order to ensure that the sequence does not repeat each time, we will read it from the end. In total, our algorithm for our PRNG will look like this:
Function* rand() ( let newNumVector = () => [...(+new Date)+""].reverse(); let vector = newNumVector(); let i=2; while (true) ( if ( i++ > 99) i = 2; let n=-1; while (++n< vector.length) yield (vector[n] % i);
vector = newNumVector();
}
}
// TEST:
let i = 0;
for (let x of rand()) {
if (i++ >100) break; console.log(x)
This already looks like a pseudo-random number generator. And the same Math.random() is a PRNG, we’ll talk about it a little later. Moreover, each time we get a different first number.
Actually on these simple examples you can understand how more work complex generators random numbers. And there's even ready-made algorithms. As an example, let’s look at one of them — this is the Linear Congruent PRNG (LCPRNG).
Linear congruent PRNG
Linear congruent PRNG (LCPRNG) is a common method for generating pseudorandom numbers. It is not cryptographically strong. This method consists of calculating the terms of a linear recurrent sequence modulo some natural number m, given by the formula. The resulting sequence depends on the choice of starting number — i.e. seed. At different meanings seed produces different sequences of random numbers. An example of implementing such an algorithm in JavaScript:Const a = 45; const c = 21; const m = 67; var seed = 2; const rand = () => seed = (a * seed + c) % m; for(let i=0; i<30; i++)
console.log(rand())
Many programming languages use LCPRNG (but not exactly this algorithm(!)).
As mentioned above, such a sequence can be predicted. So why do we need PRNG? If we talk about security, then PRNG is a problem. If we talk about other tasks, then these properties can be a plus. For example, for various special effects and graphics animations, you may need to frequently call random. And this is where the distribution of meanings and performance are important! Secure algorithms cannot boast of speed.
Another property is reproducibility. Some implementations allow you to specify a seed, and this is very useful if the sequence must be repeated. Reproduction is needed in tests, for example. And there are many other things that do not require a secure RNG.
How Math.random() works
The Math.random() method returns a pseudo-random floating point number from the range = crypto.getRandomValues(new Uint8Array(1)); console.log(rvalue)
But, unlike the Math.random() PRNG, this method is very resource-intensive. The fact is that this generator uses system calls in the OS to gain access to entropy sources (mac address, CPU, temperature, etc...).