Mysql combining tables into one. We combine, aggregate, group
SQL - Lesson 6. Joining tables (inner join)
Suppose we want to find out which topics were created by which authors. To do this, the easiest way is to refer to the Topics table:
But what if we need the response to the request to contain not the identifiers of the authors, but their names? Nested queries will not help us, because... they end up producing data from the same table. And we need to get data from two tables (Topics and Users) and combine them into one. Queries that allow you to do this are called in SQL Associations.
The syntax for the simplest join is as follows:
SELECT table_column_names_1, table_column_names_2 FROM table_name_1, table_name_2;
Let's create a simple union:

It didn't turn out quite what we expected. Such a union is scientifically called a Cartesian product, when each row of the first table is associated with each row of the second table. There may be cases where such a union is useful, but this is clearly not our case.
To make the resulting table look the way we wanted, we need to specify a join condition. We link our tables by author ID, this will be our condition. Those. We will indicate in the query that it is necessary to display only those rows in which the values of the id_author field of the topics table match the values of the id_user field of the users table:

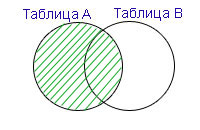
The diagram will make it clearer:

Those. We made the following condition in the query: if both tables have the same identifiers, then the rows with this identifier must be combined into one resulting row.
Please note two things:
- If one of the tables being joined has a row with an identifier that is not in the other table being joined, then the resulting table will not have a row with that identifier. In our example, there is a user Oleg (id=5), but he did not create topics, so the result of the request does not include him.
- When specifying a condition, the name of the column is written after the name of the table in which this column is located (separated by a dot). This is done to avoid confusion, because columns in different tables may have the same names, and MySQL may not understand which specific columns we are talking about.
SELECT table_name_1.table_1_column_name, table_name_1.table_1_column_name, table_name_2.table_2_column_name, table_name_2. table_name_2_2 FROM table_name_1, table_name_2 WHERE table_name_1.name_column join_by_name = table_name_2.column_name_by_joined;
If the column name is unique, then the table name can be omitted (as we did in the example), but this is not recommended.
As you understand, joins make it possible to select any information from any tables, and there can be three or four tables to be joined, and there can be more than one condition for the join.
As an example, let's create a query that will show us all messages, what topics they belong to and the authors of these messages. Of course, all this information is stored in the Posts table:

But in order for names and titles to be displayed instead of identifiers, we will have to join three tables:

Those. we joined the Messages and Users tables with the condition posts.id_author=users.id_user, and the Messages and Topics tables with the condition posts.id_topic=topics.id_topic

The associations we looked at today are called Internal associations. Such joins connect the rows of one table with the rows of another table (and maybe even a third table). But there are situations when it is necessary for rows that are not related to be included in the result. For example, when we created a query about which topics were created by which authors, the user Oleg was not included in the resulting table, because did not create topics, and therefore did not have a related row in the merged table.
Therefore, if we need to create a slightly different query - to display all users and topics that they created, if any - then we will have to use External association, which allows you to display all the rows of one table and the existing associated rows from another table. We will talk about such associations in the next lesson.
The SQL JOIN operator is designed to join two or more database tables based on matching conditions. This operator exists only in relational databases. It is thanks to JOIN that relational databases have such powerful functionality that allows not only data storage, but also their, at least the simplest, analysis using queries. Let's look at the main nuances of writing SQL queries with the JOIN operator, which are common to all DBMSs (database management systems). To join two tables, the SQL JOIN operator has the following syntax:
SELECT COLUMN_NAMES (1..N) FROM TABLE_NAME_1 JOIN TABLE_NAME_2 ON CONDITION
One or more links with a JOIN operator may be followed by an optional WHERE or HAVING section, in which, just like in a simple SELECT query, the selection condition is specified. Common to all DBMSs is that in this construction, instead of JOIN, INNER JOIN, LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL OUTER JOIN, CROSS JOIN (or, alternatively, a comma) can be specified.
INNER JOIN
A query with the INNER JOIN operator is designed to join tables and display the resulting table in which the data completely intersects according to the condition specified after ON.
A simple JOIN does the same thing. Thus, the word INNER is optional.
Example 1. There is a database of the advertisement portal. It contains a table of Categories (categories of advertisements) and Parts (parts, or otherwise - headings, which belong to categories). For example, the parts Apartments and Cottages belong to the Real Estate category, and the parts Cars and Motorcycles belong to the Transport category. These tables with filled data look like this:
Parts table:
Note that in the Parts table, Books have a Cat - a link to a category, which is not in the Categories table, and in the Categories table, Equipment has a Cat_ID - a primary key, a link to which is not in the Parts table. It is required to combine the data from these two tables so that the resulting table contains the Part, Cat and Price fields and so that the data completely overlaps according to the condition. The condition is a match between the category identifier in the Categories table and the link to the category in the Parts table. To do this, write the following request:
SELECT PARTS.Part, CATEGORIES.Cat_ID AS Cat, CATEGORIES.Price FROM PARTS INNER JOIN CATEGORIES ON PARTS.Cat = CATEGORIES.Cat_ID
| Part | Cat | Price |
| Apartments | 505 | 210,00 |
| Cars | 205 | 160,00 |
| Boards | 10 | 105,00 |
| Cabinets | 30 | 77,00 |
There are no Books in the resulting table because this record references a category that is not in the Categories table, and Equipment because this record has a foreign key in the Categories table that is not referenced in the Parts table.
In some cases, when joining tables, you can create less cumbersome queries using EXISTS predicate and without using JOIN.
There is a database "Theater". The Play table contains data about productions. Team table - about the roles of the actors. The Actor table is about actors. Director table - about directors. Table fields, primary and foreign keys can be seen in the figure below (left-click to enlarge).

Example 3. Display a list of actors who play more than one role in one performance and the number of their roles.
Use the JOIN operator 1 time. Use HAVING, GROUP BY.
Clue. The HAVING operator applies to the number of roles counted by the COUNT aggregate function.
LEFT OUTER JOIN
A query with the LEFT OUTER JOIN operator is designed to join tables and display a resulting table in which the data is completely intersected by the condition specified after ON, and is supplemented by records from the first (left) table, even if they do not meet the condition. Records in the left table that do not meet the condition will have a column value from the right table that is NULL (undefined).
Example 4. The database and tables are the same as in example 1.
To obtain a resulting table in which data from two tables completely intersect by condition and are supplemented with all data from the Parts table that does not meet the condition, write the following query:
SELECT PARTS.Part, CATEGORIES.Cat_ID AS Cat, CATEGORIES.Price FROM PARTS LEFT OUTER JOIN CATEGORIES ON PARTS.Cat = CATEGORIES.Cat_ID
The result of the query will be the following table:
| Part | Cat | Price |
| Apartments | 505 | 210,00 |
| Cars | 205 | 160,00 |
| Boards | 10 | 105,00 |
| Cabinets | 30 | 77,00 |
| Books | 160 | NULL |
In the resulting table, unlike the table from example 1, there are Books, but the value of the Price column is NULL, since this record has a category identifier that is not in the Categories table.
RIGHT OUTER JOIN
A query with the RIGHT OUTER JOIN operator is designed to join tables and display a resulting table in which the data is completely intersected by the condition specified after ON, and is supplemented by records from the second (right) table, even if they do not meet the condition. Records in the right table that do not meet the condition will have a column value from the left table that is NULL (undefined).

Example 5.
To obtain the resulting table, in which the data from two tables completely intersect according to the condition and are supplemented with all the data from the Categories table that does not meet the condition, write the following query:
SELECT PARTS.Part, CATEGORIES.Cat_ID AS Cat, CATEGORIES.Price FROM PARTS RIGHT OUTER JOIN CATEGORIES ON PARTS.Cat = CATEGORIES.Cat_ID
The result of the query will be the following table:
| Part | Cat | Price |
| Apartments | 505 | 210,00 |
| Cars | 205 | 160,00 |
| Boards | 10 | 105,00 |
| Cabinets | 30 | 77,00 |
| NULL | 45 | 65,00 |
In the resulting table, unlike the table from example 1, there is a record with category 45 and price 65.00, but the Part column value is NULL, since this record has a category identifier that is not referenced in the Parts table .
FULL OUTER JOIN (full outer join)
A query with the FULL OUTER JOIN operator is designed to join tables and display a resulting table in which the data is completely intersected by the condition specified after ON, and is supplemented by records from the first (left) and second (right) tables, even if they do not meet the condition. Records that do not meet the condition will have columns from the other table that are NULL (undefined).

Example 6. The database and tables are the same as in the previous examples.
To obtain the resulting table, in which the data from the two tables completely intersect by condition and are supplemented with all the data from both the Parts table and the Categories table that do not meet the condition, write the following query:
SELECT PARTS.Part, CATEGORIES.Cat_ID AS Cat, CATEGORIES.Price FROM PARTS FULL OUTER JOIN CATEGORIES ON PARTS.Cat = CATEGORIES.Cat_ID
The result of the query will be the following table:
| Part | Cat | Price |
| Apartments | 505 | 210,00 |
| Cars | 205 | 160,00 |
| Boards | 10 | 105,00 |
| Cabinets | 30 | 77,00 |
| Books | 160 | NULL |
| NULL | 45 | 65,00 |
The resulting table contains records of Books (from the left table) and with category 45 (from the right table), and the first of them has an undefined price (column from the right table), and the second has an undefined part (column from the left table).
Aliases for joined tables
In previous queries, we specified the full names of these tables with the names of the extracted columns from different tables. Such queries look cumbersome: the same word is repeated several times. Is it possible to somehow simplify the design? It turns out that it is possible. To do this, you should use table aliases - their abbreviated names. A nickname can also consist of one letter. Any number of letters in an alias is possible, the main thing is that the request after abbreviation is understandable to you. The general rule is that in the join section of the query, that is, around the word JOIN, you must specify the full table names, and each name must be followed by a table alias.
Example 7. Rewrite the query from Example 1 using aliases for the joined tables.
The request will be as follows:
SELECT P.Part, C.Cat_ID AS Cat, C.Price FROM PARTS P INNER JOIN CATEGORIES C ON P.Cat = C.Cat_ID
The query will return the same thing as the query in example 1, but it is much more compact.
JOIN and joining more than two tables
Relational databases must comply with the requirements of data integrity and non-redundancy, and therefore data about one business process can be contained not only in one, two, but also in three or more tables. In these cases, chains of connected tables are used to analyze data: for example, one (first) table contains a certain quantitative indicator, the second table is connected to the first and third by foreign keys - the data intersects, but only the third table contains a condition, depending on which it may be the quantitative indicator from the first table is derived. And there may be even more tables. Using the SQL JOIN operator, you can join a large number of tables in a single query. In such queries, one join section is followed by another, and each subsequent JOIN joins to the next table the table that was the second in the previous link in the chain. Thus, the SQL query syntax for joining more than two tables is as follows:
SELECT COLUMN_NAMES (1..N) FROM TABLE_NAME_1 JOIN TABLE_NAME_2 ON CONDITION JOIN TABLE_NAME_3 ON CONDITION... JOIN TABLE_NAME_M ON CONDITION
Example 8. The database is the same as in the previous examples. In this example, the Ads table will be added to the Categories and Parts tables, containing data about advertisements published on the portal. Here is a fragment of the Ads table, in which among the records there are records of those advertisements whose publication period expires on 04/02/2018.
| A_Id | Part_ID | Date_start | Date_end | Text |
| 21 | 1 | "2018-02-11" | "2018-04-20" | "I'm selling..." |
| 22 | 1 | "2018-02-11" | "2018-05-12" | "I'm selling..." |
| ... | ... | ... | ... | ... |
| 27 | 1 | "2018-02-11" | "2018-04-02" | "I'm selling..." |
| 28 | 2 | "2018-02-11" | "2018-04-21" | "I'm selling..." |
| 29 | 2 | "2018-02-11" | "2018-04-02" | "I'm selling..." |
| 30 | 3 | "2018-02-11" | "2018-04-22" | "I'm selling..." |
| 31 | 4 | "2018-02-11" | "2018-05-02" | "I'm selling..." |
| 32 | 4 | "2018-02-11" | "2018-04-13" | "I'm selling..." |
| 33 | 3 | "2018-02-11" | "2018-04-12" | "I'm selling..." |
| 34 | 4 | "2018-02-11" | "2018-04-23" | "I'm selling..." |
Let's imagine that today is "2018-04-02", that is, this value takes function CURDATE() - current date. You want to know which categories the advertisements whose publication deadline is today belong to. Category names are only in the CATEGORIES table, and ad expiration dates are only in the ADS table. In the PARTS table - parts of categories (or more simply, subcategories) of published advertisements. But the PARTS table is linked by the foreign key Cat_ID to the CATEGORIES table, and the ADS table is linked by the foreign key Part_ID to the PARTS table. Therefore, we connect three tables in one query and this query can be called a chain with maximum correctness.
The request will be as follows:
The result of the query is a table containing the names of two categories - “Real Estate” and “Transport”:
| Cat_name |
| Real estate |
| Transport |
CROSS JOIN
Using the SQL CROSS JOIN statement in its simplest form - without a join condition - implements the operation Cartesian product in relational algebra. The result of such a join will be the concatenation of each row of the first table with each row of the second table. Tables can be written in a query either through a CROSS JOIN operator or separated by a comma.
Example 9. The database is still the same, the tables are Categories and Parts. Implement the Cartesian product operation of these two tables.
The request will be as follows:
SELECT (*) Categories CROSS JOIN Parts
Or without explicitly specifying CROSS JOIN - separated by commas:
SELECT (*) Categories, Parts
The query will return a table of 5 * 5 = 25 rows, a fragment of which is given below:
| Cat_ID | Cat_name | Price | Part_ID | Part | Cat |
| 10 | Construction materials | 105,00 | 1 | Apartments | 505 |
| 10 | Construction materials | 105,00 | 2 | Cars | 205 |
| 10 | Construction materials | 105,00 | 3 | Boards | 10 |
| 10 | Construction materials | 105,00 | 4 | Cabinets | 30 |
| 10 | Construction materials | 105,00 | 5 | Books | 160 |
| ... | ... | ... | ... | ... | ... |
| 45 | Technique | 65,00 | 1 | Apartments | 505 |
| 45 | Technique | 65,00 | 2 | Cars | 205 |
| 45 | Technique | 65,00 | 3 | Boards | 10 |
| 45 | Technique | 65,00 | 4 | Cabinets | 30 |
| 45 | Technique | 65,00 | 5 | Books | 160 |
As can be seen from the example, if the result of such a request has any value, then it is perhaps a visual value in some cases when there is no need to display structured information, especially even the simplest analytical sample. By the way, you can specify the columns to display from each table, but even then the information value of such a query will not increase.
But for CROSS JOIN you can set a join condition! The result will be completely different. When using the comma operator instead of explicitly specifying CROSS JOIN, the join condition is specified not by the ON word, but by the WHERE word.
Example 10. The same database of the advertisement portal, Categories and Parts tables. Using a cross join, connect tables so that the data completely overlaps according to the condition. The condition is a match between the category identifier in the Categories table and the link to the category in the Parts table.
The request will be as follows:
The query will return the same as the query in example 1:
| Part | Cat | Price |
| Apartments | 505 | 210,00 |
| Cars | 205 | 160,00 |
| Boards | 10 | 105,00 |
| Cabinets | 30 | 77,00 |
And this coincidence is not accidental. A query with a cross join according to the join condition is completely similar to a query with an inner join - INNER JOIN - or, given that the word INNER is optional, just JOIN.
Thus, which query variant to use is a matter of style or even habit of the database specialist. Perhaps a cross join with a condition on two tables can be more compact. But the benefit of a cross join for more than two tables (this is also possible) is highly debatable. In this case, the WHERE conditions of the intersection are listed through the AND word. This design can be cumbersome and difficult to read if there is also a WHERE clause at the end of the query with fetch conditions.
Relational Databases and SQL Language
SQL - Lesson 7. Joining tables (outer join)
So, as a continuation of the last lesson, we need to display all users and the topics they created, if any. If we use the inner join discussed in the last lesson, we will end up with the following: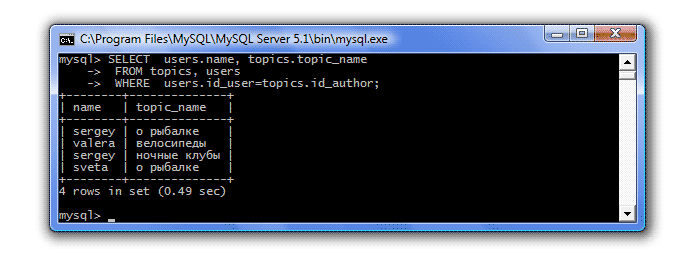
That is, the resulting table contains only those users who created topics. And we need all names to be displayed. To do this, we will slightly change the query:
SELECT users.name, topics.topic_name FROM users LEFT OUTER JOIN topics ON users.id_user=topics.id_author;
And we get the desired result - all users and topics created by them. If the user did not create a topic, but the corresponding column contains a NULL value.

So, we added the keyword to our query - LEFT OUTER JOIN, thereby indicating that all rows should be taken from the table on the left, and changed the keyword WHERE on ON. Except the keyword LEFT OUTER JOIN keyword can be used RIGHT OUTER JOIN. Then all rows from the right table and those associated with them from the left table will be selected. Finally, a full outer join is possible, which will extract all rows from both tables and link those that may be related. The keyword for a full outer join is FULL OUTER JOIN.
Let's change our query from a left-sided join to a right-sided one:

As you can see, now we have all the topics (all rows from the right table), but only the users who created the topics (i.e., only those rows that are associated with the right table are selected from the left table).
Unfortunately, the MySQL DBMS does not support full federation.
Let's summarize this short lesson. The syntax for an outer join is as follows.
Which is executed first - JOIN or GROUP BY? This implicit question didn't occur to me until the answer surfaced in the form of erroneous data returned by my query. Of course, JOIN is executed earlier; it is also written before GROUP BY in queries. But what if I need merge tables after grouping? Let's look at a simple example where this may be required.
Let’s imagine a not very convenient, but very simple accounting system, consisting of two tables: Income- income table and Outlay- table of expenses. Both tables have 3 fields: id(INT), time(DATETIME), sum(INT):
# Income # Outlay id time sum id time sum 1 2014-01-01 00:00:00 100 1 2014-01-02 00:00:00 100 2 2014-01-01 23:59: 59 100 2 2014-01-02 23:59:59 100 3 2014-01-02 00:00:00 500
As you can see, on January 1 we had two sales of 100 rubles each, and on January 2 we had a sale of 500 and two expenses of 100 rubles each.
We combine, aggregate, group
Let's imagine that we are faced with the task of displaying a table of daily income. It's simple, we must add the amounts, grouping by date:
# Sum up income and group them by day SELECT DATE(`income`.`time`) `date`, SUM(`income`.`sum`) `inSum` FROM `Income` `income` GROUP BY DATE(`income` .`time`); # The result of execution is the sum of income by day date inSum 2014-01-01 200 2014-01-02 500
Well, now, opposite each date, I wanted to display the amount of expenses. And this is what I, naive, wrote:
# We combine tables of income and expenses by date, sum up income and expenses, grouping by day # This is NOT necessary to write: SELECT DATE(`income`.`time`) `date`, SUM(`income`.`sum`) `inSum `, SUM(`outlay`.`sum`) `outSum` FROM `Income` `income` LEFT JOIN `Outlay` `outlay` ON DATE(`income`.`time`) = DATE(`outlay`.`time `) GROUP BY DATE(`income`.`time`); # Tree sticks! Profit as of January 2 doubled! date inSum outSum 2014-01-01 200 NULL 2014-01-02 1000(!) 200
As you can see, absolute horror returned in the answer - income doubled as of January 2. As already noted at the beginning of the article, JOIN is executed before GROUP BY, Accordingly, due to the fact that on January 2 we had two expense items, the income items were duplicated when combining the tables, which led to a doubling of income when summed up. Logic dictates that to fix the problem we must merge tables already grouped by date.
Early grouping when joining MySQL tables using a subquery
Within one query, we cannot first group and then link tables, but we can implement delayed join with the result of a nested query, and perform the grouping in it in advance. This is done like this:
# We group the data in the Outlay table in advance, then join it with the Income table SELECT DATE(`income`.`time`) `date`, SUM(`income`.`sum`) `inSum`, `outlayGroupped`.`outSum` FROM `Income` `income` LEFT JOIN (# Our nested query with grouping SELECT SUM(`outlay`.`sum`) `outSum`, DATE(`outlay`.`time`) `outDate` FROM `Outlay` `outlay ` GROUP BY DATE(`outlay`.`time`)) `outlayGroupped` ON DATE(`income`.`time`) = `outlayGroupped`.`outDate` GROUP BY DATE(`income`.`time`); # Of course, the profit is less than last time, but the numbers are correct :) date inSum outSum 2014-01-01 200 NULL 2014-01-02 500 200
Typically, such implicit problems require equally implicit solutions in two cases - when the task is not quite correctly formulated or when the project architecture leaves much to be desired. In this case, of course, the database structure is far-fetched for the sake of an example.
Well, let's not forget that nested queries are always not good, because they are executed separately and independently of external ones. Therefore, when working with some large statistics, do not forget to optimize them and set limits. Better yet, think about yours :)