Как работает sql count. Вычисления в sql
есть запрос вида:
SELECT i.*, COUNT(*) AS currencies, SUM(ig.quantity) AS total, SUM(g.price * ig.quantity) AS price, c.briefly AS cname FROM invoice AS i, invoice_goods AS ig, good g LEFT JOIN currency c ON (c.id = g.currency) WHERE ig.invoice_id = i.id AND g.id = ig.good_id GROUP BY g.currency ORDER BY i.date DESC;
т.е. выбирается список заказов, в котором считаются суммарные стоимости товаров в разных валютах (валюта установлена у товара, столбец cname в результате — название валюты)
нужно в столбце результата currencies получать количество записей с одинаковым i.id , однако, эксперименты с параметрами COUNT() ни к чему не привели — всегда возвращает 1
Вопрос: возможно ли получить истинное значение в столбце currencies ? Т.е. если заказаны товары с ценами в 3х разных валютах, currencies=3 ?
Слишком большие вольности допускает MySQL по отношению к SQL однако. Что например значит i.* в контексте этого селекта? Все колонки таблицы invoice? Так как к ним не применяется никакая групповая функция, то неплохо было бы чтобы они были перечислены в GROUP BY, иначе не совсем ясен принцип группировки строк. Если необходимо получить все товары по всем заказам в разрезе валют, это одно, если необходимо получить все товары сгруппированные по валютам в разрезе каждого заказа, это совсем другое.
Исходя из вашего селекта можно предположить следующую структуру данных:
Таблица invoice:
Таблица invoice_goods:
Таблица goods:
Таблица currency:
Что вернёт ваш текущий селект? По идее он вернёт для каждого заказа N-строк по каждой валюте в которой в этом заказе есть товары. Но из-за того что в group by не указано ничего кроме g.currency, это не очевидно:), более того, колонка c.briefly тоже вносит свою лепту в неявное образование групп. Что же мы имеем в итоге, для каждой уникального сочетания i.*, g.currency и c.briefly будет сформирована группа к строчкам которой будут применены функции SUM и COUNT. То что в результате игры с параметром COUNT у вас выходила всегда 1 означает что в результирующей группе была только одна запись (т.е. группы формируются не так как вам, возможно, требуется, можете описать требования поподробнее?). Из вашего вопроса не ясно, что вы хотели бы узнать - сколько разных валют учавствовало в заказе или сколько заказов было в данной валюте? В первом случае возможны несколько вариантов всё зависит от возможностей mySQL, во втором надо по-другому написать селект выражение.
Слишком большие вольности допускает MySQL по отношению к SQL однако. Что например значит i.* в контексте этого селекта? Все колонки таблицы invoice?
Да, именно. Но большой роли это не играет, т.к. полезных в данном случае среди них (колонок) нет. Пускай i.* будет i.id . Для определённости.
Что вернёт ваш текущий селект? По идее он вернёт для каждого заказа N-строк по каждой валюте в которой в этом заказе есть товары. Но из-за того что в group by не указано ничего кроме g.currency, это не очевидно:),
Именно так.
Вернёт он следующее (в этом примере из i я выбираю только id , а не все столбцы):
| id | currencies | total | price | cname |
|---|---|---|---|---|
| 33 | 1 | 1.00 | 198.00 | BF |
| 33 | 1 | 4.00 | 1548.04 | РУБ |
более того, колонка c.briefly тоже вносит свою лепту в неявное образование групп.
Каким образом? По c.id=g.currency делается соединение таблиц, а группировка по g.currency .
То что в результате игры с параметром COUNT у вас выходила всегда 1 означает что в результирующей группе была только одна запись
Нет, группа строилась из 1й
записи. Насколько я это понял, COUNT() возвращает 1 именно поэтому (ведь столбцы, которые в группе отличаются (правда, кроме столбца валют), создаются аггрегатными функциями).
(т.е. группы формируются не так как вам, возможно, требуется, можете описать требования поподробнее?).
Группы формируются так как надо, каждая группа -- это сумарная стоимость товаров в каждой валюте . Однако, мне, помимо того, нужно посчитать, сколько же элементов в этой группе .
Из вашего вопроса не ясно, что вы хотели бы узнать - сколько разных валют учавствовало в заказе или сколько заказов было в данной валюте?
Да уж, заработался немного. Как раз первое.
dmig[досье]
Под "неявным" участием в образованием группы я подразумеваю, что если колонка не указана в GROUP BY, и при этом НЕ является аргументом групповой функции, то результат селекта будет идентичен тому, как если бы эта колонока БЫЛА указана в GROUP BY. Ваш селект, и селект приведённый ниже выведут абсолютно одинаковый результат (не обращайте внимания на join"ы, я просто привёл их к единому формату записи):
Select i.id id, count(*) currencies, sum(ig.quantity) total, SUM(g.price * ig.quantity) price, c.briefly cname FROM invoice i join invoice_goods ig on (ig.invoice_id = i.id) join good g on (g.id = ig.good_id) LEFT OUTER JOIN currency c ON (c.id = g.currency) group by i.id, c.briefly
Получается что в каждой строке результирующей выборки есть одна, и только одна валюта (если бы это было по другому, то и строк было бы две). О количестве каких элементов в таком случае речь? О пунктах заказа? Тогда ваш селект абсолютно правильный, просто по данной валюте, в данном заказе только один пункт.
Давайте рассмотрим схему данных:
- В одном заказе множество пунктов (строк),так?
- Каждый пункт это товар в справочнике goods, так?
- Каждый товар имеет определённую (и только одну) валюту, это следует из c.id = g.currency, так?
Сколько валют в заказе? Столько сколько в нём пунктов с РАЗНЫМИ валютами.
Складывать g.price * ig.quantity имеет смысл только для пунктов в одной валюте;) (хотя километры с часами, тоже складывать можно:) Так что же вас не устраивает!? Вы утверждаете, что вам надо сколько разных валют учавствовало в заказе
и в таком случае сделать это в рамках этого же селекта без всяческих ухищрений (которые скорее всего не потянет MySQL) не получится;(
Я к сожалению не знаток MySQL. В oracle сделать это одним селектом можно, но поможет ли вам такой совет? Вряд ли;)
# В одном заказе множество пунктов (строк),так?
# Каждый пункт это товар в справочнике goods, так?
# Каждый товар имеет определённую (и только одну) валюту, это следует из c.id = g.currency, так?
Так.
Один заказ: одна запись в таблице invoice, ей соответствуют n(>0) записей в invoice_goods, каждой из которых соответствует 1 запись в таблице goods, запись "валюта" в каждой из которых, в свою очередь, соответствует 1й записи в таблице currency (LEFT JOIN — на случай редактирования справочника валют кривыми руками — таблицы типа MyISAM не поддерживают внешних ключей).
Сколько валют в заказе? Столько сколько в нём пунктов с РАЗНЫМИ валютами.
Да, именно так.
Складывать g.price * ig.quantity имеет смысл только для пунктов в одной валюте;) (хотя километры с часами, тоже складывать можно:)
Именно поэтому делается группировка по id валюты (g.currency).
В oracle сделать это одним селектом можно, но поможет ли вам такой совет?
М.б.
Я немного общался с Oracle, с pl/sql знаком.
Вариант №1.
Select a.*, count(*) over (partition by a.id) currencies from (select i.id id, sum(ig.quantity) total, SUM(g.price * ig.quantity) price, c.briefly cname FROM invoice i join invoice_goods ig on (ig.invoice_id = i.id) join good g on (g.id = ig.good_id) LEFT OUTER JOIN currency c ON (c.id = g.currency) group by i.id, c.briefly) a
Это использует т.н. analytic function. С вероятностью 99% НЕ работает в MySQL.
Вариант №2.
Создаётся функция, countCurrencies например, которая по id заказа возвращает кол-во валют которое в нём учавствовало и тогда:
Select i.id id, countCurrencies(i.id) currencies, sum(ig.quantity) total, SUM(g.price * ig.quantity) price, c.briefly cname FROM invoice i join invoice_goods ig on (ig.invoice_id = i.id) join good g on (g.id = ig.good_id) LEFT OUTER JOIN currency c ON (c.id = g.currency) group by i.id, c.briefly, countCurrencies(i.id)
Может прокатить... но будет вызываться для каждой валюты каждого заказа. Не знаю даёт ли MySQL делать GROUP BY по функции...
Вариант №3
Select i.id id, agr.cnt currencies, sum(ig.quantity) total, SUM(g.price * ig.quantity) price, c.briefly cname FROM invoice i join invoice_goods ig on (ig.invoice_id = i.id) join good g on (g.id = ig.good_id) LEFT OUTER JOIN currency c ON (c.id = g.currency) left outer join (select ii.id, count(distinct gg.currency) cnt from invoice ii, invoce_goods iig, good gg where ii.id = iig.invoice_id and gg.id = iig.good_id group by ii.id) agr on (i.id = agr.id) group by i.id, c.briefly, agr.cnt
Наверное самый правильный... и вполне возможно самый рабочий вариант из всех.
Самый быстрый это Вариант №1. №2 самый неэффективный, т.к. чем больше валют в заказе, тем чаще они считаются.
№3 тоже в принципе не лучший по скорости, но по крайней мере можно положится на кэширование внутри СУБД.
результатом всех трёх селектов будет следующее:
| id | currencies | total | price | cname | ||||
|---|---|---|---|---|---|---|---|---|
| 33 | 2 | 1.00 | 198.00 | BF | ||||
| 33 | 2 | 4.00 | 1548.04 | РУБ | ||||
для одного и того же id цифра в колонке currencies будет всегда одинаковая, это то что вам надо?
Как узнать количество моделей ПК, выпускаемых тем или иным поставщиком? Как определить среднее значение цены на компьютеры, имеющие одинаковые технические характеристики? На эти и многие другие вопросы, связанные с некоторой статистической информацией, можно получить ответы при помощи итоговых (агрегатных) функций . Стандартом предусмотрены следующие агрегатные функции:
Все эти функции возвращают единственное значение. При этом функции COUNT, MIN и MAX применимы к любым типам данных, в то время как SUM и AVG используются только для числовых полей. Разница между функцией COUNT(*) и COUNT(<имя поля>) состоит в том, что вторая при подсчете не учитывает NULL-значения.
Пример. Найти минимальную и максимальную цену на персональные компьютеры:
Пример. Найти имеющееся в наличии количество компьютеров, выпущенных производителем А:
Пример. Если же нас интересует количество различных моделей, выпускаемых производителем А, то запрос можно сформулировать следующим образом (пользуясь тем фактом, что в таблице Product каждая модель записывается один раз):
Пример. Найти количество имеющихся различных моделей, выпускаемых производителем А. Запрос похож на предыдущий, в котором требовалось определить общее число моделей, выпускаемых производителем А. Здесь же требуется найти число различных моделей в таблице PC (т.е. имеющихся в продаже).
Для того, чтобы при получении статистических показателей использовались только уникальные значения, при аргументе агрегатных функций можно использовать параметр DISTINCT . Другой параметр ALL используется по умолчанию и предполагает подсчет всех возвращаемых значений в столбце. Оператор,
Если же нам требуется получить количество моделей ПК, производимых каждым производителем, то потребуется использовать предложение GROUP BY , синтаксически следующего после предложения WHERE .
Предложение GROUP BY
Предложение GROUP BY используется для определения групп выходных строк, к которым могут применяться агрегатные функции (COUNT, MIN, MAX, AVG и SUM) . Если это предложение отсутствует, и используются агрегатные функции, то все столбцы с именами, упомянутыми в SELECT , должны быть включены в агрегатные функции , и эти функции будут применяться ко всему набору строк, которые удовлетворяют предикату запроса. В противном случае все столбцы списка SELECT, не вошедшие в агрегатные функции, должны быть указаны в предложении GROUP BY . В результате чего все выходные строки запроса разбиваются на группы, характеризуемые одинаковыми комбинациями значений в этих столбцах. После этого к каждой группе будут применены агрегатные функции. Следует иметь в виду, что для GROUP BY все значения NULL трактуются как равные, т.е. при группировке по полю, содержащему NULL-значения, все такие строки попадут в одну группу.Если при наличии предложения GROUP BY , в предложении SELECT отсутствуют агрегатные функции , то запрос просто вернет по одной строке из каждой группы. Эту возможность, наряду с ключевым словом DISTINCT, можно использовать для исключения дубликатов строк в результирующем наборе.
Рассмотрим простой пример:
| SELECT model, COUNT(model) AS Qty_model, AVG(price) AS Avg_price FROM PC GROUP BY model; |
В этом запросе для каждой модели ПК определяется их количество и средняя стоимость. Все строки с одинаковыми значениями model (номер модели) образуют группу, и на выходе SELECT вычисляются количество значений и средние значения цены для каждой группы. Результатом выполнения запроса будет следующая таблица:
| model | Qty_model | Avg_price |
| 1121 | 3 | 850.0 |
| 1232 | 4 | 425.0 |
| 1233 | 3 | 843.33333333333337 |
| 1260 | 1 | 350.0 |
Если бы в SELECT присутствовал столбец с датой, то можно было бы вычислять эти показатели для каждой конкретной даты. Для этого нужно добавить дату в качестве группирующего столбца, и тогда агрегатные функции вычислялись бы для каждой комбинации значений (модель−дата).
Существует несколько определенных правил выполнения агрегатных функций :
- Если в результате выполнения запроса не получено ни одной строки (или не одной строки для данной группы), то исходные данные для вычисления любой из агрегатных функций отсутствуют. В этом случае результатом выполнения функций COUNT будет нуль, а результатом всех других функций - NULL.
- Аргумент агрегатной функции не может сам содержать агрегатные функции (функция от функции). Т.е. в одном запросе нельзя, скажем, получить максимум средних значений.
- Результат выполнения функции COUNT есть целое число (INTEGER). Другие агрегатные функции наследуют типы данных обрабатываемых значений.
- Если при выполнении функции SUM был получен результат, превышающий максимальное значение используемого типа данных, возникает ошибка .
Итак, если запрос не содержит предложения GROUP BY , то агрегатные функции , включенные в предложение SELECT , исполняются над всеми результирующими строками запроса. Если запрос содержит предложение GROUP BY , каждый набор строк, который имеет одинаковые значения столбца или группы столбцов, заданных в предложении GROUP BY , составляет группу, и агрегатные функции выполняются для каждой группы отдельно.
Предложение HAVING
Если предложение WHERE определяет предикат для фильтрации строк, то предложение HAVING применяется после группировки для определения аналогичного предиката, фильтрующего группы по значениям агрегатных функций . Это предложение необходимо для проверки значений, которые получены с помощью агрегатной функции не из отдельных строк источника записей, определенного в предложении FROM , а из групп таких строк . Поэтому такая проверка не может содержаться в предложении WHERE .
Чтобы определить количество записей в таблице MySQL, нужно воспользоваться специальной функцией COUNT().
Функция COUNT() возвращает количество записей в таблице, соответствующих заданному критерию.
Функция COUNT(expr) всегда считает только те строки, у которых результатом выражения expr является NOT NULL .
Исключением из этого правила является использование функции COUNT() со звездочкой в качестве аргумента - COUNT(*) . В этом случае считаются все строки, вне зависимости от того, NULL они или NOT NULL .
Например, функция COUNT(*) возвращает общее количество записей в таблице:
SELECT COUNT(*) FROM table_name
Как посчитать количество записей и вывести на экран
Пример PHP+MySQL-кода для подсчета и вывода общего количества строк:
$res = mysql_query("SELECT COUNT(*) FROM table_name") $row = mysql_fetch_row($res); $total = $row; // всего записей echo $total; ?>
Этот пример иллюстрирует самый простой вариант использования функции COUNT() . Но с помощью этой функции можно выплнять и другие задачи.
Указав определенный столбец таблицы в виде параметра, функция COUNT(column_name) возвращает количество записей этого столбца, которые не содержат значение NULL . Записи со значениями NULL игнорируются.
SELECT COUNT(column_name) FROM table_name
Использовать функцию mysql_num_rows() нельзя, потому что для того, чтобы узнать общее количество записей, нужно выполнить запрос SELECT * FROM db , то есть получить все записи, а это нежелательно, поэтому предпочтительнее использовать функцию count .
$result = mysql_query("SELECT COUNT (*) as rec FROM db");
Использование функции COUNT() на примере
Вот еще один пример использования функции COUNT() . Допустим, есть таблица ice_cream с каталогом мороженого, в которой находятся идентификаторы категорий и названия мороженого.
Будем учиться подводить итоги. Нет, это ещё не итоги изучения SQL, а итоги значений столбцов таблиц базы данных. Агрегатные функции SQL действуют в отношении значений столбца с целью получения единого результирующего значения. Наиболее часто применяются агрегатные функции SQL SUM, MIN, MAX, AVG и COUNT. Следует различать два случая применения агрегатных функций. Первый: агрегатные функции используются сами по себе и возвращают одно результирующее значение. Второй: агрегатные функции используются с оператором SQL GROUP BY, то есть с группировкой по полям (столбцам) для получения результирующих значений в каждой группе. Рассмотрим сначала случаи использования агрегатных функций без группировки.
Функция SQL SUM
Функция SQL SUM возвращает сумму значений столбца таблицы базы данных. Она может применяться только к столбцам, значениями которых являются числа. Запросы SQL для получения результирующей суммы начинаются так:
SELECT SUM (ИМЯ_СТОЛБЦА) ...
После этого выражения следует FROM (ИМЯ_ТАБЛИЦЫ), а далее с помощью конструкции WHERE может быть задано условие. Кроме того, перед именем столбца может быть указано DISTINCT, и это означает, что учитываться будут только уникальные значения. По умолчанию же учитываются все значения (для этого можно особо указать не DISTINCT, а ALL, но слово ALL не является обязательным).
Пример 1. Есть база данных фирмы с данными о её подразделениях и сотрудниках. Таблица Staff помимо всего имеет столбец с данными о заработной плате сотрудников. Выборка из таблицы имеет следующий вид (для увеличения картинки щёлкнуть по ней левой кнопкой мыши):
Для получения суммы размеров всех заработных плат используем следующий запрос:
SELECT SUM (Salary) FROM Staff
Этот запрос вернёт значение 287664,63.
А теперь . В упражнениях уже начинаем усложнять задания, приближая их к тем, что встречаются на практике.
Функция SQL MIN
Функция SQL MIN также действует в отношении столбцов, значениями которых являются числа и возвращает минимальное среди всех значений столбца. Эта функция имеет синтаксис аналогичный синтаксису функции SUM.
Пример 3. База данных и таблица - те же, что и в примере 1.
Требуется узнать минимальную заработную плату сотрудников отдела с номером 42. Для этого пишем следующий запрос:
Запрос вернёт значение 10505,90.
И вновь упражнение для самостоятельного решения . В этом и некоторых других упражнениях потребуется уже не только таблица Staff, но и таблица Org, содержащая данные о подразделениях фирмы:

Пример 4. К таблице Staff добавляется таблица Org, содержащая данные о подразделениях фирмы. Вывести минимальное количество лет, проработанных одним сотрудником в отделе, расположенном в Бостоне.
Функция SQL MAX
Аналогично работает и имеет аналогичный синтаксис функция SQL MAX, которая применяется, когда требуется определить максимальное значение среди всех значений столбца.
Пример 5.
Требуется узнать максимальную заработную плату сотрудников отдела с номером 42. Для этого пишем следующий запрос:
Запрос вернёт значение 18352,80
Пришло время упражнения для самостоятельного решения .
Пример 6. Вновь работаем с двумя таблицами - Staff и Org. Вывести название отдела и максимальное значение комиссионных, получаемых одним сотрудником в отделе, относящемуся к группе отделов (Division) Eastern. Использовать JOIN (соединение таблиц) .
Функция SQL AVG
Указанное в отношении синтаксиса для предыдущих описанных функций верно и в отношении функции SQL AVG. Эта функция возвращает среднее значение среди всех значений столбца.
Пример 7. База данных и таблица - те же, что и в предыдущих примерах.
Пусть требуется узнать средний трудовой стаж сотрудников отдела с номером 42. Для этого пишем следующий запрос:
Результатом будет значение 6,33
Пример 8. Работаем с одной таблицей - Staff. Вывести среднюю зарплату сотрудников со стажем от 4 до 6 лет.
Функция SQL COUNT
Функция SQL COUNT возвращает количество записей таблицы базы данных. Если в запросе указать SELECT COUNT(ИМЯ_СТОЛБЦА) ..., то результатом будет количество записей без учёта тех записей, в которых значением столбца является NULL (неопределённое). Если использовать в качестве аргумента звёздочку и начать запрос SELECT COUNT(*) ..., то результатом будет количество всех записей (строк) таблицы.
Пример 9. База данных и таблица - те же, что и в предыдущих примерах.
Требуется узнать число всех сотрудников, которые получают комиссионные. Число сотрудников, у которых значения столбца Comm - не NULL, вернёт следующий запрос:
SELECT COUNT (Comm) FROM Staff
Результатом будет значение 11.
Пример 10. База данных и таблица - те же, что и в предыдущих примерах.
Если требуется узнать общее количество записей в таблице, то применяем запрос со звёздочкой в качестве аргумента функции COUNT:
SELECT COUNT (*) FROM Staff
Результатом будет значение 17.
В следующем упражнении для самостоятельного решения потребуется использовать подзапрос.
Пример 11. Работаем с одной таблицей - Staff. Вывести число сотрудников в отделе планирования (Plains).
Агрегатные функции вместе с SQL GROUP BY (группировкой)
Теперь рассмотрим применение агрегатных функций вместе с оператором SQL GROUP BY. Оператор SQL GROUP BY служит для группировки результирующих значений по столбцам таблицы базы данных. На сайте есть урок, посвящённый отдельно этому оператору .
Пример 12. Есть база данных портала объявлений. В ней есть таблица Ads, содержащая данные об объявлениях, поданных за неделю. Столбец Category содержит данные о больших категориях объявлений (например, Недвижимость), а столбец Parts - о более мелких частях, входящих в категории (например, части Квартиры и Дачи являются частями категории Недвижимость). Столбец Units содержит данные о количестве поданных объявлений, а столбец Money - о денежных суммах, вырученных за подачу объявлений.
| Category | Part | Units | Money |
| Транспорт | Автомашины | 110 | 17600 |
| Недвижимость | Квартиры | 89 | 18690 |
| Недвижимость | Дачи | 57 | 11970 |
| Транспорт | Мотоциклы | 131 | 20960 |
| Стройматериалы | Доски | 68 | 7140 |
| Электротехника | Телевизоры | 127 | 8255 |
| Электротехника | Холодильники | 137 | 8905 |
| Стройматериалы | Регипс | 112 | 11760 |
| Досуг | Книги | 96 | 6240 |
| Недвижимость | Дома | 47 | 9870 |
| Досуг | Музыка | 117 | 7605 |
| Досуг | Игры | 41 | 2665 |
Используя оператор SQL GROUP BY, найти суммы денег, вырученных за подачу объявлений в каждой категории. Пишем следующий запрос:
SELECT Category, SUM (Money) AS Money FROM Ads GROUP BY Category
Пример 13. База данных и таблица - та же, что в предыдущем примере.
Используя оператор SQL GROUP BY, выяснить, в какой части каждой категории было подано наибольшее число объявлений. Пишем следующий запрос:
SELECT Category, Part, MAX (Units) AS Maximum FROM Ads GROUP BY Category
Результатом будет следующая таблица:
Итоговые и индивидуальные значения в одной таблице можно получить объединением результатов запросов с помощью оператора UNION .
Реляционные базы данных и язык SQL
SQL - Урок 8. Группировка записей и функция COUNT()
Давайте вспомним, какие сообщения и в каких темах у нас имеются. Для этого можно воспользоваться привычным запросом: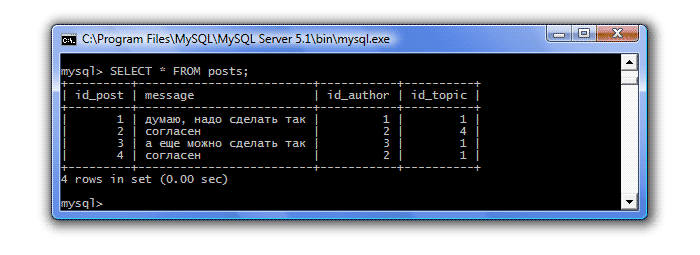
А что, если нам надо лишь узнать сколько сообщений на форуме имеется. Для этого можно воспользоваться встроенной функцией COUNT() . Эта функция подсчитывает число строк. Причем, если в качестве аргумента этой функции выступает *, то подсчитываются все строки таблицы. А если в качестве аргумента указывается имя столбца, то подсчитываются только те строки, которые имеют значение в указанном столбце.
В нашем примере оба аргумента дадут одинаковый результат, т.к. все столбцы таблицы имеют тип NOT NULL. Давайте напишем запрос, используя в качестве аргумента столбец id_topic:
SELECT COUNT(id_topic) FROM posts;
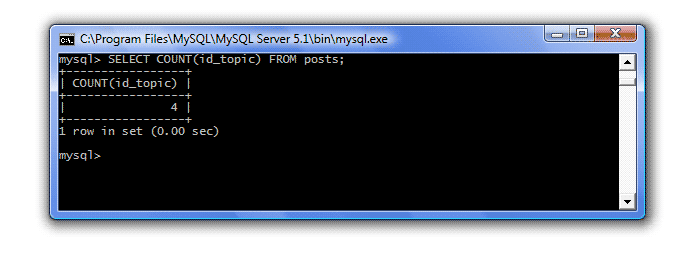
Итак, в наших темах имеется 4 сообщения. Но что, если мы хотим узнать сколько сообщений имеется в каждой теме. Для этого нам понадобится сгруппировать наши сообщения по темам и вычислить для каждой группы количество сообщений. Для группировки в SQL используется оператор GROUP BY . Наш запрос теперь будет выглядеть так:
SELECT id_topic, COUNT(id_topic) FROM posts GROUP BY id_topic;
Оператор GROUP BY указывает СУБД сгруппировать данные по столбцу id_topic (т.е. каждая тема - отдельная группа) и для каждой группы подсчитать количество строк:

Ну вот, в теме с id=1 у нас 3 сообщения, а с id=4 - одно. Кстати, если бы в поле id_topic были возможны отсутствия значений, то такие строки были бы объединены в отдельную группу со значением NULL.
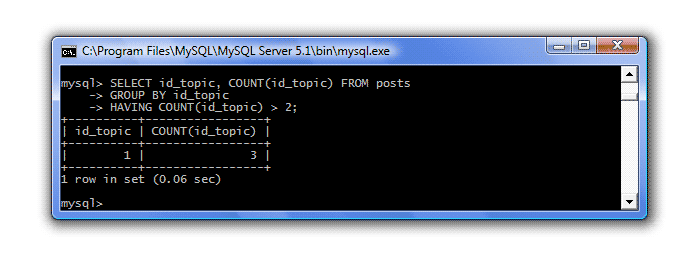
Предположим, что нас интересуют только те группы, в которых больше двух сообщений. В обычном запросе мы указали бы условие с помощью оператора WHERE , но этот оператор умеет работать только со строками, а для групп те же функции выполняет оператор HAVING :
SELECT id_topic, COUNT(id_topic) FROM posts GROUP BY id_topic HAVING COUNT(id_topic) > 2;
В результате имеем:
В уроке 4 мы рассматривали, какие условия можно задавать оператором WHERE , те же условия можно задавать и оператором HAVING , только надо запомнить, что WHERE фильтрует строки, а HAVING - группы.
Итак, сегодня мы узнали, как создавать группы и как подсчитать количество строк в таблице и в группах. Вообще вместе с оператором GROUP BY можно использовать и другие встроенные функции, но их мы будем изучать позже.